标签:环境 内容 ring from 自己的 win 第三方库 包含 测试
| 函数 | 说明 |
| get(url [, timeout=n]) | 对应HTTP的GET方式,设定请求超时时间为n秒 |
| post(url, data={‘key‘:‘value‘}) | 对应HTTP的POST方式,字典用于传输客户数据 |
| delete(url) | 对应HTTP的DELETE方式 |
| head(url) | 对应HTTP的HEAD方式 |
| options(url) | 对应HTTP的OPTIONS方式 |
| put(url, data={‘key‘:‘value‘}) | 对应HTTP的PUT方式,字典用于传输客户数据 |
其中,最常用的是get方法,它能够获得url的请求,并返回一个response对象作为响应。有了响应对象,就能为所欲为了,你觉得呢 ^x^
| 属性 | 说明 |
| status_code | HTTP请求的返回状态(???咨询一下) |
| encoding | HTTP响应内容的编码方式 |
| text | HTTP响应内容的字符串形式 |
| content | HTTP响应内容的二进制形式 |
| 方法 | 说明 |
| json() | 若http响应内容中包含json格式数据, 则解析json数据 |
| raise_for_status() | 若http返回的状态码不是200, 则产生异常 |
5. 好了,我们开工 >>>
① 导入库
from requests import get
② 设定url, 并使用get方法请求页面得到响应
url = "http://www.baidu.com"
r = get(url, timeout=3)
print("获得响应的状态码:", r.status_code)
print("响应内容的编码方式:", r.encoding)
运行结果:
获得响应的状态码: 200
响应内容的编码方式: ISO-8859-1
③ 获取网页内容
url_text = r.text
print("网页内容:", r.text)
print("网页内容长度:", len(url_text))
运行结果:
网页内容: <!DOCTYPE html><!--STATUS OK--><html> <head> ... 京ICPè¯?030173å?· ... </body> </html>
网页内容长度: 2381
惊不惊讶? 激不激动? 好不好玩? >>> 好吧,如果看到我上面 标蓝 加粗 的不明字体,你可能会 》》》问 》》》为什么?
还记得上面的编码方式吗?没错,就是他!!!
这是因为HTML代码也有自己的编码方式,我们需要使用相同的编码方式。下图是HTML语言的编码方式设置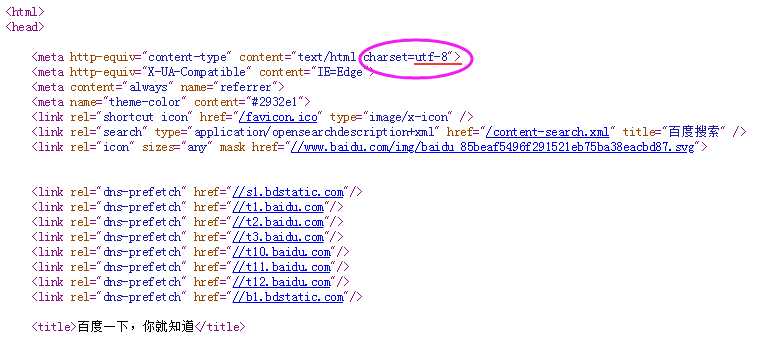
知道了原因,那就好搞了!
④ 重新获取网页内容
r.encoding = "utf-8"
url_text = r.text
print("网页内容:", r.text)
print("网页内容长度:", len(url_text))
运行结果:
网页内容: <!DOCTYPE html> <!--STATUS OK--><html> <head> ... 意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
网页内容长度: 2287
很明显,这次可以了 ^v^

url = "http://www.sogou.com" # 搜狗
for i in range(200):
print("Test %d:" % (i+1), end=" ")
response = get(url, timeout=5)
# 判断连接状态
if response.status_code == 200:
print("Conncect successful!")
else:
print("Conncect UNsuccessful!")
运行结果:
Test 1: Conncect successful!
Test 2: Conncect successful!
Test 3: Conncect successful!
Test 4: Conncect successful!
Test 5: Conncect successful!................
Test 199: Conncect successful!
Test 200: Conncect successful!
标签:环境 内容 ring from 自己的 win 第三方库 包含 测试
原文地址:https://www.cnblogs.com/luorunsb/p/10911264.html