标签:格式 优点 汉字 需要 语料库 数据清洗 单词 bsp core
现在自然语言处理用深度学习做的比较多,我还没试过用传统的监督学习方法做分类器,比如SVM、Xgboost、随机森林,来训练模型。因此,用Kaggle上经典的电影评论情感分析题,来学习如何用传统机器学习方法解决分类问题。
通过这个情感分析的题目,我会整理做特征工程、参数调优和模型融合的方法,这一系列会有四篇文章。这篇文章整理文本特征工程的内容。
文本的特征工程主要包括数据清洗、特征构造、降维和特征选择等。
首先是数据清洗,比如去停用词、去非字母汉字的特殊字符、大写转小写、去掉html标签等。
然后是特征构建,可以基于词袋模型构造文本特征,比如向量空间模型的词频矩阵、Tf-Idf矩阵,又比如LSA和LDA,也可以用word2vec、glove等文本分布式表示方法,来构造文本特征。此外还可以用n-gram构造文本特征。
接下来可以选择是否降维,可以用PCA或SVD等方法对文本特征矩阵进行降维。
最后选择效果比较突出的1个或几个特征来训练模型。
一、基于向量空间模型的文本特征表示
向量空间模型(Vector Space Model,VSM)也就是单词向量空间模型,区别于LSA、PLSA、LDA这些话题向量空间模型,但是单词向量空间模型和话题向量空间模型都属于词袋模型,又和word2vec等文本分布式表示方法相区别。
向量空间模型的基本想法是:给定一个文本,用一个向量表示该文本的语义,向量的每一维对应一个单词,其数值是该单词在该文本中出现的频数或Tf-Idf。那么每个文本就是一个向量,特征数量为所有文本中的单词总数,通过计算向量之间的余弦相似度可以得到文本的相似度。
而文本集合中的所有文本的向量就会构成一个单词-文本矩阵,元素为单词的频数或Tf-Idf。

在我们这个Kaggle案例中,单词-文本矩阵的行数为样本的数量,列数为单词的数量,训练集中样本有25000条,选取最高频的5000个单词,故矩阵X是(25000,5000)的矩阵。我们以词频和Tf-Idf作为文本特征,计算出两个单词-文本矩阵,然后分别训练随机森林二分类器。
首先导入所需要的库。
import os,re import numpy as np import pandas as pd from bs4 import BeautifulSoup from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.ensemble import RandomForestClassifier from sklearn import metrics import nltk from nltk.corpus import stopwords
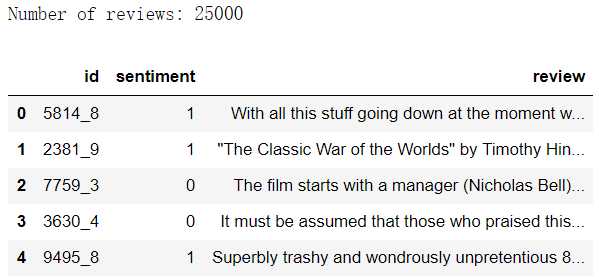
第一步:读取训练数据,一共25000条评论数据。
"""第一步:用pandas读取训练数据""" datafile = os.path.join(‘..‘, ‘data‘, ‘labeledTrainData.tsv‘) # escapechar=‘\\‘用来去掉转义字符‘\‘ df = pd.read_csv(datafile, sep=‘\t‘, escapechar=‘\\‘) print(‘Number of reviews: {}‘.format(len(df))) df.head()
第二步:对影评数据做预处理。
大概有以下环节:
"""第二步:数据预处理""" eng_stopwords = stopwords.words(‘english‘) # 去掉html标签 # 去掉非英文字符 # 去停用词 # 重新组合为句子 def clean_text(text): text = BeautifulSoup(text, ‘html.parser‘).get_text() text = re.sub(r‘[^a-zA-Z]‘, ‘ ‘, text) words = text.lower().split() words = [w for w in words if w not in eng_stopwords] return ‘ ‘.join(words) df[‘clean_review‘] = df.review.apply(clean_text) df.head()

第三步:用向量空间模型抽取文本特征
分别计算单词的词频和Tf-Idf,作为文本特征,计算单词-文本矩阵。
"""第三步:用VSM抽取文本特征""" # 统计词频,作为文本特征,计算文本-单词矩阵 vectorizer_freq = CountVectorizer(max_features = 5000) train_vsm_freq = vectorizer_freq.fit_transform(df.clean_review).toarray() print("以词频为元素的文本-单词矩阵的维度是:\n\n",train_vsm_freq.shape) # 计算tfidf,作为另一种文本特征,计算文本-单词矩阵 vectorizer_tfidf=TfidfVectorizer(max_features=5000) train_vsm_tfidf=vectorizer_tfidf.fit_transform(df.clean_review).toarray() print("\n用单词向量空间模型成功抽取文本特征!\n")
以词频为元素的文本-单词矩阵的维度是: (25000, 5000) 用单词向量空间模型成功抽取文本特征!
