标签:ror span 置信度 dataframe 范围 water isp line base
柱状图用于反映数值变量的集中趋势,用误差线估计变量的差值统计。理解误差线有助于我们准确的获取柱状图反映的信息,因此打算先介绍一下误差线方面的内容,然后介绍一下利用seaborn库绘制柱状图。
误差线源于统计学,表示数据误差(或不确定性)范围,以更准确的方式呈现数据。当label上有一组采样数据时,一般将这组数据的平均值作为该label上标注的值,而用误差线表示该均值可能的误差范围。误差线可以用标准差(standard deviation,SD)、标准误(standard error,SE)和置信区间表示,使用时可选用任意一种表示方法并作相应说明即可。当label上值有一个数据时,则不需要标注误差线。
在实际中,总体的标准差总是未知的,我们一般用样本标准差来估计总体标准差,样本标准差定义为

![]() ?
?
其中为样本均值,则误差线的范围为(
)
当多次进行重复采样时,会得到多组数据,每组数据都有一个平均值,这些平均值间是有差异的,尽管在每组数据量较大时,这个差异会比较小,标准误表示的就是平均值的误差范围。可以对标准误做以下估计
![]()
![]() ?
?
其中为样本的标准差,则误差线的范围为(
)
由于bar上标明的值是样本均值,这里实际上是对样本均值进行区间估计得到的置信区间。一般作区间估计时,需要先获知总体的分布,在实际中我们依据样本的数据量来假设其总体的分布。当为大样本数据情况时(一般数据量大于30),假设样本服从正态分布,当数据量较小时(小于30)时假设样本服从-分布。当然,若已知总体分布时则不需要假设,包括接下来均值及标准差的计算,若已知时则不需要对其进行估计。
当总体为正态分布时,误差线的范围为

![]() ?
?
其中依据区间置信度来计算,C表示置信度(只列出常见的置信度)

![]() ?
?
当总体为-分布时,误差线的范围为

![]() ?
?
其中依据置信度及样本自由度(N-1)来计算,一般查询
-分布得到
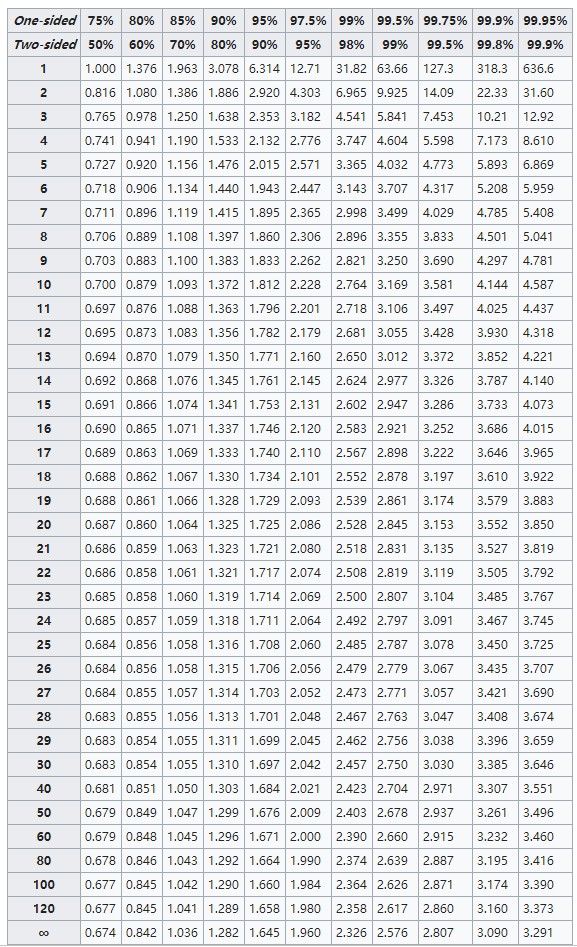
![]() ?
?
这里以均值的置信区间为例,顺便说一下对置信区间的理解。置信区间(置信度为
)是指在重复采集
次时,得到的样本均值有
次可能落在置信区间内,我们不能对置信区间作如下解读:总体均值有
的可能性在置信区间内,这是不对的,在一次采样完成后,按照频率学派的观点,只有“在区间内”、“在区间外”这两种情况,而不能讨论可能性(可能性是贝叶斯学派的观点)。
通过以上的说明,可以获知这样一点内容:当误差线比较“长”时,一般要么是数据离散程度大,要么是数据样本少。
seaborn.barplot()绘图参数的说明为:
>>> a=np.arange(40).reshape(10,4)
df=pd.DataFrame(a,columns=[‘a‘,‘b‘,‘c‘,‘d‘])
df[‘a‘]=[0,4,4,8,8,8,4,12,12,12]
df[‘d‘]=list(‘aabbabbbab‘)
sns.barplot(x=‘a‘,y=‘b‘,data=df,hue=‘d‘)

>>> sns.barplot(x=‘a‘,y=‘b‘,data=df,order=[8,4,12,0]) #控制bar绘制顺序,左图
sns.barplot(x=‘a‘,y=‘b‘,data=df,hue_order=[‘b‘,‘a‘]) #控制bar绘制顺序,右图 
![]() ?
? 
![]() ?
?

![]()

![]() ?
?
返回值:ax,matplotlib.Axes对象
标签:ror span 置信度 dataframe 范围 water isp line base
原文地址:https://www.cnblogs.com/hgz-dm/p/10886309.html