标签:首页 safari 输入 image 参数 project request dirname ror
模拟登陆知乎后,跳转到首页,返回400,请求无效,应该是知乎对request请求有做要求。
看了下请求头,主要关注cookie、referer和user_agent(不要问为什么,我看视频的),cookie在scrapy.Request里有单独参数。不管怎样,先测试下:
# -*- coding: utf-8 -*- import scrapy,os,re from scrapy.http import Request from mouse import move class ZhihuSpider(scrapy.Spider): name = ‘zhihu‘ allowed_domains = [‘zhihu.com‘] start_urls = [‘http://zhihu.com/‘] headers = { # "HOST": "www.zhihu.com", "Referer": "https://www.zhizhu.com", ‘User-Agent‘: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36" } custom_settings = { "COOKIES_ENABLED": True, ‘User-Agent‘:"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36", ‘HTTPERROR_ALLOWED_CODES‘ : [400] } def parse(self, response): pass def parse_request(self,response): pass def parse_answer(self,response): pass def start_requests(self): from selenium import webdriver from scrapy.selector import Selector project_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__))) chromedriver_dir = os.path.join(project_dir, "tools\\chromedriver.exe") browser = webdriver.Chrome( executable_path=chromedriver_dir) browser.get("https://www.zhihu.com/signup?next=%2F") # 模拟登录知乎,选择登录选项 # info = response.xpath(‘//*[@id="root"]/div/main/div/div/div/div[2]/div[2]/span/text()‘) browser.find_element_by_xpath(‘//*[@id="root"]/div/main/div/div/div/div[2]/div[2]/span‘).click() # 输入账号//*div[@class=‘SignFlow-accountInput Input-wrapper‘]/input browser.find_element_by_xpath( ‘//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/div[1]/div[2]/div[1]/input‘).send_keys( "656521736@qq.com") # 输入密码 browser.find_element_by_xpath( ‘//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/div[2]/div/div[1]/input‘).send_keys("*****") # 模拟登录知乎,点击登录按钮 # //*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/button browser.find_element_by_xpath(‘//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/button‘).click() import time time.sleep(10) Cookies = browser.get_cookies() print(Cookies) cookie_dict = {} import pickle pickle.dump(Cookies, open("./ArticleSpider/cookies/zhihu.cookie", "wb")) # for cookie in Cookies: # # 写入文件 # zhihu_cookie_dir = os.path.join(project_dir, "cookies\\zhihu\\") # f = open(zhihu_cookie_dir + cookie[‘name‘] + ‘.zhihu‘, "wb") # pickle.dump(cookie, f) # f.close() # cookie_dict[cookie[‘name‘]] = cookie[‘value‘] cookie_dict = {} for cookie in Cookies: cookie_dict[cookie["name"]] = cookie["value"] # browser.close() # return Request(url=r"https://www.zhihu.com/",headers=self.headers,cookies=cookie_dict,callback=self.check_login) return [Request(url=self.start_urls[0], dont_filter=True,headers=self.headers, cookies=cookie_dict)]
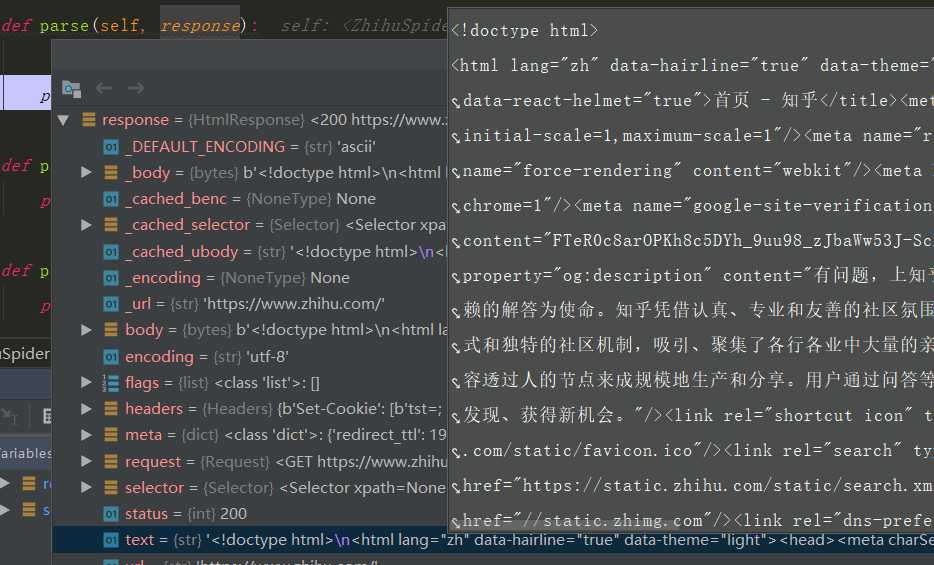
在Request里加上headers,再跳转到parse时,response就能看到首页了:
标签:首页 safari 输入 image 参数 project request dirname ror
原文地址:https://www.cnblogs.com/laonicc/p/10896973.html