标签:clear net document btn 直接 变量 mod 自动化 enc
selenium 本身是一套web自动化测试工具,但其经常被用于爬虫,解决一些复杂爬虫的问题。
selenium 用于爬虫时,相当于模拟人操作浏览器。
使用 selenium 需要先安装 浏览器驱动,selenium 支持多种浏览器
可以看到支持的浏览器类型有十几种,其中常用的有
chrome 谷歌,驱动下载地址,注意浏览器与驱动的版本要匹配,下面的浏览器也一样
firefox,火狐,驱动下载地址
ie,ie不好用,驱动下载地址
phantomjs,这是一个无界面的浏览器,特点是高效,后面我会有一篇博客专门介绍它。
safari,手机浏览器
驱动要放到环境变量的地址里,如 c://python2,或者把驱动的地址放到环境变量里
具体安装请百度,搜索 “selenium 浏览器驱动下载” 即可
1. 声明浏览对象
from selenium import webdriver #构造模拟浏览器 # firefox_login=webdriver.Ie() # Firefox() firefox_login=webdriver.Chrome()
这一步可设定无界面模式,即操作浏览器时,隐层浏览器
options = webdriver.ChromeOptions() options.add_argument(‘--headless‘) # 设置无界面 可选 firefox_login=webdriver.Chrome(chrome_options=options)
2. 访问页面
firefox_login.get(‘http://www.renren.com/‘) # firefox_login.maximize_window() # 窗口最大化,可有可无,看情况 firefox_login.minimize_window()
3. 查找元素并交互
firefox_login.find_element_by_id(‘email‘).clear() firefox_login.find_element_by_id(‘email‘).send_keys(‘xxx@sina.com‘)
元素查找方法汇总
find_element_by_name
find_element_by_id
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
以上是单元素查找,多元素把 element 变成 elements 即可。
还有一种较通用的方法
from selenium.webdriver.common.by import By 注意这里要导入 browser = webdriver.Chrome() browser.get("http://www.taobao.com") input_first = browser.find_element(By.ID,"q") ID可以换成其他
4. 操作浏览器
firefox_login.find_element_by_id(‘login‘).click()
可将操作放入动作链中串行执行
from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = "http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable" browser.get(url)
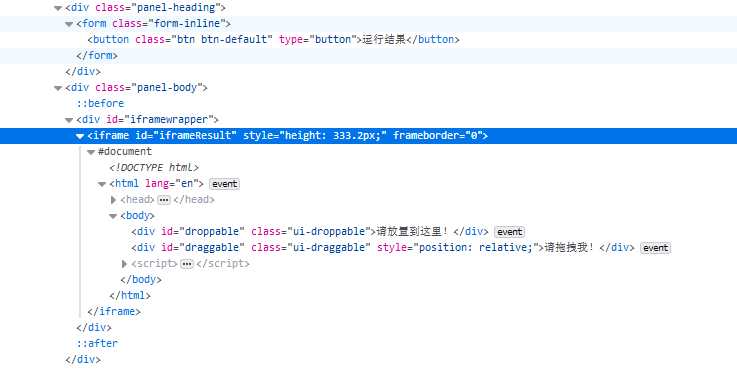
# browser.switch_to.frame(‘iframeResult‘) source = browser.find_element_by_css_selector(‘#draggable‘) target = browser.find_element_by_css_selector(‘#droppable‘) actions = ActionChains(browser) actions.drag_and_drop(source, target) actions.perform()
上面实现了一个元素拖拽的功能
执行 js 命令
直接用js命令操作浏览器
from selenium import webdriver browser = webdriver.Chrome() browser.get("http://www.zhihu.com/explore") browser.execute_script(‘window.scrollTo(0, document.body.scrollHeight)‘) browser.execute_script(‘alert("To Bottom")‘)
5. 输出并关闭
print(firefox_login.current_url) print(firefox_login.page_source) #浏览器退出 # firefox_login.close() firefox_login.quit()
获取元素属性
get_attribute(‘class‘)
logo = browser.find_element_by_id(‘zh-top-link-logo‘) print(logo.get_attribute(‘class‘))
获取文本 logo.text
获取id logo.id
获取位置 logo.location
获取标签名logo.tag_name
获取size logo.size
除了基础的操作外,还有很多特殊的应用场景需要处理。
很多网页中存在 frame 标签,要处理frame里面的数据,首先要切入frame,处理完了还要切出来。
切入 用 switch_to.frame,切出 用 switch_to.parent_frame
示例
# encoding:utf-8 import time from selenium import webdriver from selenium.common.exceptions import NoSuchElementException browser = webdriver.Chrome() url = ‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘ browser.get(url) browser.switch_to.frame(‘iframeResult‘) # iframeResult 是 iframe 的 id 进入frame source = browser.find_element_by_css_selector(‘#draggable‘) print(source) try: logo = browser.find_element_by_class_name(‘logo‘) except NoSuchElementException: print(‘NO LOGO‘) browser.switch_to.parent_frame() # 退出 frame logo = browser.find_element_by_class_name(‘logo‘) print(logo) print(logo.text)
上面url的部分源码
