标签:理解 比较 art 技术 这一 大文件 理论 超级块 nbsp
上一讲,我们讲了Unix的本地文件系统和Linux的ext2文件系统。并对他们进行了简单的比较,发现基本相同。Unix文件系统的柱面组(cg,cylinder group)就是Linux下的块组(block group),因此柱面组信息块就是组块描述符。另外,Unix的柱面组信息块结构体包含位示图(bitmap),而ext2中的位图则单独列了出来,使得每个组块描述符是一样的。
这一讲,我们以ext2中的名词为准,看看在源码中这些名词(超级块,块组描述符,(inode)位示图,索引节点表,数据块)都是什么东西。
目标文件:Linux-2.6.0\include\linux\ext2_fs.h
超级块(superblock):ext2在磁盘上的超级块存放在一个ext2_super_block结构中。
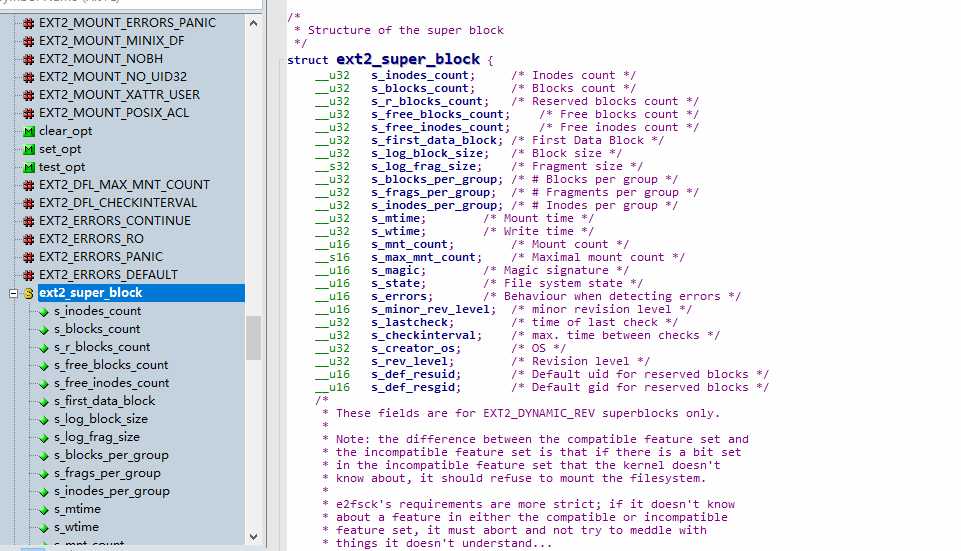
当我们点进__u8,__u16,__u32其实是使用typedef给 unsigned char, unsigned short以及unsigned int的别名,代表长度为8,16,以及32位的无符号数,而__s8等则代表有符号的数。 这个里面包含了全部ext2的超级块的属性。然而实际上,我们不能能把全部的超级块内容都放入内存中,内存中关于ext2的超级块信息放在Linux-2.6.0\include\linux\ext2_fs_sb.h。(如下图)
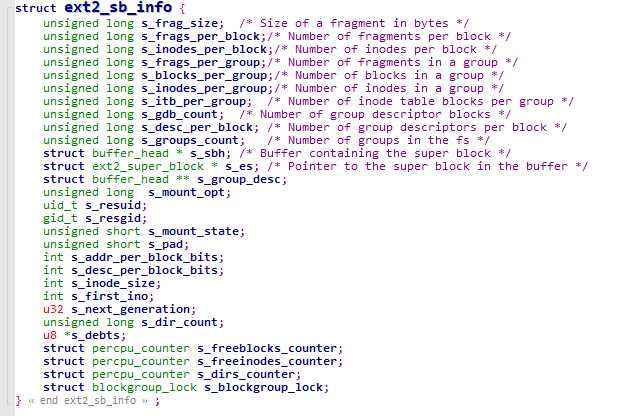
块组描述符(block group desc):是一个ext2_group_desc结构体
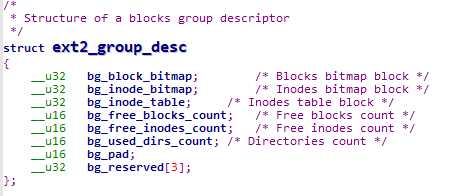
当分配新索引节点和数据块时,会用到bg_free_blocks_count,bg_free_inode_count和bg_used_dirs_count字段。
其中位示图就是这个结构体中的bg_block_bitmap和bg_inode_bitmap。位示图是位的序列,其中值0表示对应的索引节点块或者数据块是空闲的,1表示占用。每个位图必须存放在一个单独的块中,又因为一个块可以是1024,2048或4096字节,因此一个单独的位图描述8192,16384或32768个块的状态。
索引节点表(icommon):由一连串连续的块组成,其中每个块包含索引节点的一个预定义号。索引节点表第一个块的块号存放在组描述的bg_inode_table字段中。
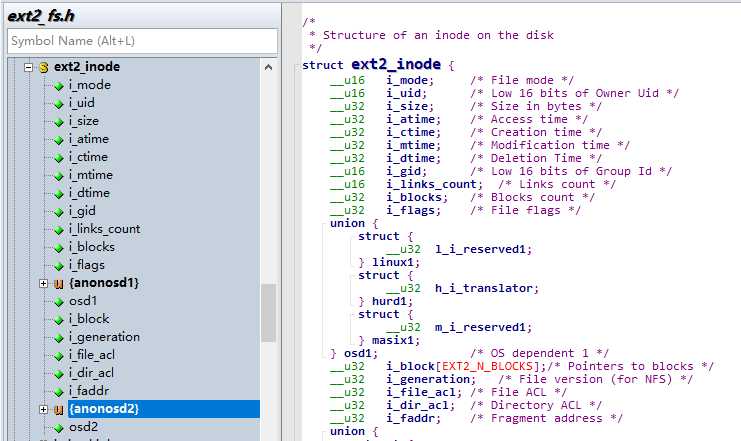
所有索引节点的大小相同,即128字节。一个1024字节的块开业包含8个索引节点。为了计算出索引节点表占用了多少块,用一个组中的索引节点总数(存放在超级块的s_inodes_per_group中)除以每块中的索引节点数。
这里的icommon与VFS中索引节点对象的字段相似。不相同的主要处理块的分配。
索引节点表主要包括的属性有mode(文件类型0-7),i_size(以字节为单位的文件长度),UID,GID,a/c/m/dtime,硬链接数,文件的数据块数(i_blocks),文件标志(flags),指向数据块的指针(i_block[EXT2_N_BLOCKS])等。
1、i_size和i_blocks的区别?——文件的洞 2、指向数据块的指针是如何指向数据块的?——数据块索引节点表
