标签:ros free reads -o finalize sof change int led


These instructions for getting started with OpenMP are repeated in Project 0. They are included here for those students who wish to program with OpenMP now.
Your first task is to set-up Vagrant on your machine if you have not already done so. Vagrant allows you to quickly bring up a virtual machine, which will behave the same way on your computer, the TA‘s computer, other students‘ computers, and on the Udacity site. Simply go to the Vagrant website and download the latest version.
Next, you should make a folder for the projects for this class and download the Vagrantfile for the course into it. From the terminal, change to the appropriate working directory and then run
mkdir hpc-projects cd hpc-projects vagrant box add hashicorp/precise64 (If you are asked to choose an option, choose ‘virtualbox‘) (-O is an uppercase ‘O‘ not the number 0) curl -O https://s3.amazonaws.com/content.udacity-data.com/courses/gt-cse6220/resources/Vagrantfile
To test vagrant run
vagrant up
which will boot the machine. To connect to it, run
From within this ssh session,
cd /vagrant
will bring to the folder on the host machine that contain the Vagrantfile. You can confirm this with the command ls. These folders are synced.
Next, you will use git to obtain this README and the starter code for this assignment. Run
https://github.gatech.edu/omscse6220/lab0.git
We will be using OpenMP for shared memory applications in this course. (CilkPlus is preferable but those primitives are only supported on the bleeding edge versions of gcc. Patience, friends...)
You are now ready to attempt the program examples given in the slide presentations and tutorials.
Student Comment: If you‘re running a *buntu derivative or any Debian-based distro, be sure and grab the latest Vagrant .deb from the website and not from the Ubuntu Universe PPA. For whatever reason, the PPA is years behind.
https://blog.csdn.net/fjh658/article/details/79595702
=> clang-omp 找不到iostream。。。原生clang也没有-fopenmp选项,即便安装了libomp
=> g++-8可以!
#include <omp.h> #include <iostream> using namespace std; int main () { omp_set_num_threads (16); // OPTIONAL — Can also use // OMP_NUM_THREADS environment variable #pragma omp parallel num_threads(8) // Restrict team size locally { cout<<("hello, world!\n")<<endl; // Execute in parallel } // Implicit barrier/join return 0; }
输出:
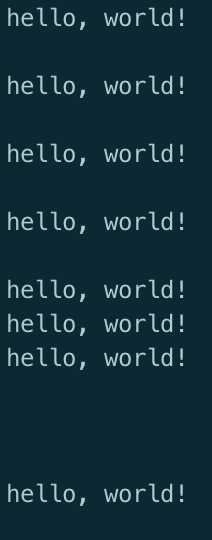
endl不是同时输出的,说明确实并行了

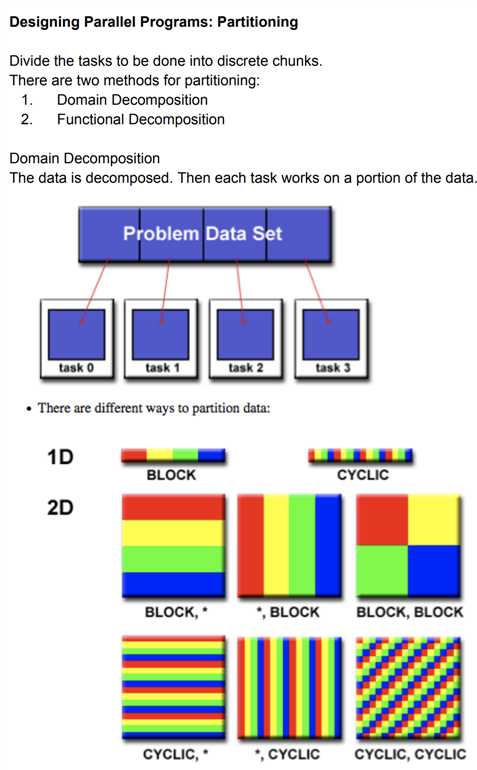
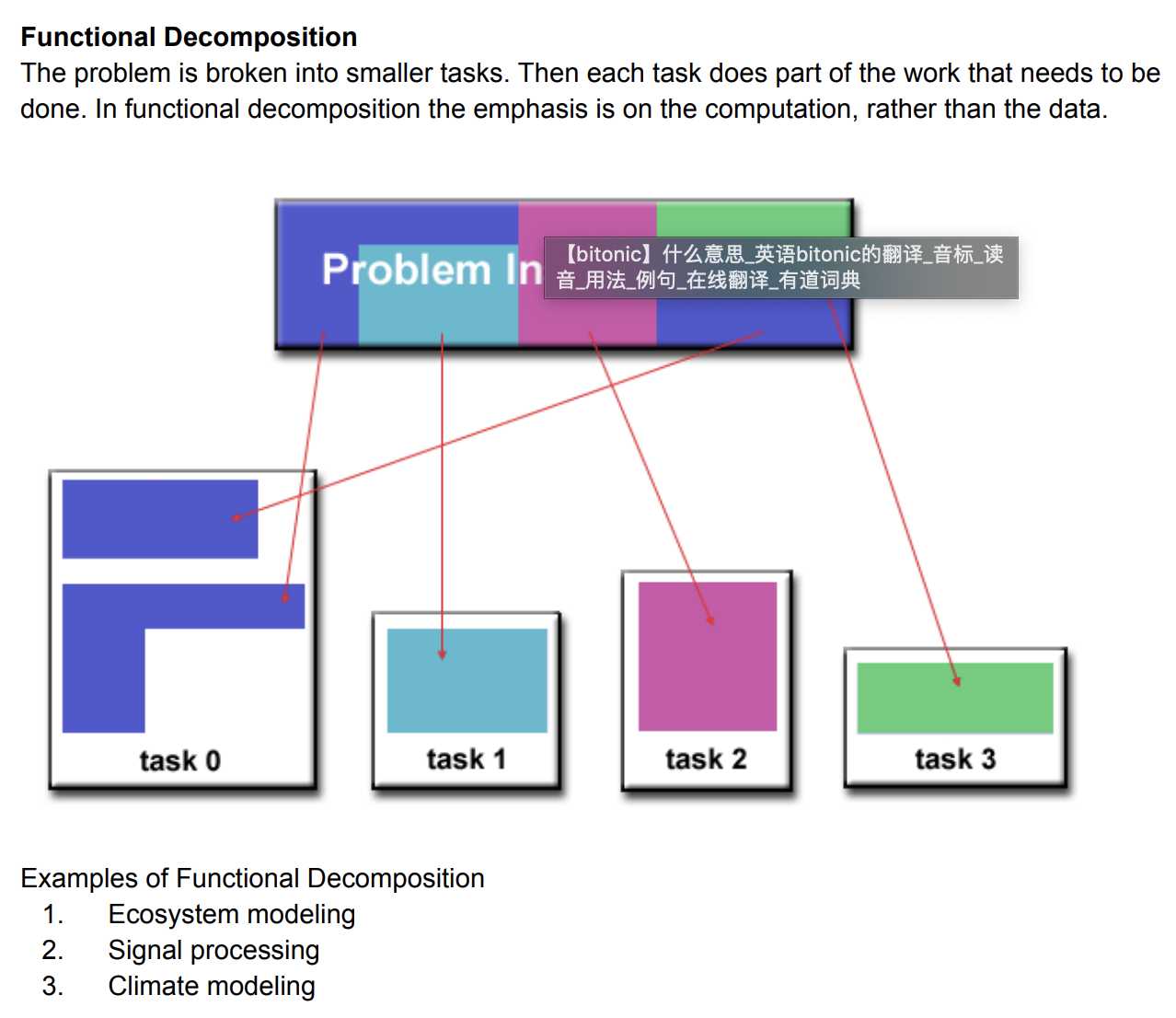

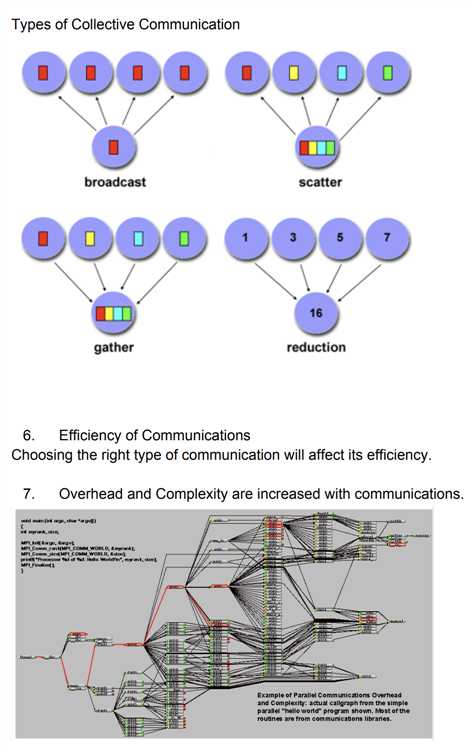


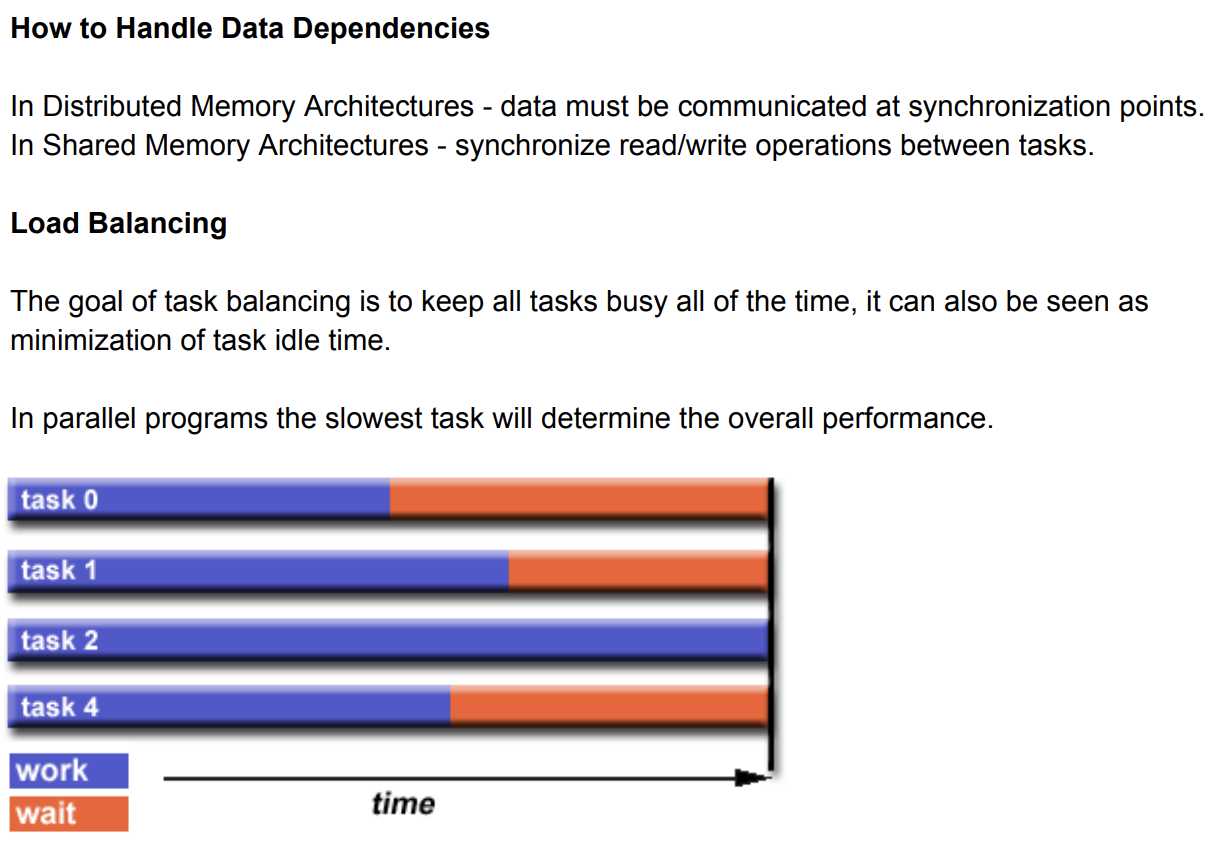



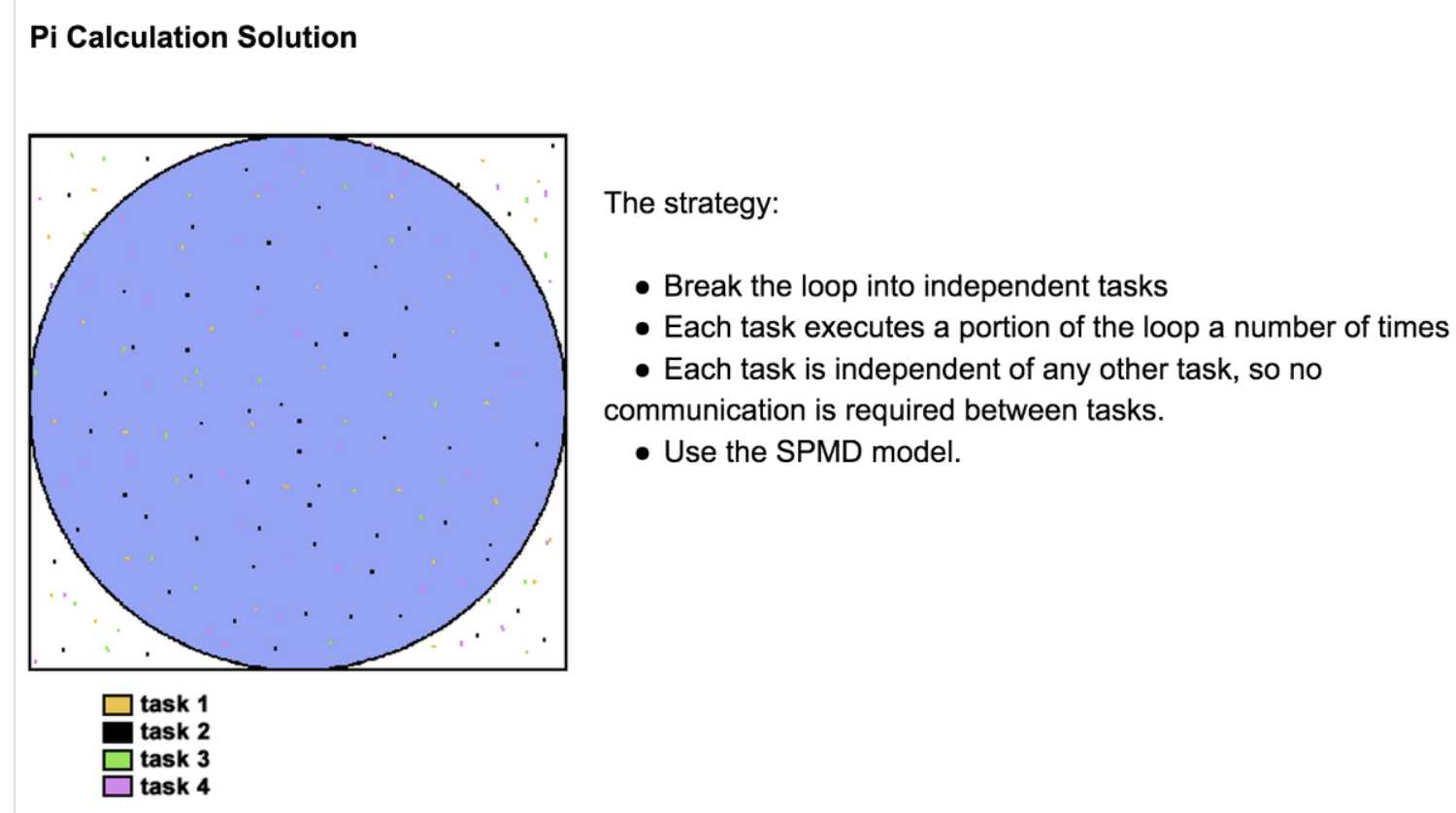
To gain a quick understanding of parallel programming the student may wish to read:
“Introduction to Parallel Computing”
If the student is confident of their programming skills, they should feel free to skip this tutorial.
The course notes for the tutorial: Introduction to Parallel Computing Course Notes
Additional reference to Learning Parallel Programming: Engineering Parallel Software





The C version of the program can be found at:
/********************************************************************** * FILE: mpi_pi_reduce.c * OTHER FILES: dboard.c * DESCRIPTION: * MPI pi Calculation Example - C Version * Collective Communication example: * This program calculates pi using a "dartboard" algorithm. See * Fox et al.(1988) Solving Problems on Concurrent Processors, vol.1 * page 207. All processes contribute to the calculation, with the * master averaging the values for pi. This version uses mpc_reduce to * collect results * AUTHOR: Blaise Barney. Adapted from Ros Leibensperger, Cornell Theory * Center. Converted to MPI: George L. Gusciora, MHPCC (1/95) * LAST REVISED: 06/13/13 Blaise Barney **********************************************************************/ #include "mpi.h" #include <stdio.h> #include <stdlib.h> void srandom (unsigned seed); double dboard (int darts); #define DARTS 50000 /* number of throws at dartboard */ #define ROUNDS 100 /* number of times "darts" is iterated */ #define MASTER 0 /* task ID of master task */ int main (int argc, char *argv[]) { double homepi, /* value of pi calculated by current task */ pisum, /* sum of tasks‘ pi values */ pi, /* average of pi after "darts" is thrown */ avepi; /* average pi value for all iterations */ int taskid, /* task ID - also used as seed number */ numtasks, /* number of tasks */ rc, /* return code */ i; MPI_Status status; /* Obtain number of tasks and task ID */ MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numtasks); MPI_Comm_rank(MPI_COMM_WORLD,&taskid); printf ("MPI task %d has started...\n", taskid); /* Set seed for random number generator equal to task ID */ srandom (taskid); avepi = 0; for (i = 0; i < ROUNDS; i++) { /* All tasks calculate pi using dartboard algorithm */ homepi = dboard(DARTS); /* Use MPI_Reduce to sum values of homepi across all tasks * Master will store the accumulated value in pisum * - homepi is the send buffer * - pisum is the receive buffer (used by the receiving task only) * - the size of the message is sizeof(double) * - MASTER is the task that will receive the result of the reduction * operation * - MPI_SUM is a pre-defined reduction function (double-precision * floating-point vector addition). Must be declared extern. * - MPI_COMM_WORLD is the group of tasks that will participate. */ rc = MPI_Reduce(&homepi, &pisum, 1, MPI_DOUBLE, MPI_SUM, MASTER, MPI_COMM_WORLD); if (rc != MPI_SUCCESS) printf("%d: failure on mpc_reduce\n", taskid); /* Master computes average for this iteration and all iterations */ if (taskid == MASTER) { pi = pisum/numtasks; avepi = ((avepi * i) + pi)/(i + 1); printf(" After %8d throws, average value of pi = %10.8f\n", (DARTS * (i + 1)),avepi); } } if (taskid == MASTER) printf ("\nReal value of PI: 3.1415926535897 \n"); MPI_Finalize(); return 0; } /************************************************************************** * subroutine dboard * DESCRIPTION: * Used in pi calculation example codes. * See mpi_pi_send.c and mpi_pi_reduce.c * Throw darts at board. Done by generating random numbers * between 0 and 1 and converting them to values for x and y * coordinates and then testing to see if they "land" in * the circle." If so, score is incremented. After throwing the * specified number of darts, pi is calculated. The computed value * of pi is returned as the value of this function, dboard. * * Explanation of constants and variables used in this function: * darts = number of throws at dartboard * score = number of darts that hit circle * n = index variable * r = random number scaled between 0 and 1 * x_coord = x coordinate, between -1 and 1 * x_sqr = square of x coordinate * y_coord = y coordinate, between -1 and 1 * y_sqr = square of y coordinate * pi = computed value of pi ****************************************************************************/ double dboard(int darts) { #define sqr(x) ((x)*(x)) long random(void); double x_coord, y_coord, pi, r; int score, n; unsigned int cconst; /* must be 4-bytes in size */ /************************************************************************* * The cconst variable must be 4 bytes. We check this and bail if it is * not the right size ************************************************************************/ if (sizeof(cconst) != 4) { printf("Wrong data size for cconst variable in dboard routine!