标签:推导 持续更新 list 实验 计算 声明 运算 tick 错误分析
Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为 。它结合了Eiffel的契约方法设计 和Larch 系列接口规范语言的基于模型的规范方法 。
JML是契约式语言的一种具体表现形式。
契约(Contact):声明一个函数/方法的时候,对函数的输入和输出所具备的性质是有所期望和规定的。有时候这种性质会被我们明确的写出来,有时候会被我们忽略掉。这些期望和规定就是Contract。
而契约设计的核心便是断言(assertion) :永远为真的布尔型语句,如果不为真,则程序必然存在错误。
因此我们可以通过一些三段论形式的规格语言来限制方法,并通过其检验是否符合标准。
目前通过JML语言实现Java程序检验的工具便是OpenJml:
OpenJml是Java程序的程序验证工具,不是定理证明器或模型检查器本身。OpenJml将JML规范转换为SMT-LIB格式,并将Java + JML程序隐含的证明问题传递给后端SMT求解器。
OpenJml实际上充当的为翻译官的角色,将JML规范转换为SMT-LIB格式,这在官网上链接的Z3求解器也可看出:
openjml官网求解界面: https://www.rise4fun.com/OpenJMLESC/
Z3求解器官网求解界面: https://rise4fun.com/Z3/tutorial/guide
目前OpenJML同样支持Eclipse与IDEA等主流Java编辑器,但两者的体验有所不同:
目前OpenJml支持主流的求解器:
CVC4:由斯坦福大学开发,目前持续更新
下载地址:http://cvc4.cs.stanford.edu/downloads/
Z3 :由Microsoft开发,但微软官网已经停止更新。(版本停滞在4.1)
GitHub持续更新地址:https://github.com/Z3Prover/z3
Yices:由斯坦福国际研究院开发。
下载地址:http://yices.csl.sri.com/
可根据规格自动化生成测试样例,进行单元测试的JML测试工具
通常使用命令行或者编辑器内带Test插件完成测试
官网:http://insttech.secretninjaformalmethods.org/software/jmlunitng/
//TODO
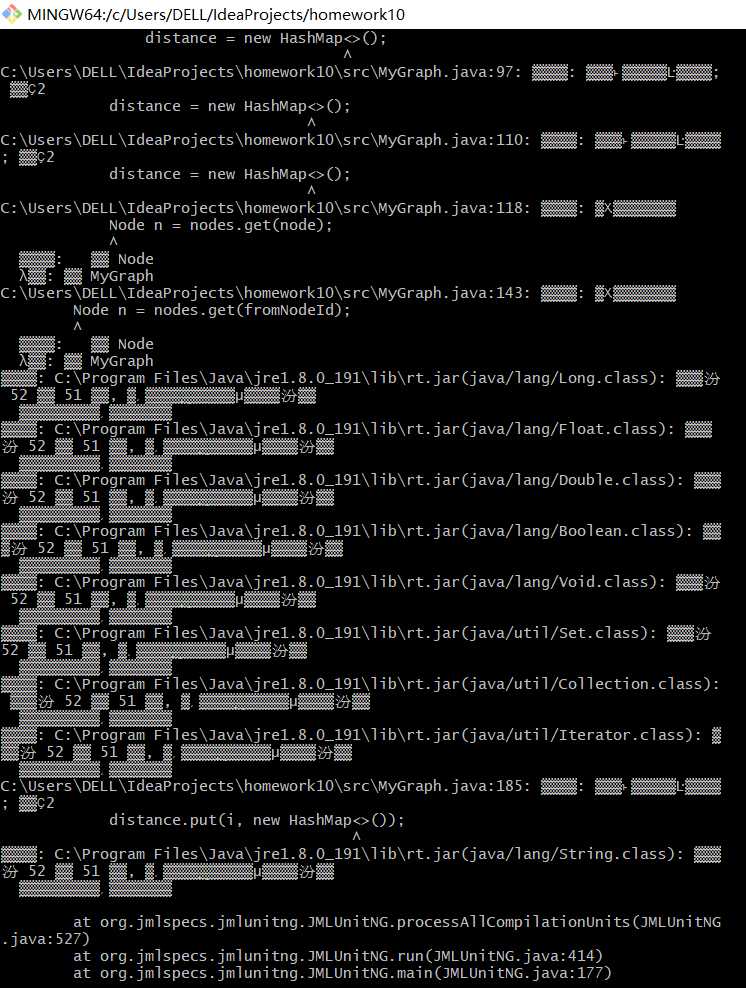
由于在使用过程中遇到乱码文件,使用的HashMap等数据结构也不能很好识别。
自认为修改格式或数据结构,来符合测试所需,和本次实验目的不是特别符合。于是自写了规格简单实现path中的部分方法。实现代码如下所示:
package test;
public class testNG {
public int[] path;
public testNG(int num) {
path = new int[num];
}
//@ public normal_behaviour
//@ ensures \result == path.length;
public /*@ pure @*/ int size() {
return path.length;
}
/*@ public normal_behaviour
@ requires i < 10 && i >= 0 && num >= 0;
@ ensures path[i] == num;
*/
public void add(int i, int num) {
path[i] = num;
}
public static void main(String[] args) {
testNG ng = new testNG(5);
ng.add(3, 23);
ng.size();
}
}依次执行
$ java -jar jmlunitng.jar test/testNG.java
$ javac -cp jmlunitng.jar test/*.java
$ java -jar openjml.jar -rac test/testNG.java
$ java -cp jmlunitng.jar test.testNG_JML_Test
? 测试结果如下所示:
[TestNG] Running:
Command line suite
Passed: racEnabled()
Failed: <<test.testNG@59690aa4>>.add(-2147483648, -2147483648)
Failed: <<test.testNG@64cee07>>.add(0, -2147483648)
Failed: <<test.testNG@1761e840>>.add(2147483647, -2147483648)
Failed: <<test.testNG@6c629d6e>>.add(-2147483648, 0)
Failed: <<test.testNG@5ecddf8f>>.add(0, 0)
Failed: <<test.testNG@3f102e87>>.add(2147483647, 0)
Failed: <<test.testNG@27abe2cd>>.add(-2147483648, 2147483647)
Failed: <<test.testNG@6fdb1f78>>.add(0, 2147483647)