第四步:训练分类器
决策树为200棵。
"""第四步:用随机森林训练二分类器""" """首先使用以词频为元素的文本-单词矩阵训练一个分类器""" # 使用包外估计作为模型泛化误差的估计,即oob_score=True,那么无须再做交叉验证 forest = RandomForestClassifier(oob_score=True,n_estimators = 200) forest = forest.fit(train_vsm_freq, df.sentiment)
第五步:评估分类器的性能
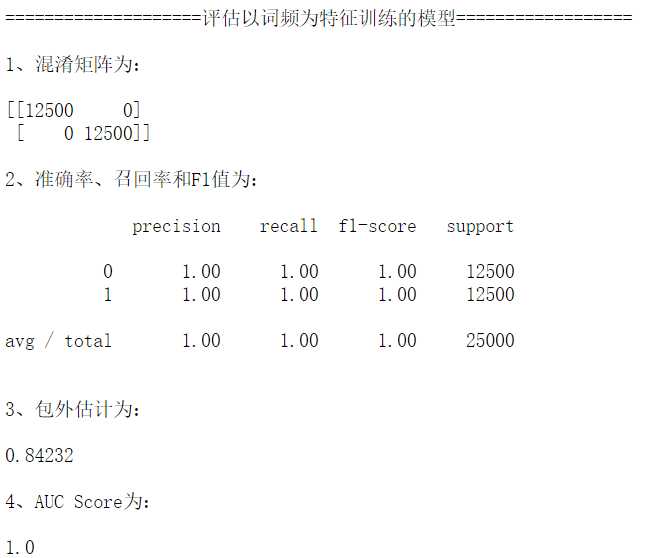
这里没有进行交叉验证了,没有划分验证集来计算准确率、召回率和AUC,直接用训练集来计算这些指标。因为随机森林通过自助采样,可以得到大约36.8%的验证集,用于评估模型的泛化误差,称这为包外估计,因此我们主要观察包外估计这个指标,来评估分类器的性能。
从评估结果来看,包外估计为0.84232。
"""第五步:评估模型""" def model_eval(train_data): print("1、混淆矩阵为:\n") print(metrics.confusion_matrix(df.sentiment, forest.predict(train_data))) print("\n2、准确率、召回率和F1值为:\n") print(metrics.classification_report(df.sentiment,forest.predict(train_data))) print("\n3、包外估计为:\n") print(forest.oob_score_) print("\n4、AUC Score为:\n") y_predprob = forest.predict_proba(train_data)[:,1] print(metrics.roc_auc_score(df.sentiment, y_predprob)) print("\n====================评估以词频为特征训练的模型==================\n") model_eval(train_vsm_freq)
第六步:以Tf-Idf作为文本特征,训练分类器
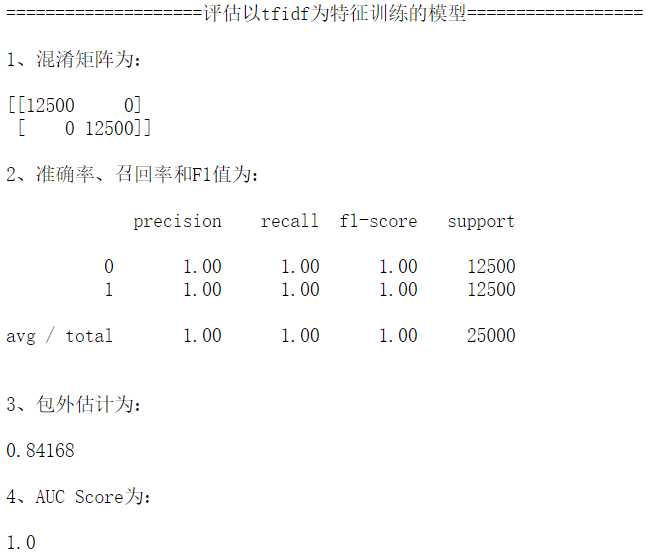
结果包外估计为0.84168,比词频矩阵的要低一点,问题不大。
"""再使用以tfidf为元素的文本-单词矩阵训练一个分类器""" forest = RandomForestClassifier(oob_score=True,n_estimators = 200) forest = forest.fit(train_vsm_tfidf, df.sentiment) print("\n====================评估以tfidf为特征训练的模型==================\n") model_eval(train_vsm_tfidf)
二、基于潜在语义分析的文本特征表示
潜在语义分析(Laten Semantic Analysis,LSA)是一种文本话题分析的方法,特点是可以通过矩阵分解(SVD或者NMF),来发现文本与单词之间的基于话题的语义关系。
LSA和VSM有什么关系呢?