\n"); printf("See comments in source file. Quitting.\n"); exit(1); } /* 2 bit shifted to MAX_RAND later used to scale random number between 0 and 1 */ cconst = 2 << (31 - 1); score = 0; /* "throw darts at board" */ for (n = 1; n <= darts; n++) { /* generate random numbers for x and y coordinates */ r = (double)random()/cconst; x_coord = (2.0 * r) - 1.0; r = (double)random()/cconst; y_coord = (2.0 * r) - 1.0; /* if dart lands in circle, increment score */ if ((sqr(x_coord) + sqr(y_coord)) <= 1.0) score++; } /* calculate pi */ pi = 4.0 * (double)score/(double)darts; return(pi); }

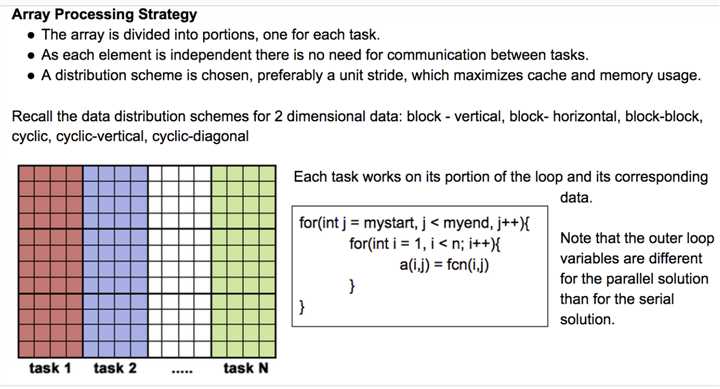

/****************************************************************************** * FILE: mpi_array.c * DESCRIPTION: * MPI Example - Array Assignment - C Version * This program demonstrates a simple data decomposition. The master task * first initializes an array and then distributes an equal portion that * array to the other tasks. After the other tasks receive their portion * of the array, they perform an addition operation to each array element. * They also maintain a sum for their portion of the array. The master task * does likewise with its portion of the array. As each of the non-master * tasks finish, they send their updated portion of the array to the master. * An MPI collective communication call is used to collect the sums * maintained by each task. Finally, the master task displays selected * parts of the final array and the global sum of all array elements. * NOTE: the number of MPI tasks must be evenly divided by 4. * AUTHOR: Blaise Barney * LAST REVISED: 04/13/05 ****************************************************************************/ #include "mpi.h" #include <stdio.h> #include <stdlib.h> #define ARRAYSIZE 16000000 #define MASTER 0 float data[ARRAYSIZE]; int main (int argc, char *argv[]) { int numtasks, taskid, rc, dest, offset, i, j, tag1, tag2, source, chunksize; float mysum, sum; float update(int myoffset, int chunk, int myid); MPI_Status status; /***** Initializations *****/ MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numtasks); if (numtasks % 4 != 0) { printf("Quitting. Number of MPI tasks must be divisible by 4.\n"); MPI_Abort(MPI_COMM_WORLD, rc); exit(0); } MPI_Comm_rank(MPI_COMM_WORLD,&taskid); printf ("MPI task %d has started...\n", taskid); chunksize = (ARRAYSIZE / numtasks); tag2 = 1; tag1 = 2; /***** Master task only ******/ if (taskid == MASTER){ /* Initialize the array */ sum = 0; for(i=0; i<ARRAYSIZE; i++) { data[i] = i * 1.0; sum = sum + data[i]; } printf("Initialized array sum = %e\n",sum); /* Send each task its portion of the array - master keeps 1st part */ offset = chunksize; for (dest=1; dest<numtasks; dest++) { MPI_Send(&offset, 1, MPI_INT, dest, tag1, MPI_COMM_WORLD); MPI_Send(&data[offset], chunksize, MPI_FLOAT, dest, tag2, MPI_COMM_WORLD); printf("Sent %d elements to task %d offset= %d\n",chunksize,dest,offset); offset = offset + chunksize; } /* Master does its part of the work */ offset = 0; mysum = update(offset, chunksize, taskid); /* Wait to receive results from each task */ for (i=1; i<numtasks; i++) { source = i; MPI_Recv(&offset, 1, MPI_INT, source, tag1, MPI_COMM_WORLD, &status); MPI_Recv(&data[offset], chunksize, MPI_FLOAT, source, tag2, MPI_COMM_WORLD, &status); } /* Get final sum and print sample results */ MPI_Reduce(&mysum, &sum, 