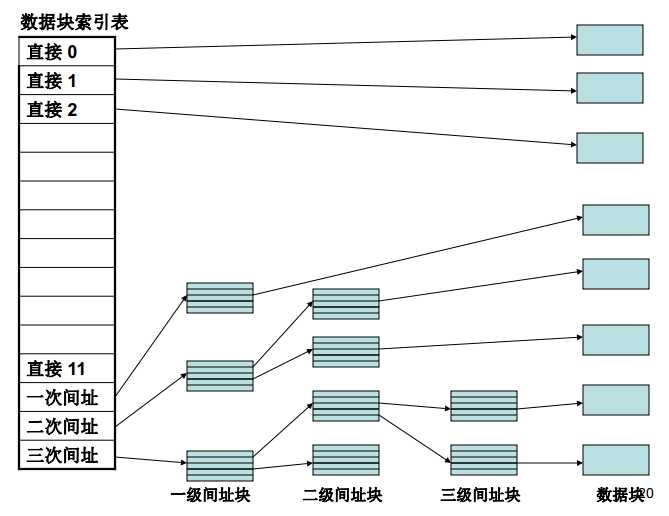
数据块索引节点表(数据块寻址)
上面的i_blocks和i_block[EXT2_N_BLOCKS]共同组成了数据块索引节点表。
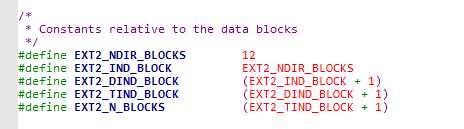
i_block中有EXT2_N_BLOCKS个元素,且包含逻辑块号的数组。我们根据ext2_fs.h中的定义可知EXT2_N_BLOCKS=15(如下图),而这15个元素有4种不同的类型,如下图所示:
在申请新磁盘块的时候,虽然理论上物理块之间不连续,但是为了提高效率,ext2采用了相应的策略让同一文件的块尽可能连续靠近。
注意这种机制是如何支持小文件的。如果文件需要的数据块小于12,那么两次访问磁盘就可以检索到任何数据:一次是读磁盘索引节点i_block数组的一个元素,另一次是读所需要的数据块。对于大文件来说,可能需要3-4次的磁盘访问才能找到需要的块。实际上,这是一种最坏的估计,因为目录项、缓冲区及页高速缓存都有助于极大地减少实际访问磁盘的次数。
要注意文件系统的块大小是如何影响寻址机制的,Ext2的块大小是允许调整的,因为大的块大小允许Ext2把更多的逻辑块号存放在一个单独的块中。表9.2显示了对每种块大小和每种寻址方式所存放文件大小的上限。例如,如果块的大小是1024字节,并且文件包含的数据最多为268KB,那么,通过直接映射可以访问文件最初的12KB数据,通过简单的间接映射可以访问剩余的13KB到268KB的数据。对于4096字节的块,两次间接就完全满足了对2GB文件的寻址(2GB是32位体系结构上的Ext2文件系统所允许的最大值)。可寻址的文件数据块大小的界限(如下表):
文件的洞
文件的洞(file hole)是普通文件系统的一部分,它是一些空字符但没有存放在磁盘的任何数据块中。洞是Unix文件一直存在的一个特点。下列的Unix命令创建了第一个字节是洞的文件:
$ echo -n "X" | dd of=/tmp/hole bs=1024 seek=6
/tmp/hole有6145个字符(6144个空字符+X),然而,这个文件在磁盘上只占一个数据块。
引入文件的洞是为了避免磁盘空间的浪费。文件洞在Ext2中的实现是基于动态数据块的分配的:只有当进程需要向一个块写数据时,才真正把这个块分配给文件。每个索引节点的i_size字段定义程序锁看到的文件大小,包括洞,而i_blocks字段存放分配给文件有效的数据块数(以512字节为单位)
无论是在VFS还是在UFS,还是在别的什么文件系统,我们使用记住,文件系统中最重要的两个component是inode table和data block。一个用于文件索引节点号,一个用于放数据块。在UFS中,无论是超级块,还是组块描述符还是data block bitmap以及i-node bitmap都是为这两者服务的,用来说明两者的对应关系(指针+文件占用block数目,数据块索引表),两者是谁的问题(dentry,inode)。
参考:
《深入理解Linux内核》
https://blog.csdn.net/u014659656/article/details/46746395
标签:理解 比较 art 技术 这一 大文件 理论 超级块 nbsp
原文地址:https://www.cnblogs.com/SsoZhNO-1/p/10859848.html