标签:des style blog http color io os ar 使用
SIFT(Scale-invariant feature transform)是一种检測局部特征的算法,该算法通过求一幅图中的特征点(interest points,or corner points)及其有关scale 和 orientation 的描写叙述子得到特征并进行图像特征点匹配,获得了良好效果,具体解析例如以下:
SIFT特征不仅仅具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检測效果。整个算法分为以下几个部分:
1. 构建尺度空间
这是一个初始化操作,尺度空间理论目的是模拟图像数据的多尺度特征。
高斯卷积核是实现尺度变换的唯一线性核,于是一副二维图像的尺度空间定义为:

当中 G(x,y,σ) 是尺度可变高斯函数 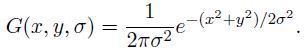
(x,y)是空间坐标,是尺度坐标。σ大小决定图像的平滑程度,大尺度相应图像的概貌特征,小尺度相应图像的细节特征。大的σ值相应粗糙尺度(低分辨率),反之,相应精细尺度(高分辨率)。为了有效的在尺度空间检測到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分核与图像卷积生成。
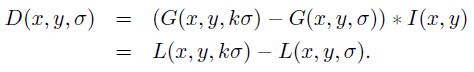
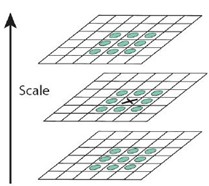
下图所看到的不同σ下图像尺度空间:
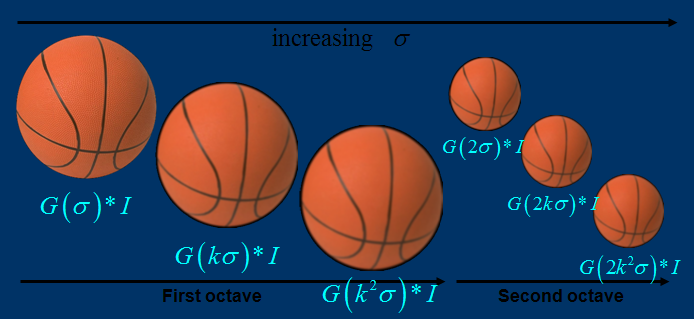
关于尺度空间的理讲解明:2kσ中的2是必须的,尺度空间是连续的。在 Lowe的论文中 ,将第0层的初始尺度定为1.6(最模糊),图片的初始尺度定为0.5(最清晰). 在检測极值点前对原始图像的高斯平滑以致图像丢失高频信息,所以 Lowe 建议在建立尺度空间前首先对原始图像长宽扩展一倍,以保留原始图像信息,添加特征点数量。尺度越大图像越模糊。
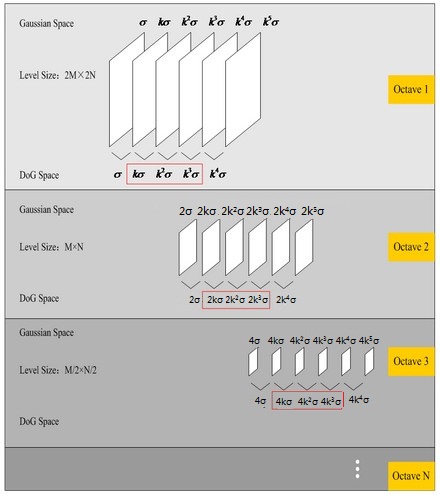
图像金字塔的建立:对于一幅图像I,建立其在不同尺度(scale)的图像,也成为子八度(octave),这是为了scale-invariant,也就是在不论什么尺度都能够有相应的特征点,第一个子八度的scale为原图大小,后面每一个octave为上一个octave降採样的结果,即原图的1/4(长宽分别减半),构成下一个子八度(高一层金字塔)。

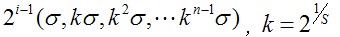
尺度空间的全部取值,i为octave的塔数(第几个塔),s为每塔层数
由图片size决定建几个塔,每塔几层图像(S一般为3-5层)。0塔的第0层是原始图像(或你double后的图像),往上每一层是对其下一层进行Laplacian变换(高斯卷积,当中σ值渐大,比如能够是σ, k*σ, k*k*σ…),直观上看来越往上图片越模糊。塔间的图片是降採样关系,比如1塔的第0层能够由0塔的第3层down sample得到,然后进行与0塔类似的高斯卷积操作。
2. LoG近似DoG找到关键点<检測DOG尺度空间极值点>
为了寻找尺度空间的极值点,每一个採样点要和它全部的相邻点比較,看其是否比它的图像域和尺度域的相邻点大或者小。如图所看到的,中间的检測点和它同尺度的8个相邻点和上下相邻尺度相应的9×2个点共26个点比較,以确保在尺度空间和二维图像空间都检測到极值点。 一个点假设在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就觉得该点是图像在该尺度下的一个特征点,如图所看到的。
同一组中的相邻尺度(因为k的取值关系,肯定是上下层)之间进行寻找
s=3的情况
使用Laplacian of Gaussian能够非常好地找到找到图像中的兴趣点,可是须要大量的计算量,所以使用Difference of Gaussian图像的极大极小值近似寻找特征点.DOG算子计算简单,是尺度归一化的LoG算子的近似,有关DOG寻找特征点的介绍及方法详见http://blog.csdn.net/abcjennifer/article/details/7639488,极值点检測用的Non-Maximal Suppression。