1, MPI_FLOAT, MPI_SUM, MASTER, MPI_COMM_WORLD); printf("Sample results: \n"); offset = 0; for (i=0; i<numtasks; i++) { for (j=0; j<5; j++) printf(" %e",data[offset+j]); printf("\n"); offset = offset + chunksize; } printf("*** Final sum= %e ***\n",sum); } /* end of master section */ /***** Non-master tasks only *****/ if (taskid > MASTER) { /* Receive my portion of array from the master task */ source = MASTER; MPI_Recv(&offset, 1, MPI_INT, source, tag1, MPI_COMM_WORLD, &status); MPI_Recv(&data[offset], chunksize, MPI_FLOAT, source, tag2, MPI_COMM_WORLD, &status); mysum = update(offset, chunksize, taskid); /* Send my results back to the master task */ dest = MASTER; MPI_Send(&offset, 1, MPI_INT, dest, tag1, MPI_COMM_WORLD); MPI_Send(&data[offset], chunksize, MPI_FLOAT, MASTER, tag2, MPI_COMM_WORLD); MPI_Reduce(&mysum, &sum, 1, MPI_FLOAT, MPI_SUM, MASTER, MPI_COMM_WORLD); } /* end of non-master */ MPI_Finalize(); } /* end of main */ float update(int myoffset, int chunk, int myid) { int i; float mysum; /* Perform addition to each of my array elements and keep my sum */ mysum = 0; for(i=myoffset; i < myoffset + chunk; i++) { data[i] = data[i] + i * 1.0; mysum = mysum + data[i]; } printf("Task %d mysum = %e\n",myid,mysum); return(mysum); }



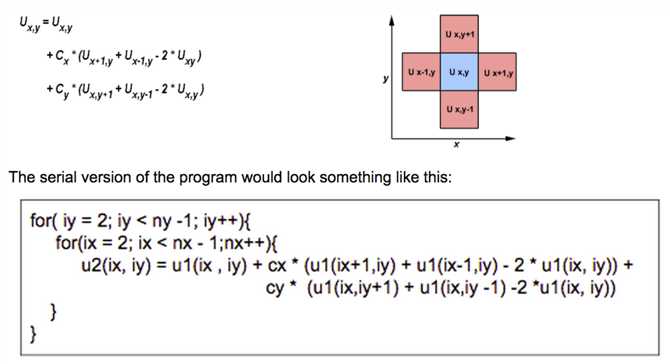
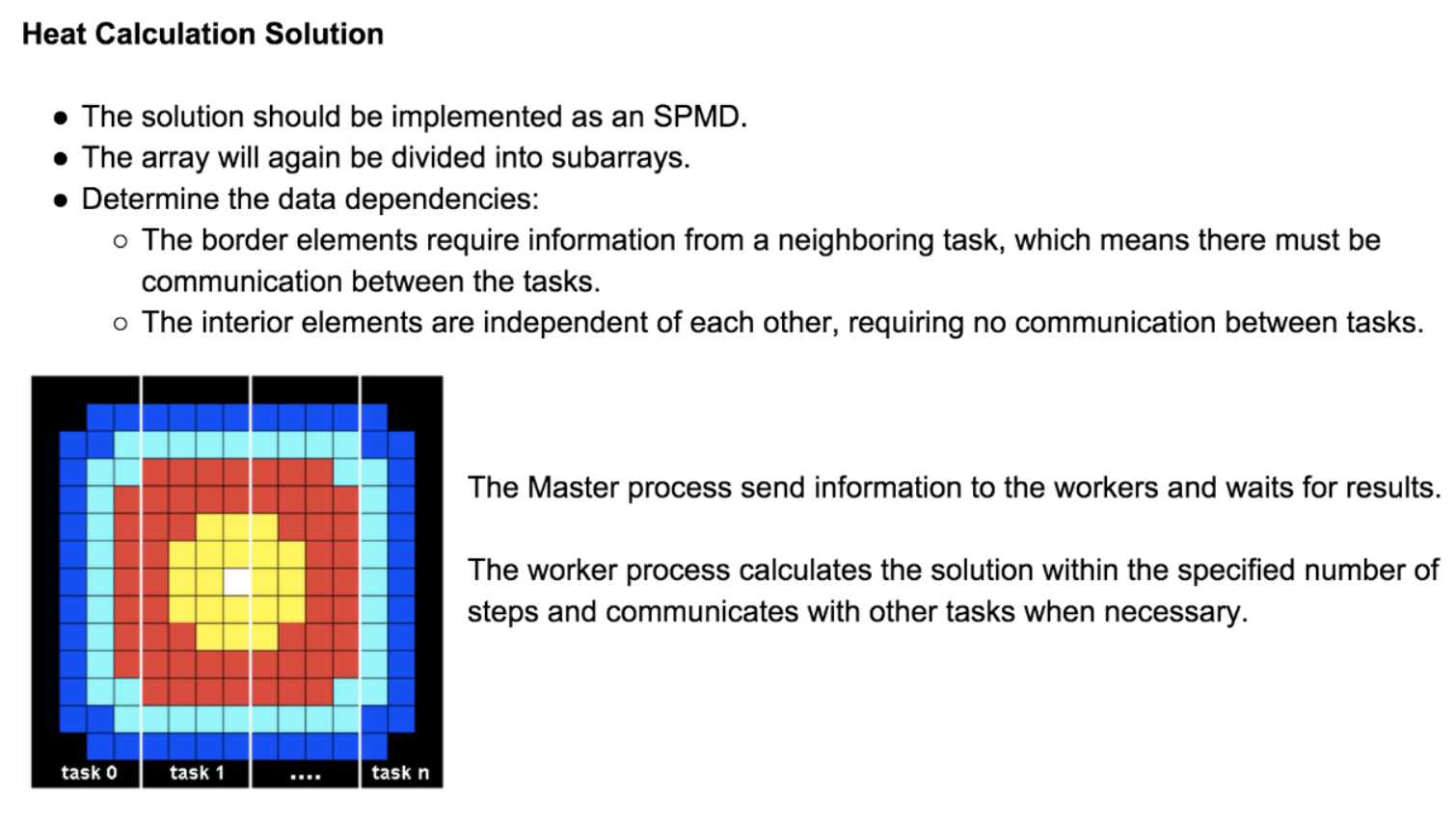

The C version of the program can be found at:
/**************************************************************************** * FILE: mpi_heat2D.c * OTHER FILES: draw_heat.c * DESCRIPTIONS: * HEAT2D Example - Parallelized C Version * This example is based on a simplified two-dimensional heat * equation domain decomposition. The initial temperature is computed to be * high in the middle of the domain and zero at the boundaries. The * boundaries are held at zero throughout the simulation. During the * time-stepping, an array containing two domains is used; these domains * alternate between old data and new data. * * In this parallelized version, the grid is decomposed by the master * process and then distributed by rows to the worker processes. At each * time step, worker processes must exchange border data with neighbors, * because a grid point‘s current temperature depends upon it‘s previous * time step value plus the values of the neighboring grid points. Upon * completion of all time steps, the worker processes return their results * to the master process. * * Two data files are produced: an initial data set and a final data set. * An X graphic of these two states displays after all calculations have * completed. * AUTHOR: Blaise Barney - adapted from D. Turner‘s serial C version. Converted * to MPI: George L. Gusciora (1/95) * LAST REVISED: 06/12/13 Blaise Barney ****************************************************************************/ #include "mpi.h" #include <stdio.h> #include <stdlib.h> extern void draw_heat(int nx, int ny); /* X routine to create graph */ #define NXPROB 20 /* x dimension of problem grid */ #define NYPROB 20 /* y dimension of problem grid */ #define STEPS 100 /* number of time steps */ #define MAXWORKER 8 /* maximum number of worker tasks */ #define MINWORKER 3 /* minimum number of worker tasks */ #define BEGIN 1 /* message tag */ #define LTAG 2 /* message tag */ #define RTAG 3 /* message tag */ #define NONE 0 /* indicates no neighbor */ #define DONE 4 /* message tag */ #define MASTER 0 /* taskid of first process */ struct Parms { float cx; float cy; } parms = {0.1, 0.1}; int main (int argc, char *argv[]) { void inidat(), prtdat(), update(); float u[2][NXPROB][NYPROB]; /* array for grid */ int taskid, /* this task‘s unique id */ numworkers, /* number of worker processes */ numtasks, /* number of tasks */ averow,rows,offset,extra, /* for sending rows of data */ dest, source, /* to - from for message send-receive */ left,right, /* neighbor tasks */ msgtype, /* for message types */ rc,start,end, /* misc */ i,ix,iy,iz,it; /* loop variables */ MPI_Status status; /* First, find out my taskid and how many tasks are running */ MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numtasks); MPI_Comm_rank(MPI_COMM_WORLD,&taskid); numworkers = numtasks-1; if (taskid == MASTER) { /************************* master code *******************************/ /* Check if numworkers is within range - quit if not */ if ((numworkers > MAXWORKER) || (numworkers < MINWORKER)) { printf("ERROR: the number of tasks must be between %d and %d.\n", MINWORKER+1,MAXWORKER+1); printf("Quitting...\n"); MPI_Abort(MPI_COMM_WORLD, rc); exit(1); } printf ("Starting mpi_heat2D with %d worker tasks.\n", numworkers); /* Initialize grid */ printf("Grid size: X= %d Y= %d Time steps= %d\n",NXPROB,NYPROB,STEPS); printf("Initializing grid and writing initial.dat file...\n"); inidat(NXPROB, NYPROB, u); prtdat(NXPROB, NYPROB, u, "initial.dat"); /* Distribute work to workers. Must first figure out how many rows to */ /* send and what to do with extra rows. */ averow = NXPROB/numworkers; extra = NXPROB%numworkers; offset = 0; for (i=1; i<=numworkers; i++) { rows = (i <= extra) ? averow+1 : averow; /* Tell each worker who its neighbors are, since they must exchange */ /* data with each other. */ if (i == 1) left = NONE; else left = i - 1; if (i == numworkers) right = NONE; else right = i + 1; /* Now send startup information to each worker */ dest = i; MPI_Send(&offset, 1, MPI_INT, dest, BEGIN, MPI_COMM_WORLD); MPI_Send(&rows, 1, MPI_INT, dest, BEGIN, MPI_COMM_WORLD); MPI_Send(&left, 1, MPI_INT, dest, BEGIN, MPI_COMM_WORLD); MPI_Send(&right, 1, MPI_INT, dest, BEGIN, MPI_COMM_WORLD); MPI_Send(&u[0][offset][0], rows*NYPROB, MPI_FLOAT, dest, BEGIN, MPI_COMM_WORLD); printf("Sent to task %d: rows= %d offset= %d ",dest,rows,offset); printf("left= %d right= %d\n",left,right); offset = offset + rows; } /* Now wait for results from all worker tasks */ for (i=1; i<=numworkers; i++) { source = i; msgtype = DONE; MPI_Recv(&offset, 1, MPI_INT, source, msgtype, MPI_COMM_WORLD, &status); MPI_Recv(&rows, 1, MPI_INT, source, msgtype, MPI_COMM_WORLD, &status); MPI_Recv(&u[0][offset][0], rows*NYPROB, MPI_FLOAT, source, msgtype, MPI_COMM_WORLD, &status); } /* Write final output, call X graph and finalize MPI */ printf("Writing final.dat file and generating graph...\n"); prtdat(NXPROB, NYPROB, &u[0][0][0], "final.dat"); printf("Click on MORE button to view initial/final states.\n"); printf("Click on EXIT button to quit program.\n"); draw_heat(NXPROB,NYPROB); MPI_Finalize(); } /* End of master code */ /************************* workers code **********************************/ if (taskid != MASTER) { /* Initialize everything - including the borders - to zero */ for (iz=0; iz<2; iz++) for (ix=0; ix<NXPROB; ix++) for (iy=0; iy<NYPROB; iy++) u[iz][ix][iy] = 0.0; /* Receive my offset, rows, neighbors and grid partition from master */ source = MASTER; msgtype = BEGIN; MPI_Recv(&offset, 1, MPI_INT, source, msgtype, MPI_COMM_WORLD, &status); MPI_Recv(&rows, 1, MPI_INT, source, msgtype, MPI_COMM_WORLD, &status); MPI_Recv(&left, 1, MPI_INT, source, msgtype, MPI_COMM_WORLD, &status); MPI_Recv(&right, 1, MPI_INT, source, msgtype, MPI_COMM_WORLD, &status); MPI_Recv(&u[0][offset][0], rows*NYPROB, MPI_FLOAT, source, msgtype, MPI_COMM_WORLD, &status); /* Determine