标签:图片 var table 服务 判断 accept people 平均负载 增加
一、查看平均负载:执行 top 或者 uptime 命令,来了解系统的负载情况
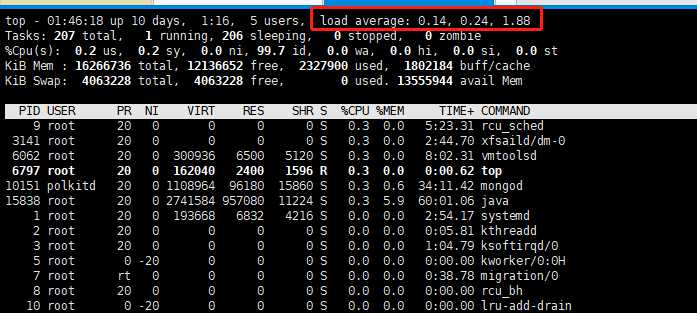

Load Average 依次则是过去 1 分钟、5 分钟、15 分钟的平均负载
二、平均负载:是指单位时间内,系统处于可运行状态(处于 R 状态(Running 或 Runnable)的进程)和不可中断状态(D 状态(Uninterruptible Sleep,也称为也称为 Disk Sleep)的进程)的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系
三、平均负载为多少时合理
1、首先查看服务器CPU 个数,我们可以通过top命令或者从文件/proc/cpuinfo 中读取
2、判断平均负载和cpu个数,大于CPU个数则系统出现负载
3、如果 1分钟,5分钟,15分钟 三个值基本相同,或相差不大,那就说明系统负载很平稳
4、如果1分钟的值远小于15分钟的值,就说明系统最近1分钟的负载在减少,而过去15分钟负载很大
5、如果1分钟的值远大于15分钟的值,就说明最近1分钟负载在增加,如果超过CPU的个数,就意味着发生负载,这时就要分析调查是哪里导致的问题,并要优化
单位时间内cpu繁忙情况的统计
情况1:CPU密集型进程,CPU使用率和平均负载基本一致
情况2:IO密集型进程,平均负载升高,CPU使用率不一定升高
情况3:大量等待CPU的进程调度,平均负载升高,CPU使用率也升高
四、平均负载工具:iostat mpstat pidstat 查找平均负载升高的根源
1、预先安装stress和sysstat包 例如yum install -y sysstat
stress 是一个Linux系统压力测试工具,我们可以用于模拟平均负载升高的场景
stress --cpu 1 --timeout 600 压满一个cpu,执行10分钟
sysstat 用来监控和分析系统的性能,常用两个命令mpstat和pidstat
mpstat 是一个常用的多核cpu性能分析工具,用来查看CPU的性能指标,以及所有CPU的平均指标
pidstat 是一个常用的进程性能分析工具,用来时时查看进程的CPU、内存、I\O以及上下文切换等性能指标
下载:stress
wget -P /home/ http://people.seas.harvard.edu/~apw/stress/stress-1.0.4.tar.gz
依次执行以下指令:
cd /home
tar -zxvf stress-1.0.4.tar.gz
cd stress-1.0.4
./configure
make
make check
make install
make clean
若报错configure: error: no acceptable C compiler found in $PATH
需要安装 sudo yum install gcc-c++
2、场景练习
CPU 密集型进程
首先,我们在第一个终端运行 stress 命令,模拟一个CPU使用100%的场景
stress --cpu 1 --timeout 600
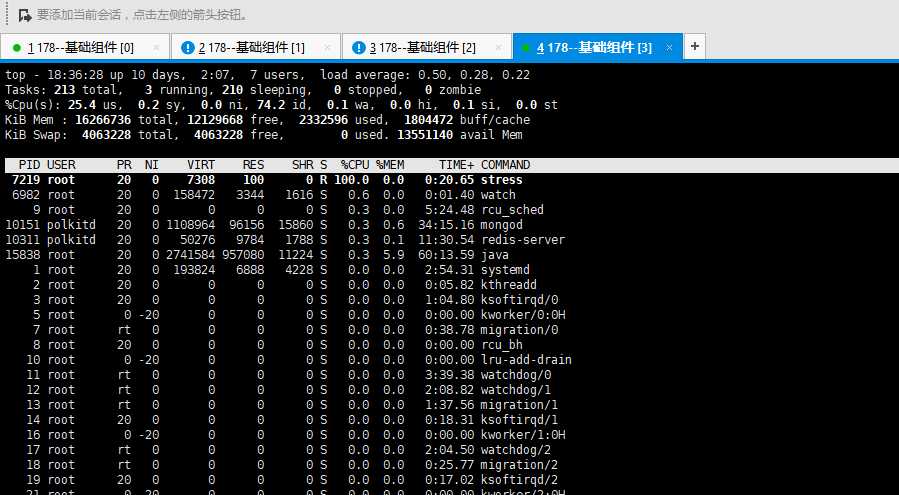
接着,在第二个终端运行 uptime 查看平均负载的变化情况:
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
..., load average: 1.00, 0.75...
