标签:坐标 数据 softmax 保存 最好 shu tail eal time
一、简介
二、参考文献
三、R-CNN
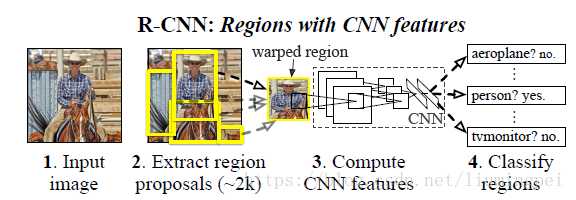
四步:
1、提取region proposals。论文采用的是SS(选择性搜索方法),提取的的proposals数目为2000个。
2、将2000个proposals变形为227*227大小输入AlexNet中得到4096维的特征,形成一个2000*4096维特征矩阵。
3、将提取的特征输入SVM(二分类)进行分类,假设有20类物体,则得到2000*20的得分矩阵,其中行表示2000个候选框,列表示20类目标,值为得分。
4、对每一列进行非极大值抑制(NMS),最终得到的proposals就是最后得到该类别的目标候选框,即从2000个中选择得分高的且不重叠的proposal,最后再进行边界回归优化检测框。
四、Fast R-CNN
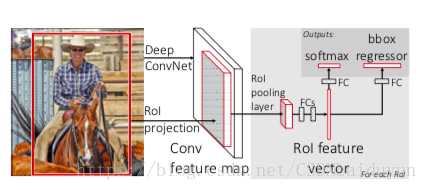
1、采取SS方法提取2000个region proposals,然后将整张图片输入网络得到一个特征图(conv feature map)
2、将2000个region proposal从原图映射到特征图上,映射方法是按比例映射,再利用ROI Pooling得到2000个相同大小的feature map(对应于2000个region proposals在conv feature map上的映射)
3、将最终得到的feature map输入到两个全连接层提取特征向量,再分别用于分类和边界回归。
改进:
1、引入特征图,大大简化了对region proposals提取特征的运算
2、引入roi pooling,较之前的直接变形更完整地保留了原图的信息
3、除了region proposals提取,其它步骤都实现了end-to-end的联合训练
五、Faster R-CNN
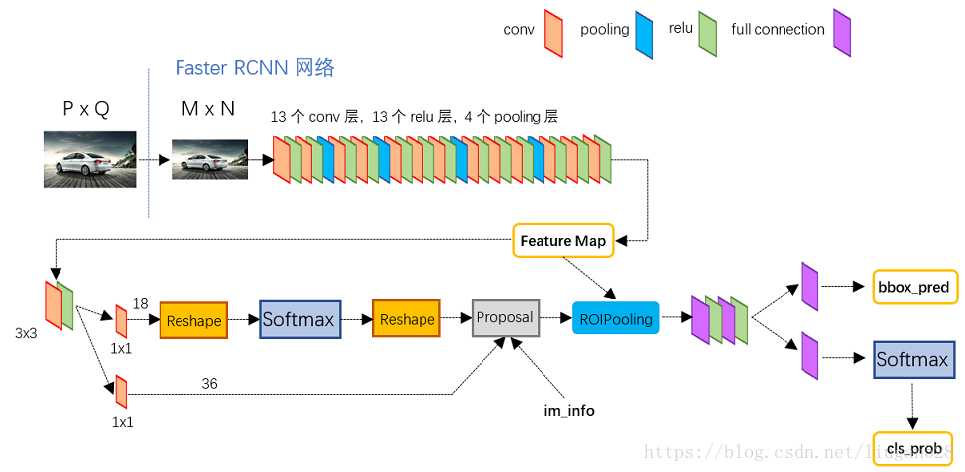
1、将proposals的提取整合到了网络中,即引入了RPN网络,其它的和Fast R-CNN基本一致。
RPN网络:
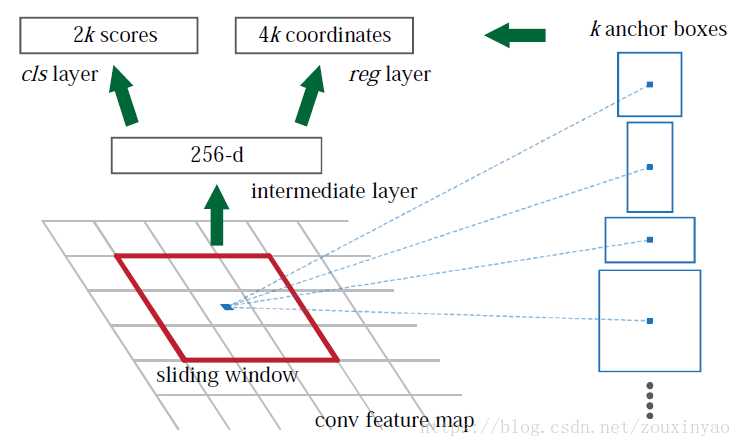
1、RPN网络的作用就是将region proposals的提取整合到了网络中,而且RPN网络和Fast R-CNN网络共用了卷积网络,几乎没有增加计算量。
2、RPN提取候选框的方法是对conv feature map上的每个点为中心取9种不同比例大小的anchors,再按照比例映射到原图中即为提取的region proposals。具体的实现方法如上图,先用一个256维的3*3卷积核以步长为1进行特征提取,这样就可以得到一个256*1的特征向量,将这个256长度的特征向量分别输入两个全连接层,其中一个输出长度为2*9=18表示9个anchors是物体和不是物体的概率(不太懂为什么两个概率都要预测),另一个输出长度为4*9=36表示每个proposals的四个坐标。