border elements. Need to consider first and last columns. */ /* Obviously, row 0 can‘t exchange with row 0-1. Likewise, the last */ /* row can‘t exchange with last+1. */ start=offset; end=offset+rows-1; if (offset==0) start=1; if ((offset+rows)==NXPROB) end--; printf("task=%d start=%d end=%d\n",taskid,start,end); /* Begin doing STEPS iterations. Must communicate border rows with */ /* neighbors. If I have the first or last grid row, then I only need */ /* to communicate with one neighbor */ printf("Task %d received work. Beginning time steps...\n",taskid); iz = 0; for (it = 1; it <= STEPS; it++) { if (left != NONE) { MPI_Send(&u[iz][offset][0], NYPROB, MPI_FLOAT, left, RTAG, MPI_COMM_WORLD); source = left; msgtype = LTAG; MPI_Recv(&u[iz][offset-1][0], NYPROB, MPI_FLOAT, source, msgtype, MPI_COMM_WORLD, &status); } if (right != NONE) { MPI_Send(&u[iz][offset+rows-1][0], NYPROB, MPI_FLOAT, right, LTAG, MPI_COMM_WORLD); source = right; msgtype = RTAG; MPI_Recv(&u[iz][offset+rows][0], NYPROB, MPI_FLOAT, source, msgtype, MPI_COMM_WORLD, &status); } /* Now call update to update the value of grid points */ update(start,end,NYPROB,&u[iz][0][0],&u[1-iz][0][0]); iz = 1 - iz; } /* Finally, send my portion of final results back to master */ MPI_Send(&offset, 1, MPI_INT, MASTER, DONE, MPI_COMM_WORLD); MPI_Send(&rows, 1, MPI_INT, MASTER, DONE, MPI_COMM_WORLD); MPI_Send(&u[iz][offset][0], rows*NYPROB, MPI_FLOAT, MASTER, DONE, MPI_COMM_WORLD); MPI_Finalize(); } } /************************************************************************** * subroutine update ****************************************************************************/ void update(int start, int end, int ny, float *u1, float *u2) { int ix, iy; for (ix = start; ix <= end; ix++) for (iy = 1; iy <= ny-2; iy++) *(u2+ix*ny+iy) = *(u1+ix*ny+iy) + parms.cx * (*(u1+(ix+1)*ny+iy) + *(u1+(ix-1)*ny+iy) - 2.0 * *(u1+ix*ny+iy)) + parms.cy * (*(u1+ix*ny+iy+1) + *(u1+ix*ny+iy-1) - 2.0 * *(u1+ix*ny+iy)); } /***************************************************************************** * subroutine inidat *****************************************************************************/ void inidat(int nx, int ny, float *u) { int ix, iy; for (ix = 0; ix <= nx-1; ix++) for (iy = 0; iy <= ny-1; iy++) *(u+ix*ny+iy) = (float)(ix * (nx - ix - 1) * iy * (ny - iy - 1)); } /************************************************************************** * subroutine prtdat **************************************************************************/ void prtdat(int nx, int ny, float *u1, char *fnam) { int ix, iy; FILE *fp; fp = fopen(fnam, "w"); for (iy = ny-1; iy >= 0; iy--) { for (ix = 0; ix <= nx-1; ix++) { fprintf(fp, "%8.1f", *(u1+ix*ny+iy)); if (ix != nx-1) fprintf(fp, " "); else fprintf(fp, "\n"); } } fclose(fp); }

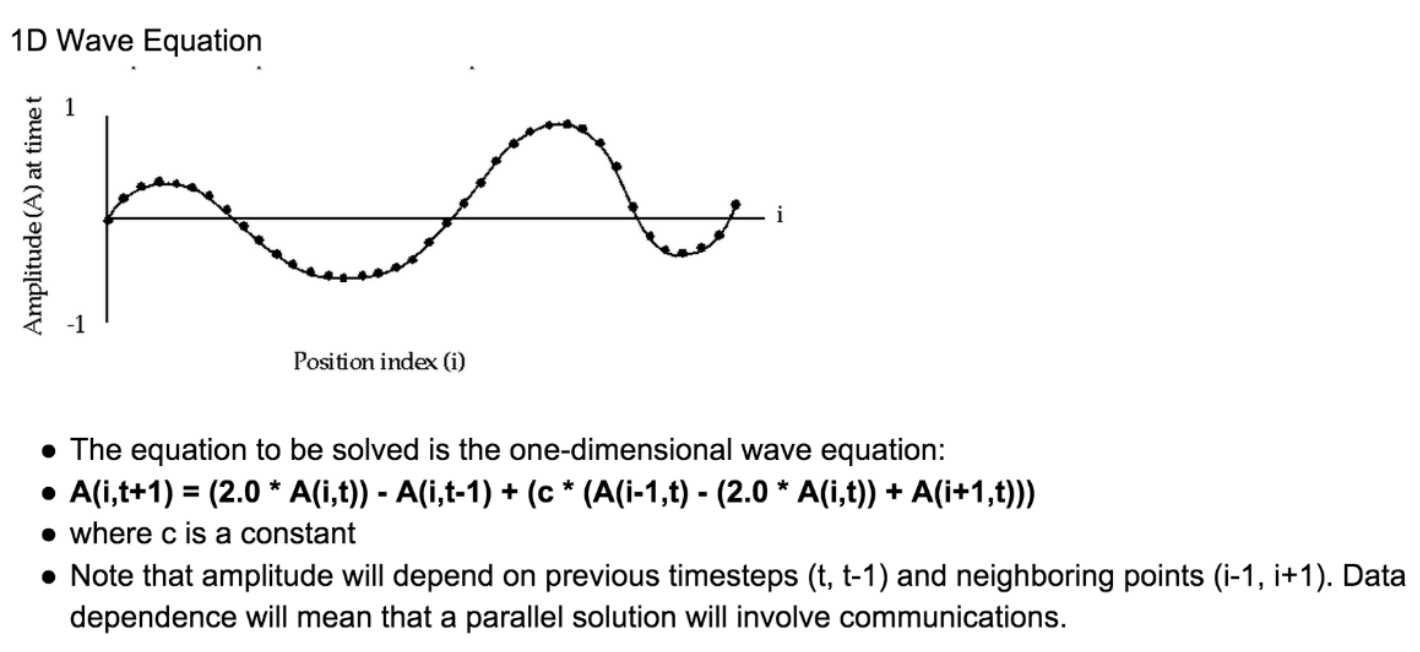
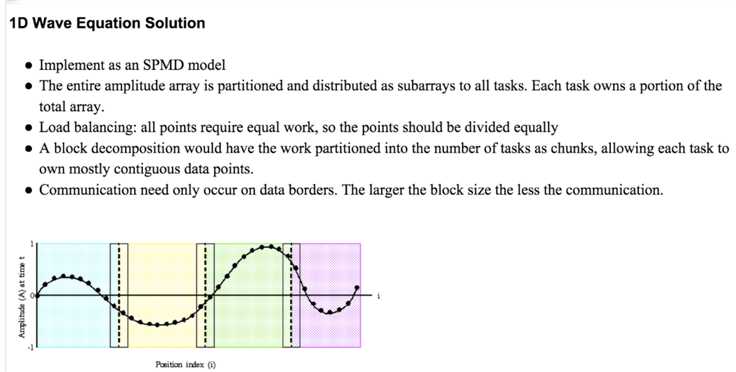
The C version of the program can be found at:
/*************************************************************************** * FILE: mpi_wave.c * OTHER FILES: draw_wave.c * DESCRIPTION: * MPI Concurrent Wave Equation - C Version * Point-to-Point Communications Example * This program implements the concurrent wave equation described * in Chapter 5 of Fox et al., 1988, Solving Problems on Concurrent * Processors, vol 1. * A vibrating string is decomposed into points. Each processor is * responsible for updating the amplitude of a number of points over * time. At each iteration, each processor exchanges boundary points with * nearest neighbors. This version