标签:scope detail 网络 group step 原来 不可 占位符 测试
https://blog.csdn.net/Cyiano/article/details/75006883
https://blog.csdn.net/transMaple/article/details/78273560
slim库是tensorflow中的一个高层封装,它将原来很多tf中复杂的函数进一步封装,省去了很多重复的参数,以及平时不会考虑到的参数。可以理解为tensorflow的升级版。
import tensorflow as tf import tensorflow.contrib.slim as slim
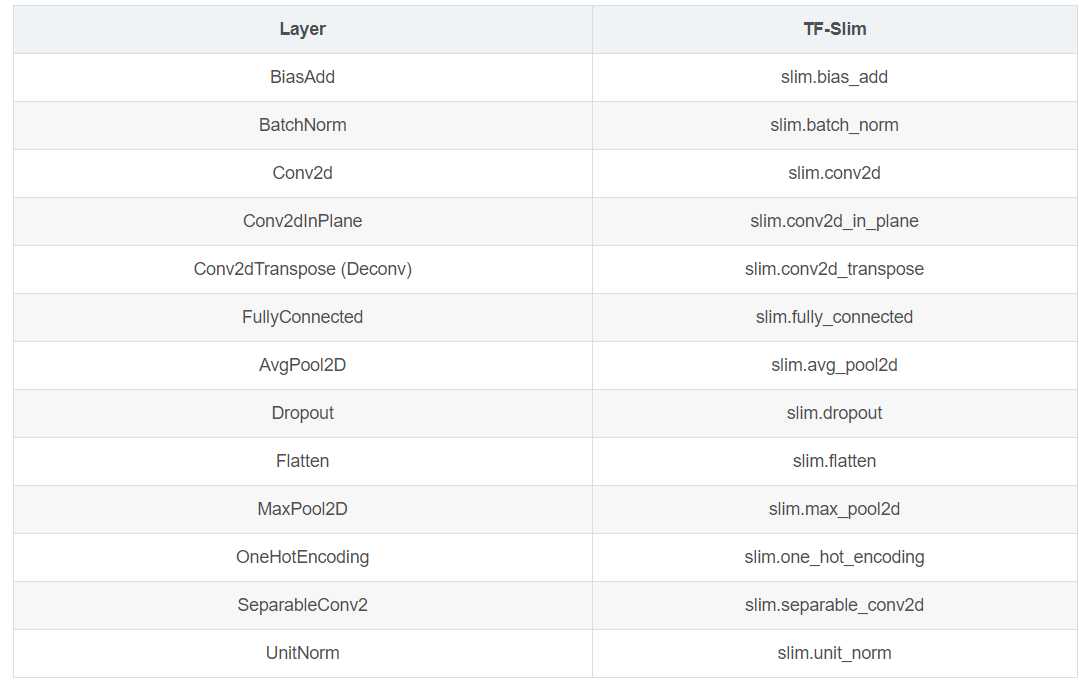
参数:
# 所有的参数如下 @add_arg_scope def convolution2d_in_plane( inputs, kernel_size, stride=1, padding=‘SAME‘, activation_fn=nn.relu, normalizer_fn=None, normalizer_params=None, weights_initializer=initializers.xavier_initializer(), weights_regularizer=None, biases_initializer=init_ops.zeros_initializer(), biases_regularizer=None, reuse=None, variables_collections=None, outputs_collections=None, trainable=True, scope=None):
input = ... net = slim.conv2d(input, 128, [3, 3], scope=‘conv1_1‘) net = slim.max_pool2d(net, kernel_size=[2,2], stride=2, scope=‘pool1‘) # 一般为 (inputs=?, kernel_size=?, stride=?, padding=?, ....) net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope=‘conv3‘) # repeat操作即为重复创建某个layer
slim.conv2d是基于tf.conv2d的进一步封装,省去了很多参数,一般调用方法如下:
net = slim.conv2d(inputs, 256, [3, 3], stride=1, scope=‘conv1_1‘)
前三个参数依次为网络的输入,输出的通道,卷积核大小,stride是做卷积时的步长。除此之外,还有几个经常被用到的参数:
padding : 补零的方式,例如‘SAME‘
activation_fn : 激活函数,默认是nn.relu
normalizer_fn : 正则化函数,默认为None,这里可以设置为batch normalization,函数用slim.batch_norm
normalizer_params : slim.batch_norm中的参数,以字典形式表示
weights_initializer : 权重的初始化器,initializers.xavier_initializer()
weights_regularizer : 权重的正则化器,一般不怎么用到
biases_initializer : 如果之前有batch norm,那么这个及下面一个就不用管了
biases_regularizer :
trainable : 参数是否可训练,默认为True
这个函数更简单了,用法如下:
net = slim.max_pool2d(net, [2, 2], scope=‘pool1‘)
slim.fully_connected(x, 128, scope=‘fc1‘)
slim.arg_scope可以定义一些函数的默认参数值,在scope内,我们重复用到这些函数时可以不用把所有参数都写一遍。
with slim.arg_scope([slim.conv2d, slim.fully_connected], trainable=True, activation_fn=tf.nn.relu, weights_initializer=tf.truncated_normal_initializer(stddev=0.01), weights_regularizer=slim.l2_regularizer(0.0001)): with slim.arg_scope([slim.conv2d], kernel_size=[3, 3], padding=‘SAME‘, normalizer_fn=slim.batch_norm): net = slim.conv2d(net, 64, scope=‘conv1‘)) net = slim.conv2d(net, 128, scope=‘conv2‘)) net = slim.conv2d(net, 256, [5, 5], scope=‘conv3‘))
接下来说我在用slim.batch_norm时踩到的坑。slim.batch_norm里有moving_mean和moving_variance两个量,分别表示每个批次的均值和方差。在训练时还好理解,但在测试时,moving_mean和moving_variance的含义变了。在训练时,有一些语句是必不可少的:
# 定义占位符,X表示网络的输入,Y表示真实值label X = tf.placeholder("float", [None, 224, 224, 3]) Y = tf.placeholder("float", [None, 100]) #调用含batch_norm的resnet网络,其中记得is_training=True logits = model.resnet(X, 100, is_training=True) cross_entropy = -tf.reduce_sum(Y*tf.log(logits)) #训练的op一定要用slim的slim.learning.create_train_op,只用tf.train.MomentumOptimizer.minimize()是不行的 opt = tf.train.MomentumOptimizer(lr_rate, 0.9) train_op = slim.learning.create_train_op(cross_entropy, opt, global_step=global_step) #更新操作,具体含义不是很明白,直接套用即可 update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) if update_ops: updates = tf.group(*update_ops) cross_entropy = control_flow_ops.with_dependencies([updates], cross_entropy)
之后的训练都和往常一样了,导出模型后,在测试阶段调用相同的网络,参数is_training一定要设置成False。
logits = model.resnet(X, 100, is_training=False)
否则,可能会出现这种情况:所有的单个图像分类,最后几乎全被归为同一类。这可能就是训练模式设置反了的问题。
标签:scope detail 网络 group step 原来 不可 占位符 测试
原文地址:https://www.cnblogs.com/fighting929/p/10874868.html