标签:应该 mysq 堆栈 分配 tps rocketmq 技术 微服务 hadoop
微信公众号:内核小王子
关注可了解更多关于数据库,JVM内核相关的知识;
如果你有任何疑问也可以加我pigpdong[^1]
随着微服务化,以及集群规模化,传统的日志检索,指标监控,调用链分析作为功能单一的系统,已经无法更好的帮我们分析问题,我们需要一个监控平台将他们之间的数据进行整合和分析,输出更友好的视图给用户.
指标报警 -> 应用 -> 服务 -> 事物 -> 堆栈 -> 日志
以下为随手记的监控平台的Focus架构
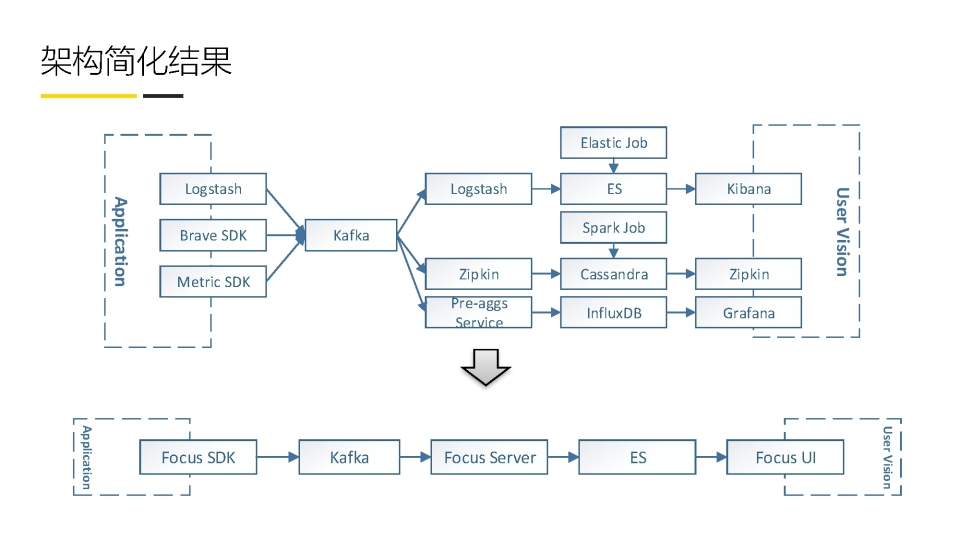
下图描述了典型的三层监控体系,将基础层,中间件层,应用层的数据进行聚合分析
基础层:监控主机和底层资源,CPU,内存,网络吞吐,硬盘IO和硬盘容量
中间件层:nginx redis kafka mysql tomcat
应用层: HTTP访问吞吐量,响应时间,调用链分析,用户行为分析

我们一般会遵循opentracing的接口,一个调用链入口,会开始一个trace,分配到一个traceid,然后缓存到调用链上下文,每一个分支调用都会开启一个span,然后每一个span都会记录自己的开始时间和结束时间,以及他的父span是谁.这样就可以清楚的记下,每一个RPC调用,在每一个步骤分别执行了多长时间,例如调用RPC-A花了多久,RPC-A又执行sql-a花了多久,RPC-A读取缓存花了多久等等.
我们通过调用链的过程可以分析出服务间的调用,进而展示出应用间的依赖topo图,我们可以借助这个topo他再监控页面展示核心指标的报警.
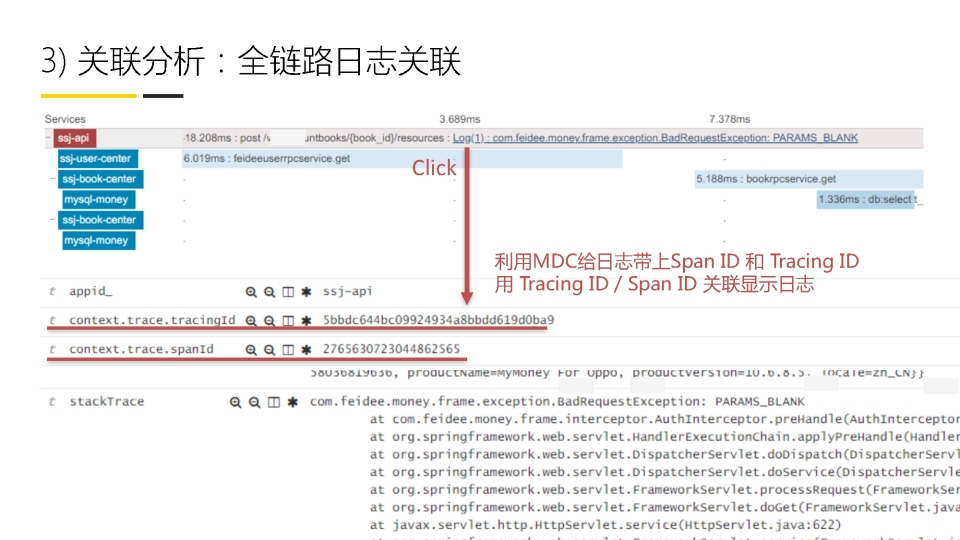
一般哪些节点需要埋点
最开始单体引用的时候我们可以直接让运维查看服务器上的日志,或者用一个跳板机,在这个跳板机上查看多个服务器上的日志,后来数据量和请求上来了,大量的日志进行检索的时候如果继续使用grep,AWK这种文本工具将不能满足需求,然后就有了ELK方案,一般在应用的日志中增加一个appender,将日志输出到kafka,日志存储在kafka中,然后通过logstash去kafka拉取日志,当然这个时候可以增加一些filter对日志进行过滤,然后输出到elastic search中,然后通过kibana提供使用中视图.