3. 除去不好的特征点
这一步本质上要去掉DoG局部曲率非常不正确称的像素。
通过拟和三维二次函数以精确确定关键点的位置和尺度(达到亚像素精度),同一时候去除低对照度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应),以增强匹配稳定性、提高抗噪声能力,在这里使用近似Harris Corner检測器。
①空间尺度函数泰勒展开式例如以下: ,对上式求导,并令其为0,得到精确的位置, 得
,对上式求导,并令其为0,得到精确的位置, 得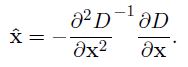
②在已经检測到的特征点中,要去掉低对照度的特征点和不稳定的边缘响应点。去除低对照度的点:把公式(2)代入公式(1),即在DoG Space的极值点处D(x)取值,仅仅取前两项可得:

若 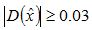 ,该特征点就保留下来,否则丢弃。
,该特征点就保留下来,否则丢弃。
③边缘响应的去除
一个定义不好的高斯差分算子的极值在横跨边缘的地方有较大的主曲率,而在垂直边缘的方向有较小的主曲率。主曲率通过一个2×2 的Hessian矩阵H求出:
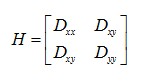
导数由採样点相邻差预计得到。
D的主曲率和H的特征值成正比,令α为较大特征值,β为较小的特征值,则
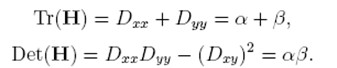
令α=γβ,则
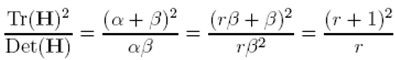
(r + 1)2/r的值在两个特征值相等的时候最小,随着r的增大而增大,因此,为了检測主曲率是否在某域值r下,仅仅需检測
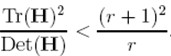
if (α+β)/ αβ> (r+1)2/r, throw it out. 在Lowe的文章中,取r=10。
4. 给特征点赋值一个128维方向參数
上一步中确定了每幅图中的特征点,为每一个特征点计算一个方向,按照这个方向做进一步的计算, 利用关键点邻域像素的梯度方向分布特性为每一个关键点指定方向參数,使算子具备旋转不变性。
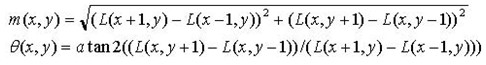
为(x,y)处梯度的模值和方向公式。当中L所用的尺度为每一个关键点各自所在的尺度。至此,图像的关键点已经检測完成,每一个关键点有三个信息:位置,所处尺度、方向,由此能够确定一个SIFT特征区域。
在实际计算时,我们在以关键点为中心的邻域窗体内採样,并用直方图统计邻域像素的梯度方向。梯度直方图的范围是0~360度,当中每45度一个柱,总共8个柱, 或者每10度一个柱,总共36个柱。Lowe论文中还提到要使用高斯函数对直方图进行平滑,降低突变的影响。直方图的峰值则代表了该关键点处邻域梯度的主方向,即作为该关键点的方向。
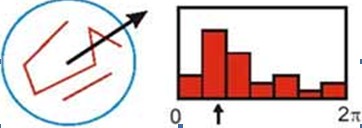
直方图中的峰值就是主方向,其它的达到最大值80%的方向可作为辅助方向
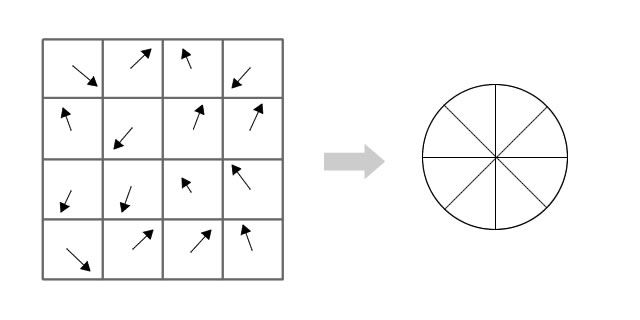
由梯度方向直方图确定主梯度方向
该步中将建立全部scale中特征点的描写叙述子(128维)
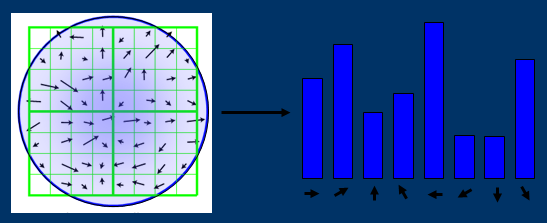
关键点描写叙述子的生成步骤

5. 关键点描写叙述子的生成
首先将坐标轴旋转为关键点的方向,以确保旋转不变性。以关键点为中心取8×8的窗体。
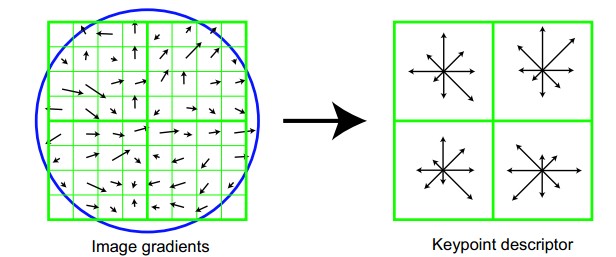
Figure.16*16的图中当中1/4的特征点梯度方向及scale,右图为其加权到8个主方向后的效果。
图左部分的中央为当前关键点的位置,每一个小格代表关键点邻域所在尺度空间的一个像素,利用公式求得每一个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,箭头长度代表梯度模值,然后用高斯窗体对其进行加权运算。
