标签:针对 奇数 失败 target man 高并发 sdn rop 假设

最近在学习zookeeper,发现zk真的是一个优秀的中间件。在分布式环境下,可以高效解决数据管理问题。在学习的过程中,要深入zk的工作原理,并根据其特性做一些简单的分布式环境下数据管理工具。本文首先对zk的工作原理和相关概念做一下介绍,然后带大家做一个简单的分布式配置中心。
zookeeper是一个分布式协调框架,主要是解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理、分布式锁等。
# ls /path
#create /path data
#set /path data
#delete /path
#get /path
1)KeeperState.Expired:客户端和服务器在ticktime的时间周期内,是要发送心跳通知的。这是租约协议的一个实现。客户端发送request,告诉服务器其上一个租约时间,服务器收到这个请求后,告诉客户端其下一个租约时间是哪个时间点。当客户端时间戳达到最后一个租约时间,而没有收到服务器发来的任何新租约时间,即认为自己下线(此后客户端会废弃这次连接,并试图重新建立连接)。这个过期状态就是Expired状态
2)KeeperState.Disconnected:就像上面那个状态所述,当客户端断开一个连接(可能是租约期满,也可能是客户端主动断开)这是客户端和服务器的连接就是Disconnected状态
3)KeeperState.SyncConnected:一旦客户端和服务器的某一个节点建立连接(注意,虽然集群有多个节点,但是客户端一次连接到一个节点就行了),并完成一次version、zxid的同步,这时的客户端和服务器的连接状态就是SyncConnected
4)KeeperState.AuthFailed:ookeeper客户端进行连接认证失败时,发生该状态
文件系统 + 监听机制
同一个目录下文件名称不能重复,同样zookeeper也是这样的,zookeeper中统一叫作znode。znode节点可以包含子znode,也可以同时包含数据。znode只适合存储非常小的数据,不能超过1M,最好都小于1K。
临时节点(EPHEMERAL):客户端关闭zk连接后清除
永久节点(persistent):持久化节点,除非客户端主动删除
有编号节点(Persistent_sequential):自动增加顺序编号的znode持久化节点
临时有编号(Ephemral_ sequential):临时自动编号设置,znode节点编号会自动增加,但是会客户端连接断开而消失。分布式锁用的是这个类型的节点。
注:EPHEMERAL 临时类型的节点不能有子节点,对于zk来说,有几个节点数据就会存储几份。
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节 点增加删除)时,zookeeper会通知客户端。
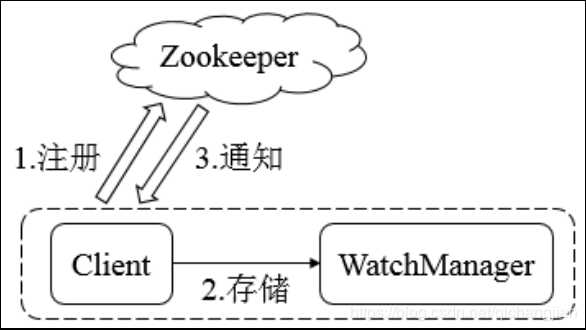
1、客户端启动时向zookeeper服务器注册信息
2、客户端启动同时注册一系列的Watcher类型的监听器到本地的WatchManager中
3、zookeeper服务器中节点发生变化后,触发watcher事件后通知给客户端,客户端线程从WatcherManager中取出对应的Watcher对象来执行回调逻辑。
EventType.NodeCreated:当znode节点被创建时,该事件被触发。
EventType.NodeChildrenChanged:当znode节点的直接子节点被创建、被删除、子节点数据发生变更时,该事件被触发。
EventType.NodeDataChanged:当znode节点的数据发生变更时,该事件被触发。
EventType.NodeDeleted:当znode节点被删除时,该事件被触发。
EventType.None:当zookeeper客户端的连接状态发生变更时,即KeeperState.Expired、KeeperState.Disconnected、KeeperState.SyncConnected、KeeperState.AuthFailed状态切换时,描述的事件类型为EventType.None。
LOOKING:当前server不知道leader是谁,正在选举
LEADING:当前server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前server是follower
ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。
ZAB 协议作用:解决分布式数据管理一致性。
ZAB 协议定义:ZAB 协议是为分布式协调服务 Zookeeper 专门设计的一种支持 崩溃恢复 和 消息广播 协议。
基于该协议,Zookeeper 实现了一种 主备模式 的系统架构来保持集群中各个副本之间数据一致性。
zookeeper集群采用主从(leader-follower)模式保证服务高可用。leader节点可读可写,follower节点只读,这种模式就需要保证leader节点和follower节点的数据一致性。对于客户端发送的写请求,全部由 Leader 接收,Leader 将请求封装成一个事务 Proposal,将其发送给所有 Follwer ,然后,根据所有 Follwer 的反馈,如果超过半数成功响应,则执行 commit 操作(先提交自己,再发送 commit 给所有 Follwer)。
注:上述中有一个概念:两阶段提交过程(分布式系统中数据一致性经常会涉及到的方案)。follower节点是可以处理写请求的,会转发给leader节点。leader节点通过消息广播(二阶段提交)同步写操作到follower节点,保证数据一致性。