Failed: <<test.testNG@51016012>>.add(2147483647, 2147483647)
Passed: <<test.testNG@29444d75>>.size()
Passed: static main(null)
Failed: constructor testNG(-2147483648)
Passed: constructor testNG(0)
Failed: constructor testNG(2147483647)
===============================================
Command line suite
Total tests run: 15, Failures: 11, Skips: 0
===============================================可以看出边缘数据超出了int型范围时或者为负数是,均无法通过测试,与我们的预期相符。
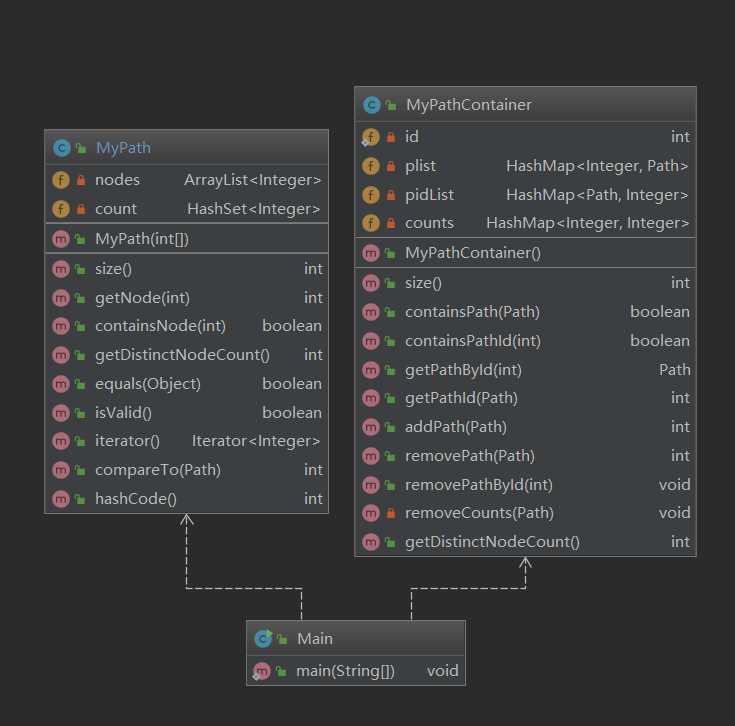
可以看出,第九次作业的架构非常简单,基本上完全是按照规格进行书写。
其中Path类中采用了ArrayList与Hashset来储存Path中的节点数据,其中ArrayList由于其有序性,对于获取指定编号的节点复杂度较低,而HashSet具有内部元素不能重复的特点,可以直接获取Path中不同节点的个数。
而PathContainer类中采用了
private HashMap<Integer, Path> plist;
private HashMap<Path, Integer> pidList;
private HashMap<Integer, Integer> counts;可以通过plist和pidList,实现Path与id中复杂度为1的互相转换。
而counts通过记录每条Path中的不同节点的出现次数,来记录整个容器中不同节点的总数。
由于之前作业中从未出现过超时错误,导致对于复杂度的关注度较低,只片面地追求了正确性,导致强测最后得分仅有50分。通过超时点分析,发现主要原因在于一开始并没有实现pidlist,而所有查找均通过pidpath实现,导致超时。
是的,我竟然没有在指导书上发现创建删除指令与查找指令的比例关系,导致没有认清占用时间最长的请求是查询。
通过将pidlist加入,并自己实现了path的hashcode和equals方法,将bug成功改正。
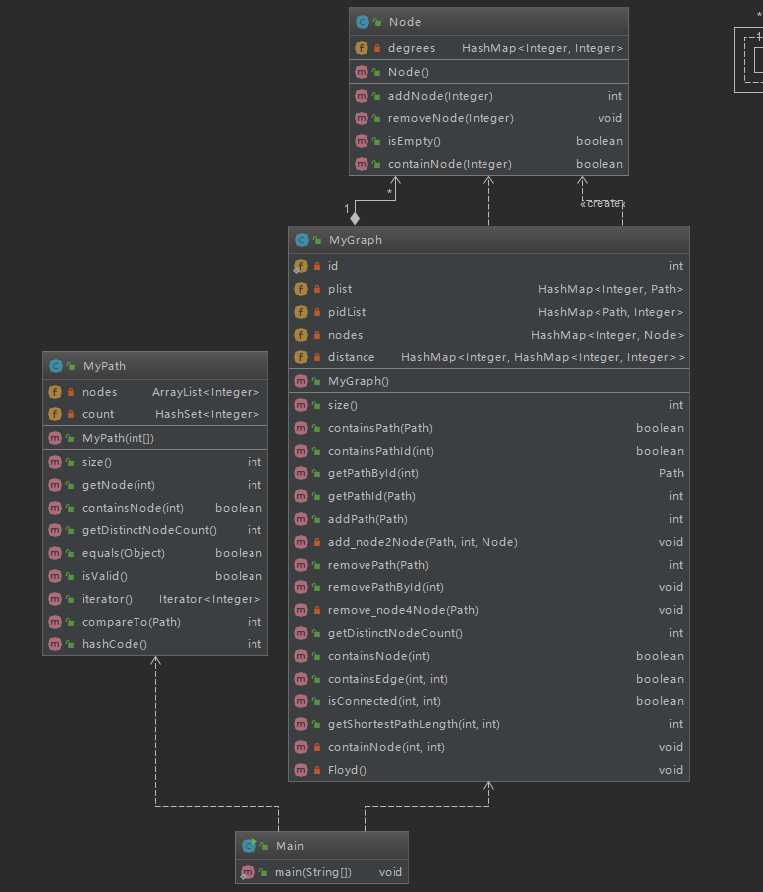
第二次作业中相较于第一次作业加入了自己的Node(节点类),殊不知这成为本次作业最大的败笔所在。