3、在得到了概率和bbox的坐标之后映射到原图中得到region proposals,再进行一次NMS得到最终输入Fast R-CNN网络的proposals。
六、一些解释
1、为何要在softmax前后都接一个reshape layer?
其实只是为了便于softmax分类,至于具体原因这就要从caffe的实现形式说起了。在caffe基本数据结构blob中以如下形式保存数据:blob=[batch_size, channel,height,width] 对应至上面的保存bg/fg anchors的矩阵,其在caffe blob中的存储形式为[1, 2x9, H, W]。 而在softmax分类时需要进行fg/bg二分类,所以reshape layer会将其变为[1, 2, 9xH, W]大小, 即单独“腾空”出来一个维度以便softmax分类,之后再reshape回复原状。贴一段caffe softmax_loss_layer.cpp的reshape函数的解释,非常精辟: "Number of labels must match number of predictions; " "e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), " "label count (number of labels) must be N*H*W, " "with integer values in {0, 1, ..., C-1}."; 综上所述,RPN网络中利用anchors和softmax初步提取出foreground anchors作为候选区域。
2、 NMS算法
其实特别简单,就是从一堆proposals中先选出一个得分最高的proposal,然后计算剩余的proposals与这个得分最高proposal的IOU,高于一定的阈值的就直接舍去,这样就剩下了与被选中的proposal重叠区域不多的proposals,再重复这个操作就行。

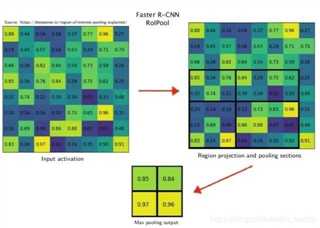
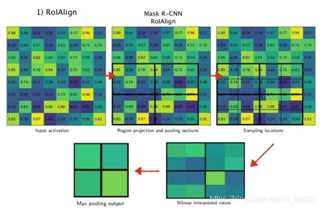
3、ROI pooling与RoIAlign Pooling
roi pooling:每次都向下取整,然后采用max pooling
roialign pooling:不进行取整操作,保留浮点数,最后进行对每个小区域进行采样操作(一般为2*2效果最好),采样点的值由双线性差值计算得到,最后再进行max pooling操作。对小目标的检测效果影响较大。
标签:坐标 数据 softmax 保存 最好 shu tail eal time
原文地址:https://www.cnblogs.com/bupt213/p/10846910.html