标签:play 虚拟 ted ffffff 模板 -- code size mon
前期准备:创建一个新用户hadoop
$ sudo useradd -m hadoop -s /bin/bash
设置密码
$ sudo passwd hadoop #也可以设置你喜欢的
需输入两次密码
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
提升hadoop用户的权限,编辑:
$ vi /etc/sudoers
按 :92 enter,在root ALL=(ALL) ALL下,添加
hadoop ALL=(ALL) ALL
保存,退出,切换至hadoop用户
su hadoop
配置SSH免密登录
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 755 ~/.ssh
$ chmod 0600 ~/.ssh/authorized_keys
验证ssh
$ ssh localhost
JDK安装
先查看是否安装,如果安装了,先卸载当前版本
下载JDK
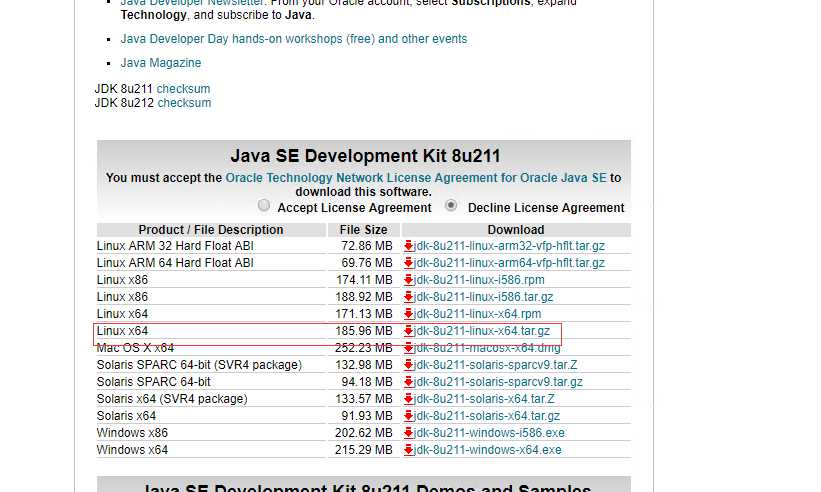
1、方法一:在线下载
$ cd /opt/software #software是我自己建的一个存放安装包的文件夹
$ wget https://download.oracle.com/otn/java/jdk/8u211-b12/478a62b7d4e34b78b671c754eaaf38ab/jdk-8u211-linux-x64.tar.gz?AuthParam=1558191965_2d075bd3a41704e8e152ef0cfd98ba3e
$ sudo tar -zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local/ #解压到/usr/local/ 这个路径下
2、方法二:在本机上下载,然后直接用工具拖进去,解压方法相同
添加环境变量
$ vi /etc/profile.d/en.sh
切换至编辑模式,输入以下内容:
export JAVA_HOME=/usr/local/jdk #这是我重命名之后的,原来是jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source配置文件生效
$ source /etc/profile.d/en.sh
输出JAVA_HOME路径,查看配置是否生效
$ echo $JAVA_HOME
输出以下内容说明配置已经生效
/usr/local/jdk1.8.0_211
查看是否java安装成功
$ java -version
显示以下信息说明安装成功
openjdk version "1.8.0_212"
OpenJDK Runtime Environment (build 1.8.0_212-8u212-b03-0ubuntu1.18.04.1-b03)
OpenJDK 64-Bit Server VM (build 25.212-b03, mixed mode)
安装Hadoop
与JDK相同,可以在线下载,也可以直接拖过去
解压
$ sudo tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local/ #解压到/usr
$ mv hadoop-2.7.1 hadoop # 重命名
$ cd /usr/local/hadoop
$ ./bin/hadoop version
#你将会看到类似内容:
Hadoop 2.7.1
Source code repository ………………………………(省略)
添加环境变量
$ vi /etc/profile.d/en.sh
#输入以下内容:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
$ source /etc/profile.d/en.sh
配置core-site.xml:
$ sudo vi /usr/local/hadoop/etc/hadoop/core-site.xml
#输入以下内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.