1、VSM的优点是单词向量稀疏,计算效率高,但是由于自然语言中一词多义和多词一义现象的存在,基于单词向量的文本表示未必能准确表达两个文本的相似度。而LSA是用文本的话题来表示文本,文本的话题相似则文本的语义也相似,这样可以解决同义词和多义词的问题。
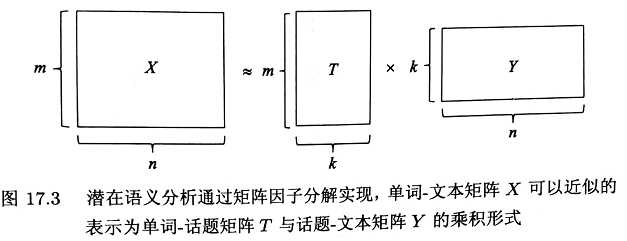
2、VSM得到的是单词-文本矩阵,而LSA得到的是话题-文本矩阵。LSA的话题-文本矩阵就是通过对VSM的矩阵进行矩阵分解得到的,矩阵分解的方法包括SVD奇异值分解和NMF非负矩阵分解。
如下图,NMF非负矩阵分解后得到话题-文本矩阵Y,话题为k个,样本为n个。
在这个情感分析案例中,我们把话题设为300个,把单词-文本矩阵降维成(25000, 300)的话题-文本矩阵,采用的是NMF非负矩阵分解的方法。
要注意的一点是,如果单词-文本矩阵的维度是(单词数,文本数)这种格式,也就是我们在代码中用到的格式,那么在用 sklearn.decomposition.NMF 这个包计算话题-文本矩阵时,NMF().fit_transform() 所得的是话题-文本矩阵,NMF().components_得到的是单词-话题矩阵。
而如果单词-文本矩阵的格式和上图的格式一样(转置了),那么NMF().components_得到的是话题-文本矩阵。
下面首先用NMF计算LSA的话题-文本矩阵,取以词频为元素的单词-文本矩阵来计算。对高维矩阵进行矩阵分解的时间复杂度非常高,所以我用一下LSA就好了,LDA就不敢再去尝试,因为LDA的时间复杂度更高,效果可能不一定好。
第一步:用NMF计算LSA的话题-文本矩阵
"""用NMF计算LSA的话题-文本矩阵""" from sklearn.decomposition import NMF # 对以词频为特征的单词-文本矩阵进行NMF分解 nmf = NMF(n_components=300) # 得到话题-文本矩阵,注意如果输入进行了转置,那么得到的是单词-话题矩阵 train_lsa_freq = nmf.fit_transform(train_vsm_freq) print("话题-文本矩阵的维度是:\n\n",train_lsa_freq.shape)
话题-文本矩阵的维度是:
(25000, 300)
第二步:使用LSA的话题-文本矩阵训练随机森林分类器
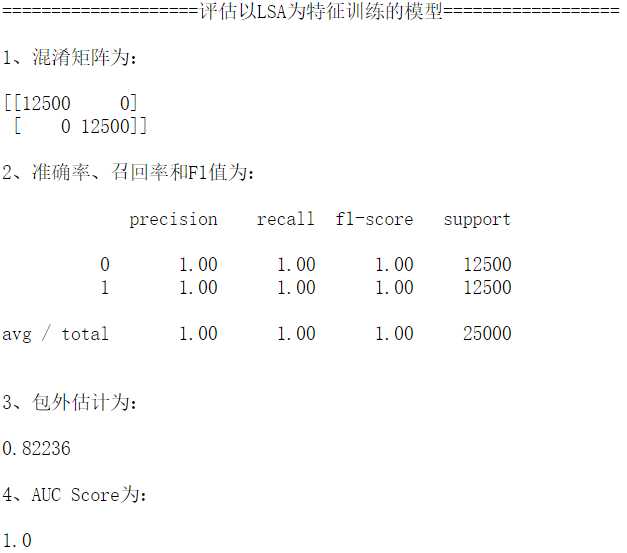
包外估计为0.82236,比基于VSM的效果要差2个百分点左右,毕竟特征维度降低了。本来想把话题设定为500,也就是把特征维度降到500维,可是计算时间太恐怖了,久久得不到结果。
这真是费力不讨好。
"""再使用LSA的话题-文本矩阵训练一个分类器""" forest = RandomForestClassifier(oob_score=True,n_estimators = 200) forest = forest.fit(train_lsa_freq, df.sentiment) print("\n====================评估以LSA为特征训练的模型==================\n") model_eval(train_lsa_freq)
三、用n-gram做文本表示
n-gram的意思比较简单了,没啥好说的。我这里让n-gram=(2,2),也就是每个单元都是两个单词组合而成的。
