标签:方式 主机 种类型 服务注册 可用性 info 问题 OLE 通信
在传统的系统部署中,服务运行在一个固定的已知的 IP 和端口上,如果一个服务需要调用另外一个服务,可以通过地址直接调用,但是,在虚拟化或容器话的环境中,服务实例的启动和销毁是很频繁的,服务地址在动态的变化,如果需要将请求发送到动态变化的服务实例上,至少需要两个步骤:
服务注册 — 存储服务的主机和端口信息
服务发现 — 允许其他用户发现服务注册阶段存储的信息
服务发现的主要优点是可以无需了解架构的部署拓扑环境,只通过服务的名字就能够使用服务,提供了一种服务发布与查找的协调机制。服务发现除了提供服务注册、目录和查找三大关键特性,还需要能够提供健康监控、多种查询、实时更新和高可用性等。
服务发现的主要好处是「零配置」:不用使用硬编码的网络地址,只需服务的名字(有时甚至连名字都不用)就能使用服务。在现代的体系架构中,单个服务实例的启动和销毁很常见,所以应该做到:无需了解整个架构的部署拓扑,就能找到这个实例。
在一个分布式系统中,服务注册与发现组件主要解决两个问题:服务注册和服务发现。
除此之外,服务注册与发现需要关注监控服务实例运行状态、负载均衡等问题。
负载均衡:同一服务可能同时存在多个实例,需要正确处理对该服务的负载均衡。
CAP原则,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性),不能同时成立。
一般来讲,基于网络的不稳定性,分布容错是不可避免的,所以我们默认CAP中的P总是成立的。
一致性的强制数据统一要求,必然会导致在更新数据时部分节点处于被锁定状态,此时不可对外提供服务,影响了服务的可用性,反之亦然。因此一致性和可用性不能同时满足。
我们接下来介绍的服务注册和发现组件中,Eureka满足了其中的AP,Consul和Zookeeper满足了其中的CP。