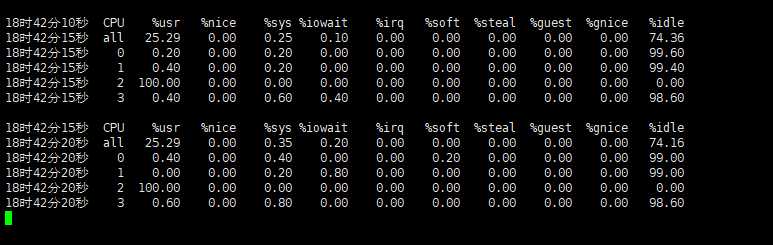
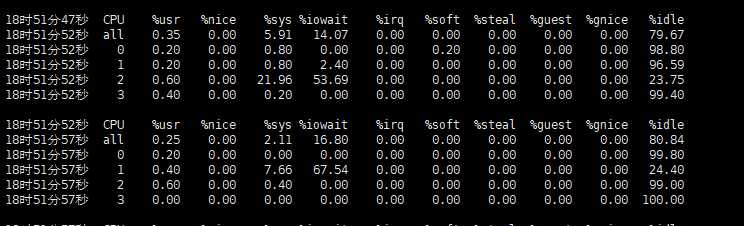
最后,在第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
#mpstat -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
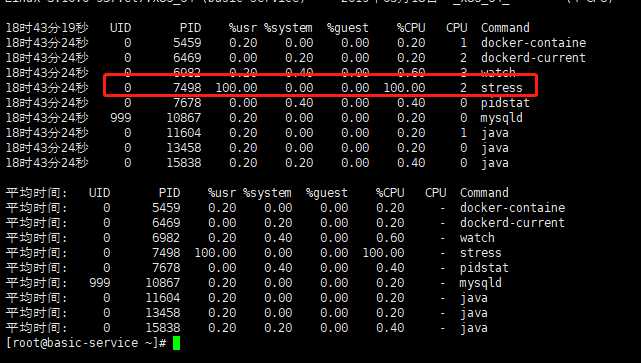
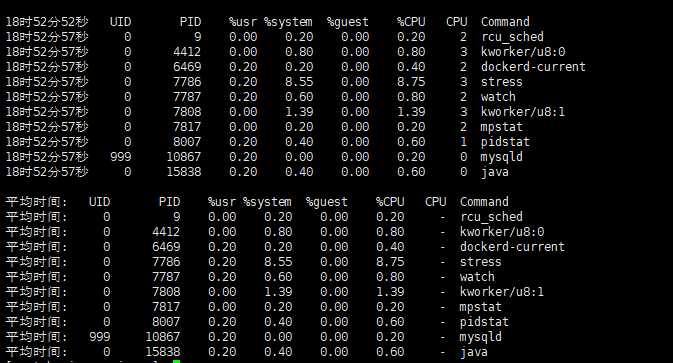
使用pidstat命令查看那个进程占用的cup
I/O密集型进程
首先还是运行 stress 命令,但这次模拟 I/O 压力
stress -i 1 --timeout 600
还是在第二个终端运行 uptime 查看平均负载的变化情况
watch -d uptime
..., load average: 1.06, 0.58, 0.37
然后,第三个终端运行 mpstat 查看 CPU 使用率变化
使用pidstat命令查看那个进程占用的cup
标签:图片 var table 服务 判断 accept people 平均负载 增加
原文地址:https://www.cnblogs.com/dwdw/p/10886722.html