uses low level sends and receives * to exchange boundary points. * AUTHOR: Blaise Barney. Adapted from Ros Leibensperger, Cornell Theory * Center. Converted to MPI: George L. Gusciora, MHPCC (1/95) * LAST REVISED: 07/05/05 ***************************************************************************/ #include "mpi.h" #include <stdio.h> #include <stdlib.h> #include <math.h> #define MASTER 0 #define TPOINTS 800 #define MAXSTEPS 10000 #define PI 3.14159265 int RtoL = 10; int LtoR = 20; int OUT1 = 30; int OUT2 = 40; void init_master(void); void init_workers(void); void init_line(void); void update (int left, int right); void output_master(void); void output_workers(void); extern void draw_wave(double *); int taskid, /* task ID */ numtasks, /* number of processes */ nsteps, /* number of time steps */ npoints, /* number of points handled by this processor */ first; /* index of 1st point handled by this processor */ double etime, /* elapsed time in seconds */ values[TPOINTS+2], /* values at time t */ oldval[TPOINTS+2], /* values at time (t-dt) */ newval[TPOINTS+2]; /* values at time (t+dt) */ /* ------------------------------------------------------------------------ * Master obtains timestep input value from user and broadcasts it * ------------------------------------------------------------------------ */ void init_master(void) { char tchar[8]; /* Set number of number of time steps and then print and broadcast*/ nsteps = 0; while ((nsteps < 1) || (nsteps > MAXSTEPS)) { printf("Enter number of time steps (1-%d): \n",MAXSTEPS); scanf("%s", tchar); nsteps = atoi(tchar); if ((nsteps < 1) || (nsteps > MAXSTEPS)) printf("Enter value between 1 and %d\n", MAXSTEPS); } MPI_Bcast(&nsteps, 1, MPI_INT, MASTER, MPI_COMM_WORLD); } /* ------------------------------------------------------------------------- * Workers receive timestep input value from master * -------------------------------------------------------------------------*/ void init_workers(void) { MPI_Bcast(&nsteps, 1, MPI_INT, MASTER, MPI_COMM_WORLD); } /* ------------------------------------------------------------------------ * All processes initialize points on line * --------------------------------------------------------------------- */ void init_line(void) { int nmin, nleft, npts, i, j, k; double x, fac; /* calculate initial values based on sine curve */ nmin = TPOINTS/numtasks; nleft = TPOINTS%numtasks; fac = 2.0 * PI; for (i = 0, k = 0; i < numtasks; i++) { npts = (i < nleft) ? nmin + 1 : nmin; if (taskid == i) { first = k + 1; npoints = npts; printf ("task=%3d first point=%5d npoints=%4d\n", taskid, first, npts); for (j = 1; j <= npts; j++, k++) { x = (double)k/(double)(TPOINTS - 1); values[j] = sin (fac * x); } } else k += npts; } for (i = 1; i <= npoints; i++) oldval[i] = values[i]; } /* ------------------------------------------------------------------------- * All processes update their points a specified number of times * -------------------------------------------------------------------------*/ void update(int left, int right) { int i, j; double dtime, c, dx, tau, sqtau; MPI_Status status; dtime = 0.3; c = 1.0; dx = 1.0; tau = (c * dtime / dx); sqtau = tau * tau; /* Update values for each point along string */ for (i = 1; i <= nsteps; i++) { /* Exchange data with "left-hand" neighbor */ if (first != 1) { MPI_Send(&values[1], 1, MPI_DOUBLE, left, RtoL, MPI_COMM_WORLD); MPI_Recv(&values[0], 1, MPI_DOUBLE, left, LtoR, MPI_COMM_WORLD, &status); } /* Exchange data with "right-hand" neighbor */ if (first + npoints -1 != TPOINTS) { MPI_Send(&values[npoints], 