标签:基础上 支持 utf-8 字母 ima int eric 表示 src
编码详解
编码支持:
- ASCII编码:美国信息交换标准代码(American Standard Code for InformationInterchange,简称ASCII)是一种用于信息交换的美国标准代码,它的作用是给英文字母、数字、标点、字符转换成计算机能识别的二进制数规定了一个大家都认可并遵守的标准。
- GB2312编码:适用于汉字处理、汉字通信等系统之间的信息交换
- GBK编码:是汉字编码标准之一,是在 GB2312-80 标准基础上的内码扩展规范,使用了双字节编码
- ANSI是与你使用的windows操作系统的语言有关系的,向windows 7 简体中文版就是GBK(用一个字节表示英文,用两个字节表示一个中文)
- Unicode编码:这是一种世界上所有字符的编码,但是它没有规定的存储方式。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
- UTF-8编码:是 Unicode Transformation Format - 8 bit 的缩写, UTF-8 是 Unicode 的一种实现方式。它是可变长的编码方式,可以使用 1~4 个字节表示一个字符,可根据不同的符号而变化字节长度。UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码,继续工作。
可以这么理解,unicode包括utf-8,utf-8包括gbk,gbk包括gb2312。
一、文件格式防止中文乱码三部曲:
第一步:把文件保存为utf-8格式;

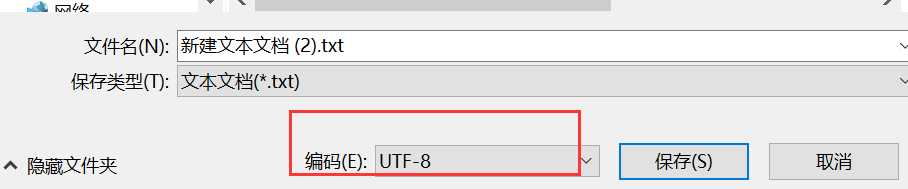
第二步:在第一行添加编码:#encoding=utf-8或#coding=utf-8

第三步:中文前加u(此u是unicode的意思)

例子:
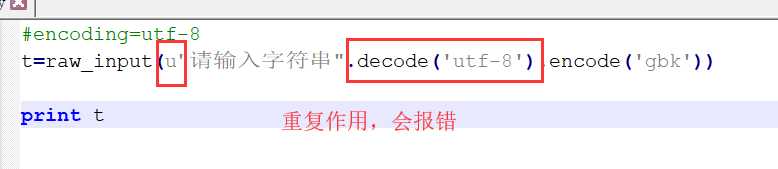
raw_input(u"请输入字符串".decode(‘utf-8‘).encode(‘gbk‘))
在decode的基础上解码了,再加上‘u‘会报错,因为u的意思是解码成unicode,如果再decode就会重复作用,会报错

二、编码转换:
终极原则:decode early , unicode everywhere , encode late
“gbk”--->decode (‘gbk‘)---> unicode--->encode(‘utf-8‘)
decode解码:其他编码的字符串转换成unicode编码,如name.decode(‘gbk‘),将gbk编码的字符串name转换成unicode编码
encode编码:将unicode编码转换成其他编码的字符串,如name.encode(‘gbk’),将unicode编码的name字符串转换为gbk编码
备注:(进行编码时必须知道name是哪一种编码,type(‘name‘)查询)
三、文件存储和读取的编码:
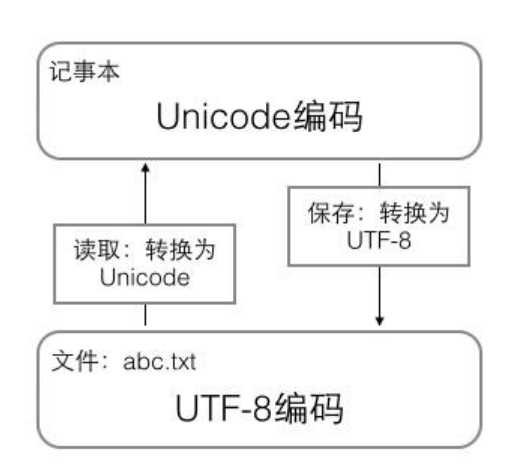
1、在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
2、用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
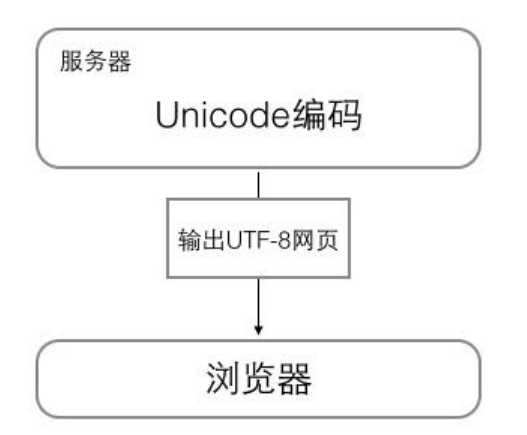
2、浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器。很多网页的源码上会有类似<meta charset="utf-8"/>的信息,表示该网页正是用的UTF-8编码
第二讲:编码详解,防止中文乱码
标签:基础上 支持 utf-8 字母 ima int eric 表示 src
原文地址:https://www.cnblogs.com/wenxiacui/p/10888144.html