图中蓝色的圈代表高斯加权的范围(越靠近关键点的像素梯度方向信息贡献越大)。然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每一个梯度方向的累加值,就可以形成一个种子点,如图右部分示。此图中一个关键点由2×2共4个种子点组成,每一个种子点有8个方向向量信息。这样的邻域方向性信息联合的思想增强了算法抗噪声的能力,同一时候对于含有定位误差的特征匹配也提供了较好的容错性。
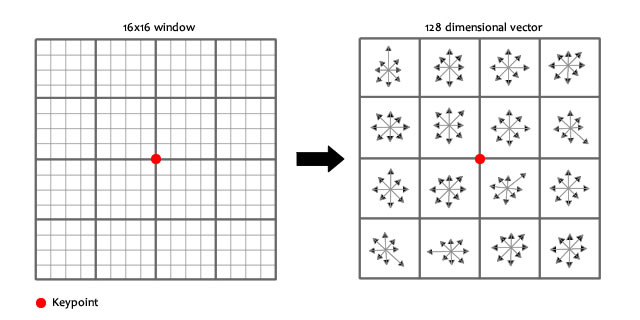
在每一个4*4的1/16象限中,通过加权梯度值加到直方图8个方向区间中的一个,计算出一个梯度方向直方图。
这样就能够对每一个feature形成一个4*4*8=128维的描写叙述子,每一维都能够表示4*4个格子中一个的scale/orientation. 将这个向量归一化之后,就进一步去除了光照的影响。
5. 依据SIFT进行Match
生成了A、B两幅图的描写叙述子,(各自是k1*128维和k2*128维),就将两图中各个scale(全部scale)的描写叙述子进行匹配,匹配上128维就可以表示两个特征点match上了。
实际计算过程中,为了增强匹配的稳健性,Lowe建议对每一个关键点使用4×4共16个种子点来描写叙述,这样对于一个关键点就能够产生128个数据,即终于形成128维的SIFT特征向量。此时SIFT特征向量已经去除了尺度变化、旋转等几何变形因素的影响,再继续将特征向量的长度归一化,则能够进一步去除光照变化的影响。 当两幅图像的SIFT特征向量生成后,下一步我们採用关键点特征向量的欧式距离来作为两幅图像中关键点的类似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离近期的前两个关键点,在这两个关键点中,假设近期的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会降低,但更加稳定。为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,Lowe提出了比較近期邻距离与次近邻距离的方法,距离比率ratio小于某个阈值的觉得是正确匹配。因为对于错误匹配,因为特征空间的高维性,类似的距离可能有大量其它的错误匹配,从而它的ratio值比較高。Lowe推荐ratio的阈值为0.8。但作者对大量随意存在尺度、旋转和亮度变化的两幅图片进行匹配,结果表明ratio取值在0. 4~0. 6之间最佳,小于0. 4的非常少有匹配点,大于0. 6的则存在大量错误匹配点。(假设这个地方你要改进,最好给出一个匹配率和ration之间的关系图,这样才有说服力)作者建议ratio的取值原则例如以下:
ratio=0. 4 对于精确度要求高的匹配;
ratio=0. 6 对于匹配点数目要求比較多的匹配;
ratio=0. 5 普通情况下。
也可按例如以下原则:当近期邻距离<200时ratio=0. 6,反之ratio=0. 4。ratio的取值策略能排分错误匹配点。
当两幅图像的SIFT特征向量生成后,下一步我们採用关键点特征向量的欧式距离来作为两幅图像中关键点的类似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离近期的前两个关键点,在这两个关键点中,假设近期的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会降低,但更加稳定。
实验结果:



Python+opencv实现:
import cv2 import numpy as np #import pdb #pdb.set_trace()#turn on the pdb prompt #read image img = cv2.imread(‘D:\privacy\picture\little girl.jpg‘,cv2.IMREAD_COLOR) gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) cv2.imshow(‘origin‘,img); #SIFT detector = cv2.SIFT() keypoints = detector.detect(gray,None) img = cv2.drawKeypoints(gray,keypoints) #img = cv2.drawKeypoints(gray,keypoints,flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) cv2.imshow(‘test‘,img); cv2.waitKey(0) cv2.destroyAllWindows()