zookeeper中每个事务都对应一个ZXID(全局的、唯一的、顺序的)。ZXID 是一个 64 位的数字,其中低 32 位可以看作是一个简单的递增的计数器,针对客户端的每一个事务请求,Leader 都会产生一个新的事务 Proposal 并对该计数器进行 + 1 操作。而高 32 位则代表了 Leader 服务器上取出本地日志中最大事务 Proposal 的 ZXID,并从该 ZXID 中解析出对应的 epoch 值,然后再对这个值加一。
即如果在消息广播的过程中,leader死掉了,如何保证数据的一致性问题。
假设两种异常情况:
1、一个事务在 Leader 上提交了,并且过半的 Folower 都响应 Ack 了,但是 Leader 在 Commit 消息发出之前挂了。
2、假设一个事务在 Leader 提出之后,Leader 挂了。
考虑到上述两种异常情况,Zab 协议崩溃恢复要求满足以下两个要求:
1)确保已经被 Leader 提交的 Proposal 必须最终被所有的 Follower 服务器提交。
2)确保丢弃已经被 Leader 提出的但是没有被提交的 Proposal。
崩溃恢复主要包含:leader选举 和 数据恢复。
leader选举:
1、要求 可用节点数量 > 总节点数量/2 。注意 是 > , 不是 ≥。
2、新选举出来的 Leader 不能包含未提交的 Proposal(新选举的 Leader 必须都是已经提交了 Proposal 的 Follower 服务器节点) 、新选举的 Leader 节点中含有最大的 zxid(可以避免 Leader 服务器检查 Proposal 的提交和丢弃工作。如果zxid相同,选择server_id【zoo.cfg中的myid】最大的。)
数据恢复:
1、上面讲过了ZXID的高 32 位代表了每代 Leader 的唯一性,低 32 代表了每代 Leader 中事务的唯一性。同时,也能让 Follwer 通过高 32 位识别不同的 Leader。简化了数据恢复流程。
2、基于这样的策略:当 Follower 链接上 Leader 之后,Leader 服务器会根据自己服务器上最后被提交的 ZXID 和 Follower 上的 ZXID 进行比对,比对结果要么回滚,要么和 Leader 同步。
集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的master节点,导致原有的集群出现多个master节点的情况。
只要我们清楚集群leader选举的要求(可用节点数量 > 总节点数量/2 。注意 是 > , 不是 ≥),我相信很容易明白奇数节点集群相比偶数节点的集群有更大的优势。
1、发生脑裂(分成2个小集群)的情况下,奇数节点的集群总会有一个小集群满足可用节点数量 > 总节点数量/2,所以zookeeper集群总能选取出leader。
2、在容错能力相同的情况下,奇数集群更节省资源。还是要清楚leader选举的要求哈,举个列子:3个节点的集群,如果集群可以正常工作(即leader选举成功),至少需要2个节点是正常的;4个节点的集群,如果集群可以正常工作(即leader选举成功),至少需要3个节点是正常的。那么3个节点的集群和4个节点的集群都有一个节点宕机的容错能力。很明显,在容错能力相同的情况下,奇数节点的集群更节省资源。
在分布式系统领域有个著名的 CAP定理(C- 数据一致性;A-服务可用性;P-服务对网络分区故障的容错性,这三个特性在任何分布式系统中不能同时满足,最多同时满足两个)。
zookeeper基于CP,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就 是在极端环境下,zookeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。至于zookeeper为啥不能保证服务的高可用,大家可以想一下发生脑裂后无法选取leader、选取leader过程中丢弃某些请求。当网络出现故障时,剩余zk集群server会发起投票选举新的leader,但是此过程会持续30~120s,此过程对于高并发来说十分漫长,会导致整个注册服务的瘫痪,这是不可容忍的。
Eureka基于AP,不会有类似于ZooKeeper的选举leader的过程,采用的是Peer to Peer 对等通信,没有leader/follower的说法,每个peer都是对等的;客户端请求会自动切换 到新的Eureka节点;当宕机的服务器重新恢复后,Eureka会再次将其纳入到服务器集群管理之中。当Eureka节点接受客户端请求时,所有的操作都会在节点间进行复制(replicate To Peer)操作,将请求复制到该 Eureka Server 当前所知的其它所有节点中。至于为啥Eureka不能保证数据一致性,源于Eureka的自我保护机制:如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
1. Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务 。
2. Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用) 。
3. 当网络稳定时,当前实例新的注册信息会被同步到其它节点中。
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
以上是对zookeeper的工作原理和相关概念的一些整理,希望能对大家认识zookeeper有所帮助。下一篇文章开始基于zookeeper做一个简单的分布式配置中心,敬请期待!!!
https://blog.csdn.net/pml18710973036/article/details/64121522
https://www.cnblogs.com/stateis0/p/9062133.html
https://www.jianshu.com/p/2bceacd60b8a
标签:针对 奇数 失败 target man 高并发 sdn rop 假设
原文地址:https://www.cnblogs.com/hujunzheng/p/10887937.html