1, MPI_DOUBLE, right, LtoR, MPI_COMM_WORLD); MPI_Recv(&values[npoints+1], 1, MPI_DOUBLE, right, RtoL, MPI_COMM_WORLD, &status); } /* Update points along line */ for (j = 1; j <= npoints; j++) { /* Global endpoints */ if ((first + j - 1 == 1) || (first + j - 1 == TPOINTS)) newval[j] = 0.0; else /* Use wave equation to update points */ newval[j] = (2.0 * values[j]) - oldval[j] + (sqtau * (values[j-1] - (2.0 * values[j]) + values[j+1])); } for (j = 1; j <= npoints; j++) { oldval[j] = values[j]; values[j] = newval[j]; } } } /* ------------------------------------------------------------------------ * Master receives results from workers and prints * ------------------------------------------------------------------------ */ void output_master(void) { int i, j, source, start, npts, buffer[2]; double results[TPOINTS]; MPI_Status status; /* Store worker‘s results in results array */ for (i = 1; i < numtasks; i++) { /* Receive first point, number of points and results */ MPI_Recv(buffer, 2, MPI_INT, i, OUT1, MPI_COMM_WORLD, &status); start = buffer[0]; npts = buffer[1]; MPI_Recv(&results[start-1], npts, MPI_DOUBLE, i, OUT2, MPI_COMM_WORLD, &status); } /* Store master‘s results in results array */ for (i = first; i < first + npoints; i++) results[i-1] = values[i]; j = 0; printf("***************************************************************\n"); printf("Final amplitude values for all points after %d steps:\n",nsteps); for (i = 0; i < TPOINTS; i++) { printf("%6.2f ", results[i]); j = j++; if (j == 10) { printf("\n"); j = 0; } } printf("***************************************************************\n"); printf("\nDrawing graph...\n"); printf("Click the EXIT button or use CTRL-C to quit\n"); /* display results with draw_wave routine */ draw_wave(&results[0]); } /* ------------------------------------------------------------------------- * Workers send the updated values to the master * -------------------------------------------------------------------------*/ void output_workers(void) { int buffer[2]; MPI_Status status; /* Send first point, number of points and results to master */ buffer[0] = first; buffer[1] = npoints; MPI_Send(&buffer, 2, MPI_INT, MASTER, OUT1, MPI_COMM_WORLD); MPI_Send(&values[1], npoints, MPI_DOUBLE, MASTER, OUT2, MPI_COMM_WORLD); } /* ------------------------------------------------------------------------ * Main program * ------------------------------------------------------------------------ */ int main (int argc, char *argv[]) { int left, right, rc; /* Initialize MPI */ MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&taskid); MPI_Comm_size(MPI_COMM_WORLD,&numtasks); if (numtasks < 2) { printf("ERROR: Number of MPI tasks set to %d\n",numtasks); printf("Need at least 2 tasks! Quitting...\n"); MPI_Abort(MPI_COMM_WORLD, rc); exit(0); } /* Determine left and right neighbors */ if (taskid == numtasks-1) right = 0; else right = taskid + 1; if (taskid == 0) left = numtasks - 1; else left = taskid - 1; /* Get program parameters and initialize wave values */ if (taskid == MASTER) { printf ("Starting mpi_wave using %d tasks.\n", numtasks); printf ("Using %d points on the vibrating string.\n", TPOINTS); init_master(); } else init_workers(); init_line(); /* Update values along the line for nstep time steps */ update(left, right); /* Master collects results from workers and prints */ if (taskid == MASTER) output_master(); else output_workers(); MPI_Finalize(); return 0; }
[High Performance Computing] {Udacity} L4: Intro to OpenMP
标签:ros free reads -o finalize sof change int led
原文地址:https://www.cnblogs.com/ecoflex/p/10888016.html