C实现:
// FeatureDetector.cpp : Defines the entry point for the console application.
//
// Created by Rachel on 14-1-12.
// Copyright (c) 2013年 ZJU. All rights reserved.
//
#include "stdafx.h"
#include "highgui.h"
#include "cv.h"
#include "vector"
#include "opencv\cxcore.hpp"
#include "iostream"
#include "opencv.hpp"
#include "nonfree.hpp"
#include "showhelper.h"
using namespace cv;
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
//Load Image
Mat c_src1 = imread( "..\\Images\\3.jpg");
Mat c_src2 = imread("..\\Images\\4.jpg");
Mat src1 = imread( "..\\Images\\3.jpg", CV_LOAD_IMAGE_GRAYSCALE);
Mat src2 = imread( "..\\Images\\4.jpg", CV_LOAD_IMAGE_GRAYSCALE);
if( !src1.data || !src2.data )
{ std::cout<< " --(!) Error reading images " << std::endl; return -1; }
//sift feature detect
SiftFeatureDetector detector;
std::vector<KeyPoint> kp1, kp2;
detector.detect( src1, kp1 );
detector.detect( src2, kp2 );
SiftDescriptorExtractor extractor;
Mat des1,des2;//descriptor
extractor.compute(src1,kp1,des1);
extractor.compute(src2,kp2,des2);
Mat res1,res2;
int drawmode = DrawMatchesFlags::DRAW_RICH_KEYPOINTS;
drawKeypoints(c_src1,kp1,res1,Scalar::all(-1),drawmode);//在内存中画出特征点
drawKeypoints(c_src2,kp2,res2,Scalar::all(-1),drawmode);
cout<<"size of description of Img1: "<<kp1.size()<<endl;
cout<<"size of description of Img2: "<<kp2.size()<<endl;
//write the size of features on picture
CvFont font;
double hScale=1;
double vScale=1;
int lineWidth=2;// 相当于写字的线条
cvInitFont(&font,CV_FONT_HERSHEY_SIMPLEX|CV_FONT_ITALIC, hScale,vScale,0,lineWidth);//初始化字体,准备写到图片上的
// cvPoint 为起笔的x,y坐标