除了第一次代码被全部复用外,额外加入了以下两个数据结构:
private HashMap<Integer, Node> nodes;
private HashMap<Integer, HashMap<Integer, Integer>> distance;nodes通过节点的id找到Node类,并在Node类中记录该节点的度。
distance为存储距离的hashmap,三个Interger分别代表出发节点,目的节点以及距离。
距离采用Floyd算法,并利用无向图最短路矩阵为对称矩阵的特性,进行剪枝处理。
上面说到本次最大的败笔在于自己设计的Node类 : 原本可以通过简单的多重Hashmap实现的功能,却通过新建类来实现
本次作业中,测试数据同样出现了查询指令占大多数,增删指令占极少数的分布方式。
而按照我的设计方法,每次查询时均需要new一至两个Node对象,这一设计的直接后果导致最后时间激增,强测数据全部GG,最后连互测都没有进。
之后看到大家Hashmap嵌套Hashmap的结构,感到一丝讽刺意味。自作聪明实现一个本无需实现的类强行实现出来,相当于自掘坟墓。最后由于时间原因,通过对Floyd算法进行极限减枝,使得时间最后在超时边缘疯狂试探,但成功进行了bug修复。
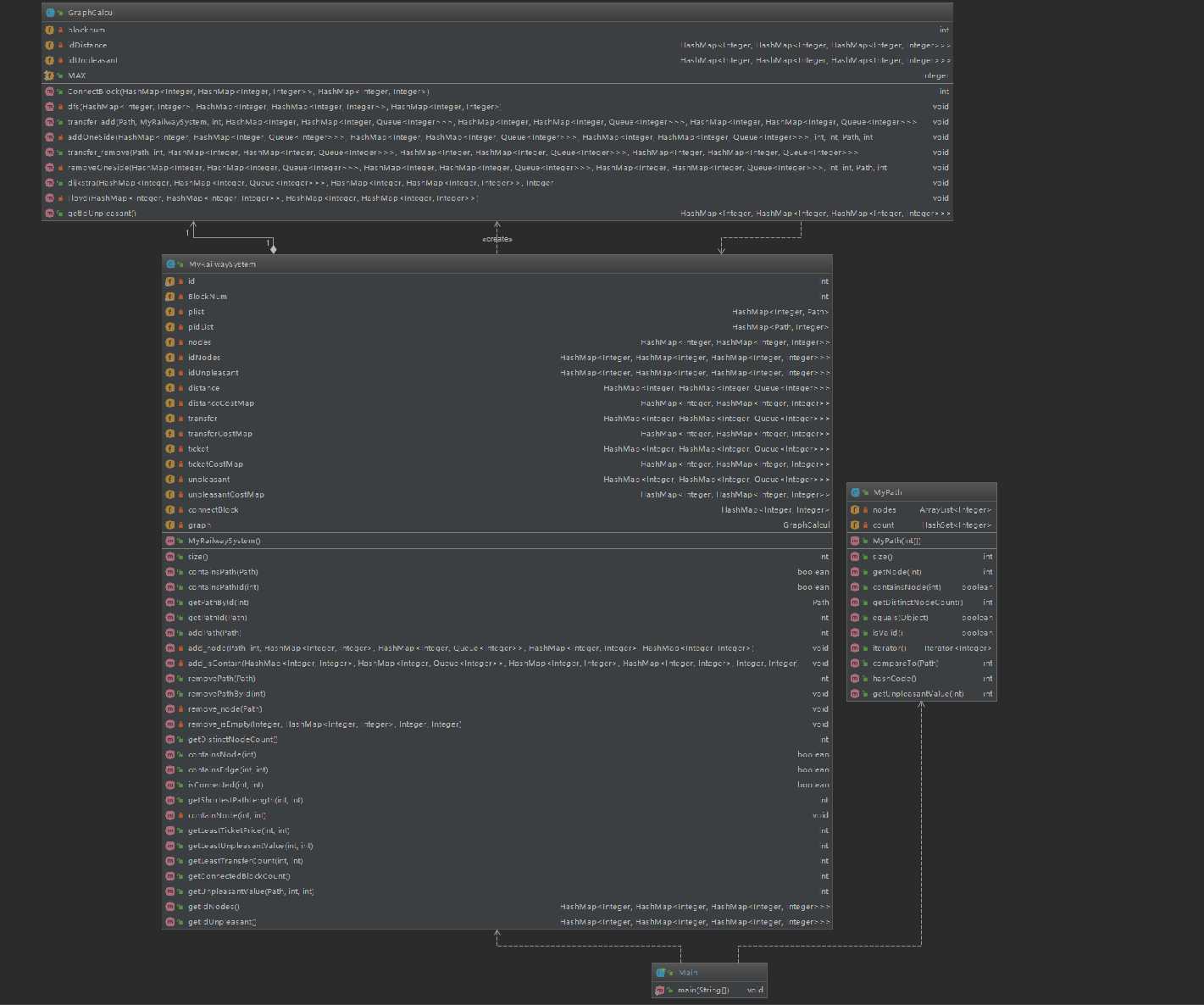
本次作业是三次作业中设计的最满意的一次,由于前两次作业都由于态度不端正导致出现了很多错误。本次实验充分吸取了前两次作业的的失败经验,设计了以下的数据结构:
private HashMap<Integer, Path> plist;
private HashMap<Path, Integer> pidList;
private HashMap<Integer, HashMap<Integer, Integer>> nodes;
private HashMap<Integer,HashMap<Integer, HashMap<Integer, Integer>>> idNodes;
private HashMap<Integer, HashMap<Integer, HashMap<Integer, Integer>>> idUnpleasant;
private HashMap<Integer, HashMap<Integer, Queue<Integer>>> distance;
private HashMap<Integer, HashMap<Integer, Integer>> distanceCostMap;
private HashMap<Integer, HashMap<Integer, Queue<Integer>>> transfer;