"""使用sklearn计算2-gram,得到词语-文本矩阵""" # token_pattern的作用是,出现"bi-gram"、"two:three"这种时,可以切成"bi gram"、"two three"的形式 vectorizer_2gram = CountVectorizer(ngram_range=(2,2),token_pattern=r‘\b\w+\b‘,max_features=5000) train_vsm_2gram = vectorizer_2gram.fit_transform(df.clean_review).toarray() print("2-gram构成的语料库中前10个元素为:\n") print(vectorizer_2gram.get_feature_names()[:10])
2-gram构成的语料库中前10个元素为: [‘able get‘, ‘able make‘, ‘able see‘, ‘able watch‘, ‘absolute worst‘, ‘absolutely brilliant‘,
‘absolutely hilarious‘, ‘absolutely love‘, ‘absolutely loved‘, ‘absolutely nothing‘]
接着再训练随机森林分类器,并评估模型。不知道怎么回事,跑了很久,死活收敛不了,有毒。。。算了,放着让它跑,我也再想想到底咋回事。
"""使用以2-gram的词频为元素的单词-文本矩阵训练一个分类器""" forest = RandomForestClassifier(oob_score=True,n_estimators = 200) forest = forest.fit(train_vsm_2gram, df.sentiment) print("\n====================评估以2-gram为特征训练的模型==================\n") model_eval(train_vsm_2gram)
最后还是重新训练第一个模型,也就是用词频作为特征的单词-文本矩阵,训练随机森林分类器。我们读取测试数据进行预测,并保存预测结果。
# 删除不用的占内容变量 #del df #del train_vsm_freq # 读取测试数据 datafile = os.path.join(‘..‘, ‘data‘, ‘testData.tsv‘) df = pd.read_csv(datafile, sep=‘\t‘, escapechar=‘\\‘) print(‘Number of reviews: {}‘.format(len(df))) df[‘clean_review‘] = df.review.apply(clean_text) vectorizer = CountVectorizer(max_features = 5000) test_data_features = vectorizer.fit_transform(df.clean_review).toarray() result = forest.predict(test_data_features) output = pd.DataFrame({‘id‘:df.id, ‘sentiment‘:result}) # 保存 output.to_csv(os.path.join(‘..‘, ‘data‘, ‘Bag_of_Words_model.csv‘), index=False)
参考资料:
李航:《统计学习方法》(第二版) 第17章
文本情感分析(一):基于词袋模型(VSM、LSA、n-gram)的文本表示
标签:格式 优点 汉字 需要 语料库 数据清洗 单词 bsp core
原文地址:https://www.cnblogs.com/Luv-GEM/p/10888026.html