IplImage* transimg1 = cvCloneImage(&(IplImage) res1);
IplImage* transimg2 = cvCloneImage(&(IplImage) res2);
char str1[20],str2[20];
sprintf(str1,"%d",kp1.size());
sprintf(str2,"%d",kp2.size());
const char* str = str1;
cvPutText(transimg1,str1,cvPoint(280,230),&font,CV_RGB(255,0,0));//在图片中输出字符
str = str2;
cvPutText(transimg2,str2,cvPoint(280,230),&font,CV_RGB(255,0,0));//在图片中输出字符
//imshow("Description 1",res1);
cvShowImage("descriptor1",transimg1);
cvShowImage("descriptor2",transimg2);
BFMatcher matcher(NORM_L2);
vector<DMatch> matches;
matcher.match(des1,des2,matches);
Mat img_match;
drawMatches(src1,kp1,src2,kp2,matches,img_match);//,Scalar::all(-1),Scalar::all(-1),vector<char>(),drawmode);
cout<<"number of matched points: "<<matches.size()<<endl;
imshow("matches",img_match);
cvWaitKey();
cvDestroyAllWindows();
return 0;
}
辅助资料:

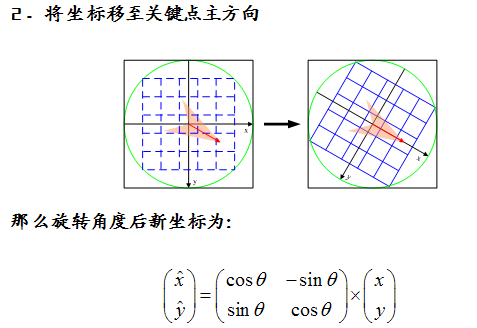
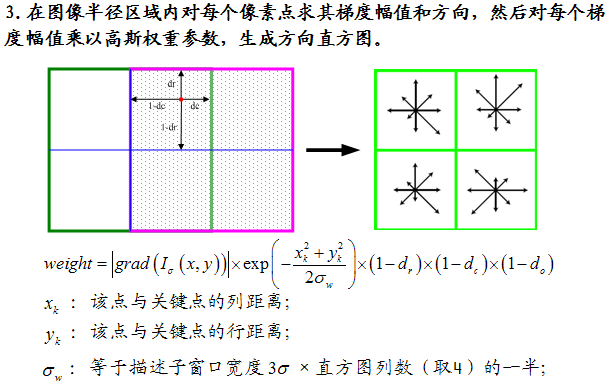

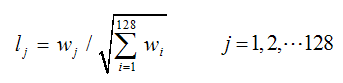
===============================
Reference:
Lowe SIFT 原文:http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
SIFT 的C实现:https://github.com/robwhess/opensift/blob/master/src
MATLAB 应用Sift算子的模式识别方法:http://blog.csdn.net/abcjennifer/article/details/7372880
http://blog.csdn.net/abcjennifer/article/details/7365882
http://en.wikipedia.org/wiki/Scale-invariant_feature_transform#David_Lowe.27s_method
http://blog.sciencenet.cn/blog-613779-475881.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080950.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080951.html
http://blog.csdn.net/ijuliet/article/details/4640624
http://www.cnblogs.com/cfantaisie/archive/2011/06/14/2080917.html (部分图片有误,以本文中的图片为准)
关于computer vision的很多其它讨论与交流,敬请关注本博客和新浪微博Rachel____Zhang。
标签:des style blog http color io os ar 使用
原文地址:http://www.cnblogs.com/gcczhongduan/p/4041076.html