private HashMap<Integer, HashMap<Integer, Integer>> transferCostMap;
private HashMap<Integer, HashMap<Integer, Queue<Integer>>> ticket;
private HashMap<Integer, HashMap<Integer, Integer>> ticketCostMap;
private HashMap<Integer, HashMap<Integer, Queue<Integer>>> unpleasant;
private HashMap<Integer, HashMap<Integer, Integer>> unpleasantCostMap;
private HashMap<Integer, Integer> connectBlock;
private GraphCalcul graph;其中
connectBlock为记录节点联通块的数据结构,采用DFS算法进行计算。两个Integer分别代表结点编号,联通块在每次增删指令后首先运算,从而简化其他路径的运算。(若两节点处于不同联通块中,则无需后续计算)
distanceCostMap,transferCostMap,ticketCostMap和unpleasantCostMap为记录最短权重矩阵的数据结构,采用Dijkstra堆优化算法计算,每次的查询指令输入后进行判断
distance, transfer, ticket和unpleasant为记录原始权重路径的数据结构,供Dijkstra堆优化算法使用。
考虑到可能出现的自环现象,会导致依次赋权边的方法出现错误,因此应在这之前算出Path内两两节点的最短路径,本次考虑到一条路径中的节点数不是很多,且每两节点之间的最短路均需要,因此采用了Floyd算法。
因此最短路径的计算被分散到增删路径与查找路径阶段,通过将查找阶段的运算结果进行保存,做到越查越快的目的。
本次本来也考虑的是拆点方法,但看到巧妙赋边权统一建模的思想时,感觉茅塞顿开,为本次作业的顺利进行提供了很大帮助。
本次强测过程终于以满分通过,但在自己debug阶段发现一些问题,主要是对Dijkstra理解不深入导致的。
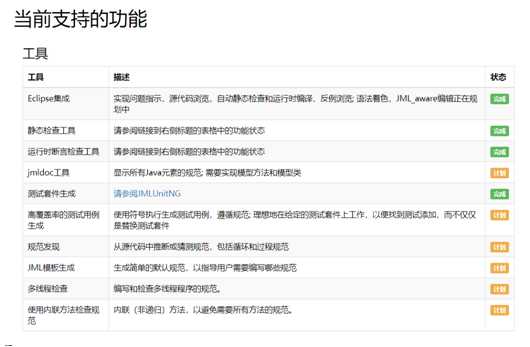
本三次作业主要考察了大家阅读JML格式以及算法方面的知识。虽然JML看起来还无法胜任我们期望它完成的所有工作,但我觉得课程组是基于下面几点考虑:
? 
标签:推导 持续更新 list 实验 计算 声明 运算 tick 错误分析
原文地址:https://www.cnblogs.com/ArthurN/p/10907614.html