在操作浏览器时经常要等待,selenium 也有等待方法,分为显式等待和隐式等待
隐式等待
from selenium import webdriver browser = webdriver.Chrome() browser.implicitly_wait(100) # browser.get(‘https://www.zhihu.com/explore‘) input = browser.find_element_by_class_name(‘zu-top-add-question‘) print(input)
显式等待
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() browser.get(‘https://www.taobao.com/‘) wait = WebDriverWait(browser, 100) # input = wait.until(EC.presence_of_element_located((By.ID, ‘q‘))) button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ‘.btn-search‘))) print(input, button)
显式等待和隐式等待都是无阻塞的,即响应就继续,不同的是,显示等待需要设定响应条件,如获取某元素。
常用判断条件
title_is:判断当前页面的title是否等于预期 title_contains:判断当前页面的title是否包含预期字符串 presence_of_element_located:判断某个元素是否被加到了dom树里,并不代表该元素一定可见 visibility_of_element_located:判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0 visibility_of:跟上面的方法做一样的事情,只是上面的方法要传入locator,这个方法直接传定位到的element就好了 presence_of_all_elements_located:判断是否至少有1个元素存在于dom树中。举个例子,如果页面上有n个元素的class都是‘column-md-3‘,那么只要有1个元素存在,这个方法就返回True text_to_be_present_in_element:判断某个元素中的text是否 包含 了预期的字符串 text_to_be_present_in_element_value:判断某个元素中的value属性是否包含了预期的字符串 frame_to_be_available_and_switch_to_it:判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False invisibility_of_element_located:判断某个元素中是否不存在于dom树或不可见 element_to_be_clickable - it is Displayed and Enabled:判断某个元素中是否可见并且是enable的,这样的话才叫clickable staleness_of:等某个元素从dom树中移除,注意,这个方法也是返回True或False element_to_be_selected:判断某个元素是否被选中了,一般用在下拉列表 element_located_to_be_selected element_selection_state_to_be:判断某个元素的选中状态是否符合预期 element_located_selection_state_to_be:跟上面的方法作用一样,只是上面的方法传入定位到的element,而这个方法传入locator alert_is_present:判断页面上是否存在alert
更多参考:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
wait.until(EC.text_to_be_present_in_element_value((‘id‘, ‘inputSearchCity‘), u‘西安‘))
forward/back
import time from selenium import webdriver browser = webdriver.Chrome() browser.get(‘https://www.baidu.com/‘) browser.get(‘https://www.taobao.com/‘) browser.back() time.sleep(1) browser.forward() browser.close()
get_cookies()
delete_all_cookies()
add_cookie()
from selenium import webdriver browser = webdriver.Chrome() browser.get(‘https://www.zhihu.com/explore‘) print(browser.get_cookies()) browser.add_cookie({‘name‘: ‘name‘, ‘domain‘: ‘www.zhihu.com‘, ‘value‘: ‘zhaofan‘}) print(browser.get_cookies()) browser.delete_all_cookies() print(browser.get_cookies())
暂略
暂略
参考资料:
https://selenium-python.readthedocs.io/ 英文官方教程
https://selenium-python.readthedocs.io/api.html webdriver API
《Python爬虫开发与项目实战》 pdf电子书
http://www.cnblogs.com/zhaof/p/6953241.html 很好的教程
https://www.jianshu.com/p/47853fdb613b 等待
https://blog.csdn.net/qq_38316655/article/details/81989232 等待实例
标签:clear net document btn 直接 变量 mod 自动化 enc
原文地址:https://www.cnblogs.com/yanshw/p/10852860.html