标签:联系 理论 完成 pre 原子性 iso 环境 不能 失败
Eureka遵守AP,Zookeeper遵守CP
RDBMS(oracle/mysql、sqlServer) ====> ACID, 关系型数据库遵循ACID原则;
NoSQL(redis/mongodb)====> CAP
ACID分别为:
原子性(Automicity):事务里面的所有操作,要么全部做完,要么全不做;事务成功的条件是事务里面的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚;
一致性(Consistency):数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束;也就是说:如果事务是并发多个,系统也必须如同串行事务一样操作。其主要特征是保护性和不变性(Preserving an Invariant),以转账案例为例,假设有五个账户,每个账户余额是100元,那么五个账户总额是500元,如果在这个5个账户之间同时发生多个转账,无论并发多少个,比如在A与B账户之间转账5元,在C与D账户之间转账10元,在B与E之间转账15元,五个账户总额也应该还是500元,这就是保护性和不变性。
隔离性(Isolation): 并发的事务之间不会互相影响;
持久性(Durability):在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
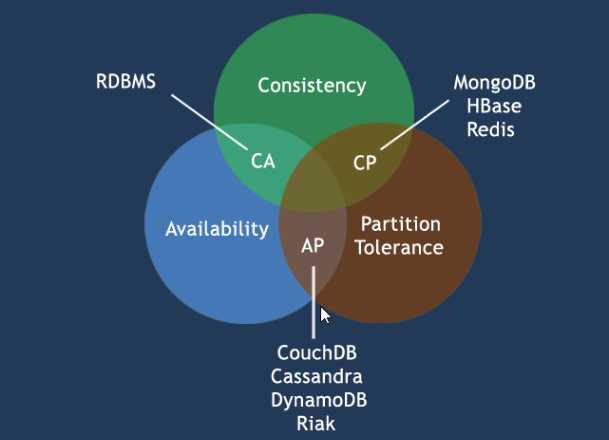
CAP分别为:强制一致性(Consistency),可用性(Availability),分区容错性(Partition tolerance):
CAP的3进2:任何一个分布式系统中,无法同时满足CAP3个原则,最多只能满足其中的2个;
CAP的理论核心:任何一个分布式系统中,无法同时满足强制一致性、可用性、分区容错性这3个需求;因此,根据CAP原则将NoSQL 数据库分成满足CA原则、CP原则、AP原则三大类:
CA原则:单点集群,满足一致性、可用性的原则,通常在扩展上不太强;
CP原则:满足一致性、分区容错的系统,通常性能不是特别高;
AP原则:满足可用、分区容错的系统,通常对一致性要求低一点;
由于当前的网络硬件肯定会出现延迟丢包的问题,所以分区容错性是我们必须实现的,所以分布式系统只能在强制一致性和可用性中权衡;
因此:Zookeeper保证的是CP,Eureka保证的是AP;
当向注册中心查询服务列表时,我们可以容忍服务返回的是几分钟之前的数据,但是我们不能容忍服务之间Down掉不可用。也就是说服务的注册功能对可用性的要求高于一致性。
但是Zookeeper中会出现一种情况,当master节点因为网络故障和其他节点失去联系了时,剩余的节点会重新选举leader。但是选举leader的时间太长,30~120s,而且选举期间整个Zookeeper集群是不可用的,这就导致选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得Zookeeper的master失去联系可能性是很大的,虽然最后服务能够恢复,但是较长时间的选举导致注册的长期不可用是不能容忍的;
Eureka的各个节点是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询的服务。Eureka的客户端在向某个Eureka注册的时候,若发现连接失败,则会自动切换至其他节点,只要一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查询到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内,超过85%的节点都没有正常的心跳,那么Eureka就认为客户端和注册中心之间出现了网络故障,此时会出现以下情况:
(1)Eureka不再从注册中心表中移除因为长时间没有收到心跳而应该过期的服务;
(2)Eureka仍然能够接收新的服务注册和查询的请求,但是不会被同步到其他节点上去(即保证当前节点依然可用);
(3)当网络稳定时,当前实例新的注册信息会被同步到其他节点上去;
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会向Zookeeper那样使整个注册服务瘫痪;
标签:联系 理论 完成 pre 原子性 iso 环境 不能 失败
原文地址:https://www.cnblogs.com/yufeng218/p/10928323.html