如果我们需要将日志纳入统一的监控平台,我们可以将日志和调用链中的traceid进行绑定,然后一起存入ES中,这样在分析某一个调用链的时候,可以自动展示对应的日志.
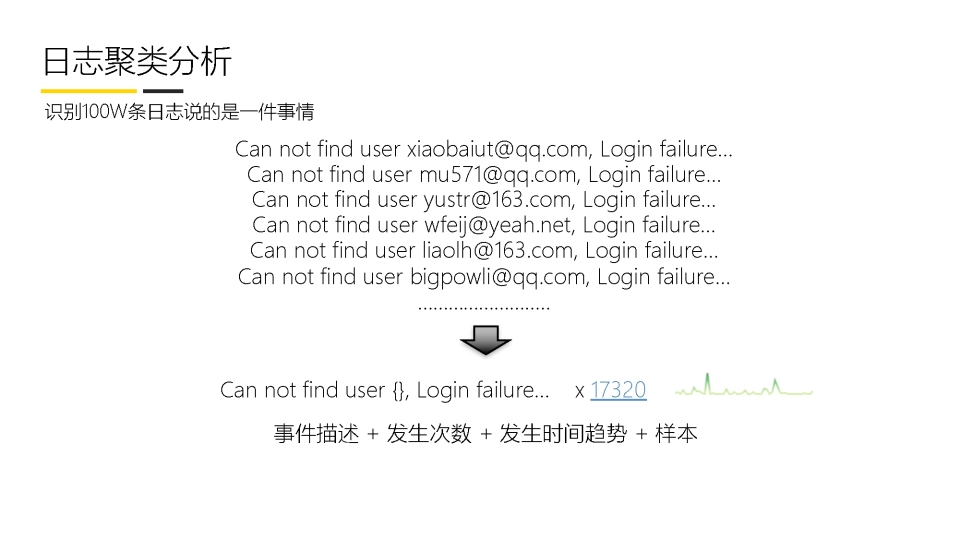
日志降噪,可以借助kafka stream流处理的工具,将相同类型的日志进行去重,例如一个用户购买的日志,可能都是一样,只是用户id和购买金额不一样,那么我们可以只存储这个日志,分别在某个时间段出现了多少次,以及对应的用户,这样可以节省大量的日志空间,当然也可以提高减速效率.
除了一些硬件负载,例如是否CPU使用率,线程数目,内存大小等,还有一些用户设置的指标,例如单位时间内购买请求的失败率等,某一个服务调用次数,日志条数等.以及服务的TOPN视图,例如按调用量,调用耗时,单位时间内的调用量等
数据采集器一般部署在应用端,为了支持更高的并发量,我们可以借助ringbuffer这种无锁队列提高效率,或者直接推给KAFKA做中转,那么这里有个选择就是在推送前,是否需要在应用端节点做一些指标计算或者压缩,
如果应用端有大量的CPU空余就可以选择在应用端做,如果应用侧对带宽不敏感,CPU更敏感就将原始数据都推送过去.
有些同学觉得,监控层应该对应用无感,所以希望应用不要依赖监控的SDK,这种方式一般借助 -javaagent对应用进行字节码增强,这种方式如果只是针对特定的拦截器增加指标,例如rpc调用,日志等,可以简单地针对特定的类增强,如果需要用户手工设置监控指标,则需要在用户层的类做字节码增强,开发会比较复杂,当然具体情况可以根据公司应用环境进行调整,例如只有用户手工增加的指标依赖SDK,某个应用没有指标则可以不依赖
由于监控数据量很大,我们可以选择放入es中,也将一些历史数据放入hadoop中
可以借助kafka stream,使监控平台更轻量,不需要依赖spark straming或者 apach storm
标签:应该 mysq 堆栈 分配 tps rocketmq 技术 微服务 hadoop
原文地址:https://www.cnblogs.com/pigpdong/p/10900207.html