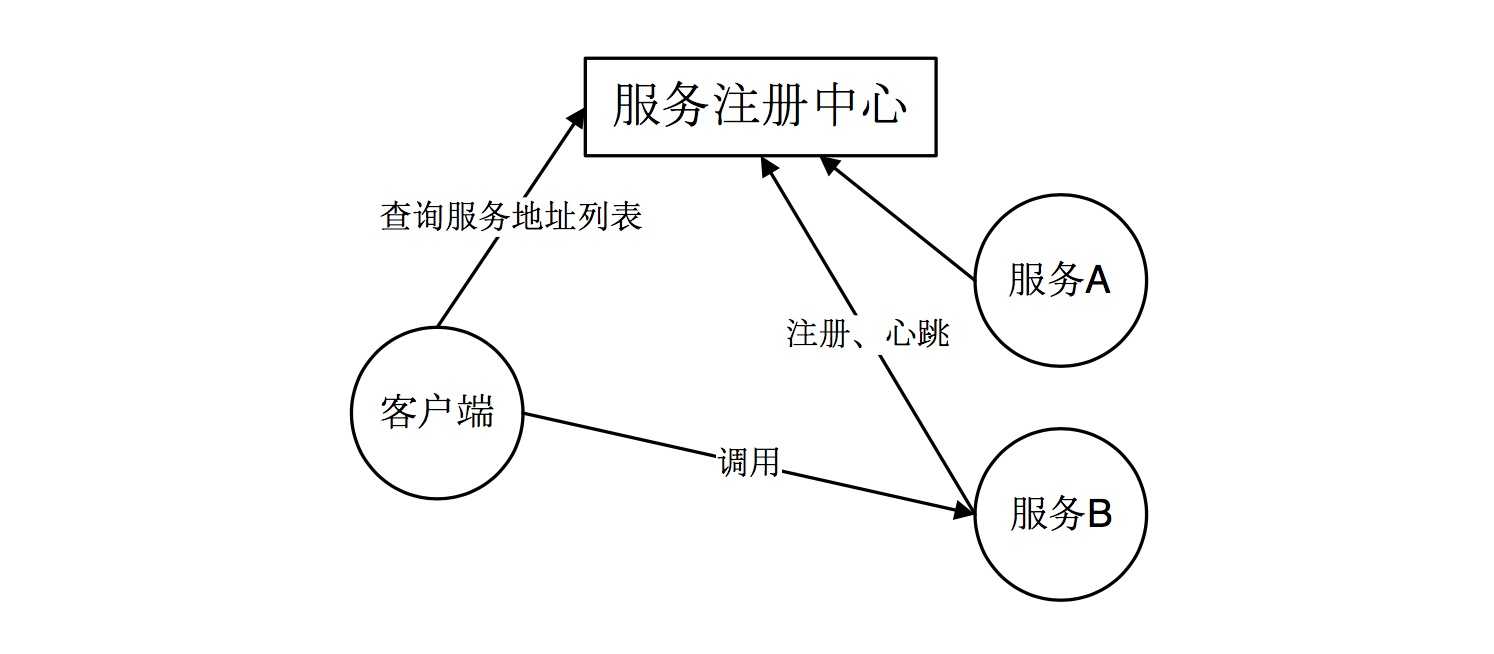
在使用客户端发现方式时,客户端通过查询服务注册中心,获取可用的服务的实际网络地址(IP 和端口)。然后通过负载均衡算法来选择一个可用的服务实例,并将请求发送至该服务。
优点:架构简单,扩展灵活,方便实现负载均衡功能。
缺点:强耦合,有一定开发成本。
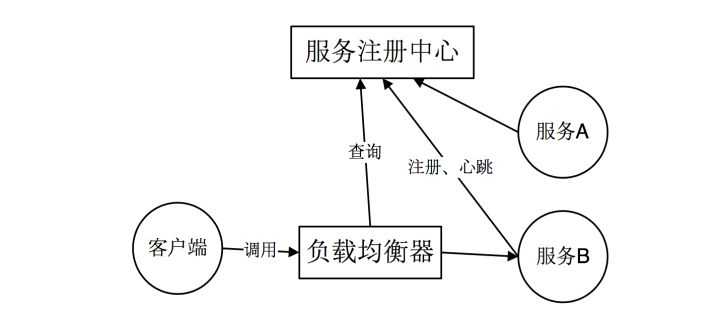
客户端向load balancer 发送请求。load balancer 查询服务注册中心找到可用的服务,然后转发请求到该服务上。和客户端发现一样,服务都要到注册中心进行服务注册和注销。
优点:服务的发现逻辑对客户端是透明的。
缺点:需要额外部署和维护高可用的负载均衡器。
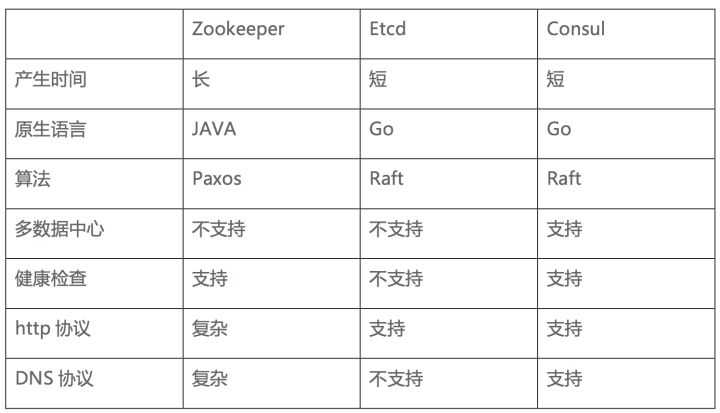
常见服务发现框架 Consul、 ZooKeeper以及Etcd
ZooKeeper 是这种类型的项目中历史最悠久的之一,它起源于 Hadoop。它非常成熟、可靠,被许多大公司(YouTube、eBay、雅虎等)使用。
Etcd是一个采用 HTTP 协议的健/值对存储系统,它是一个分布式和功能层次配置系统,可用于构建服务发现系统。其很容易部署、安装和使用,提供了可靠的数据持久化特性。搭配一些第三方工具,etcd(健/值对存储系统)+ Registrator(服务注册器) + Confd(轻量级的配置管理工具)
Consul 是强一致性的数据存储,使用 Gossip 形成动态集群。它提供分级键/值存储方式,不仅可以存储数据,而且可以用于注册器件事各种任务,从发送数据改变通知到运行健康检查和自定义命令
标签:方式 主机 种类型 服务注册 可用性 info 问题 OLE 通信
原文地址:https://www.cnblogs.com/Yemilice/p/10923331.html