</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
$ source /etc/profile.d/en.sh
配置hadoop-env.sh
$ sudo vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
在里面添加,如果原来有,就注释或删掉
export JAVA_HOME=/usr/local/jdk
配置hdfs-site.xml:hdfs-site.xml文件中包含,如:复制数据的值,NameNode的路径,本地文件系统,要存储Hadoop基础架构的Datanode路径的信息
$ sudo vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
#写下以下 <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
配置完成后,执行NameNode的格式化
$ /usr/local/hadoop/bin/hdfs namenode -format
#出现类似输出,说明名称节点设置成功
19/05/19 11:13:33 INFO common.Storage: Storage directory /opt/module/hadoop-2.7.2/tmp/dfs/name has been successfully formatted.
19/05/19 11:13:33 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
19/05/19 11:13:33 INFO util.ExitUtil: Exiting with status 0
19/05/19 11:13:33 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop137/192.168.137.110
************************************************************/
#如果失败with status 后面为1
#可以先切换到root下,把/usr/local/hadoop/tmp下的tmp文件删除,再执行格式化
配置yarn-site.xml
换到hadoop用户下
$ sudo vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
#写下 <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
配置mapred-site.xml
(此文件用于指定MapReduce框架以使用。默认情况下Hadoop包含yarn-site.xml模板。首先,它需要从mapred-site.xml复制模板到mapred-site.xml文件,使用下面的命令来。)
sudo vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration> <!--模板中有!复制时不包含configuration标签--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
启动:/usr/local/hadoop/sbin/start-dfs.sh,出现类似输出,说明安装成功:
Starting namenodes on [localhost]
localhost: namenode is running as process 16525. Stop it first.
Starting datanodes
………………………………
通过jps查看是否启动成功
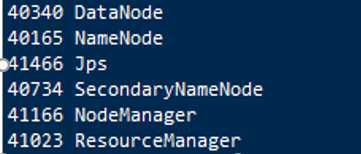
如果启动不成功,出现权限问题
运行以下命令,把hadoop目录所有用户改到hadoop上
sudo chown -R hadoop:root /usr/local/hadoop
再次运行
测试:
1、虚拟机内部测试:
(1)curl http://localhost:50070
(2)curl http://172.0.0.1:50070
(3)curl http://192.168.137.136:50070
如果发现无法访问,手动修改hdfs-site.xml, 修改hdfs-site.xml,添加如下,测试时把端口号换成9870
<property> <name>dfs.http.address</name> <value>0.0.0.0:9870</value> </property>
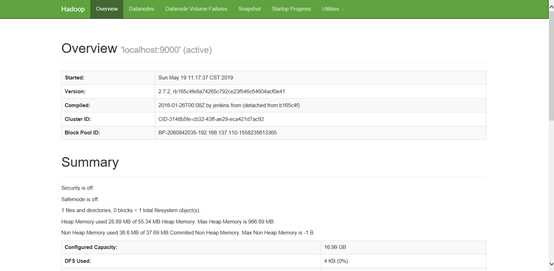
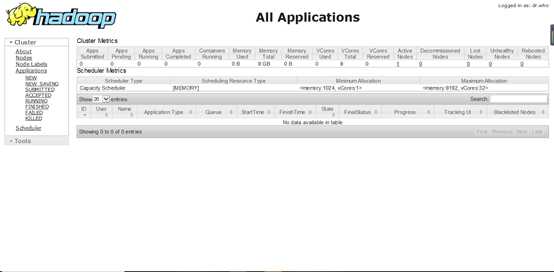
2、本地测试:
http://192.168.137.136:50070
http://192.168.137.136:8088/
标签:play 虚拟 ted ffffff 模板 -- code size mon
原文地址:https://www.cnblogs.com/Mu-Workstation/p/10924890.html