标签:柯里化 大于 rop 开始 on() date today map red
一、字符串
模版字符串:反引号(`)标识。
$(‘#result‘).append(`
There are <b>${basket.count}</b> items
in your basket, <em>${basket.onSale}</em>
are on sale!
`);
变量嵌入(定义变量,使用$ 获取):
// 字符串中嵌入变量
let name = "Bob", time = "today";
`Hello ${name}, how are you ${time}?`
使用任意表达式、调用函数
let x = 1;
let y = 2;
`${x} + ${y} = ${x + y}`
// "1 + 2 = 3"
`${x} + ${y * 2} = ${x + y * 2}`
// "1 + 4 = 5"
let obj = {x: 1, y: 2};
`${obj.x + obj.y}`
// "3"
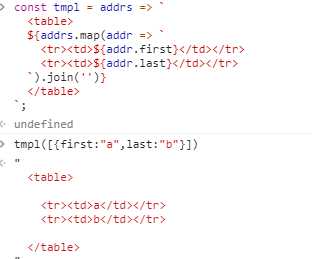
标签模块:
在函数名后,该函数会处理此模块字符串
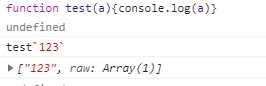
如果模版字符串含有变量,则会先执行模版字符串,在执行函数。
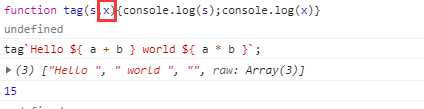
上面代码中,tag函数的第一个参数strings,有一个raw属性,也指向一个数组。该数组的成员与strings数组完全一致。比如,strings数组是["First line\nSecond line"],那么strings.raw数组就是["First line\\nSecond line"]。两者唯一的区别,就是字符串里面的斜杠都被转义了。比如,strings.raw 数组会将\n视为\\和n两个字符,而不是换行符。这是为了方便取得转义之前的原始模板而设计的。
新增方法:
1.fromCodePoint:Unicode 码点返回对应字符
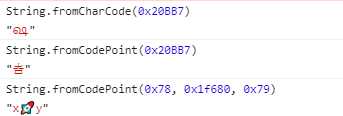
2.raw:该方法返回一个斜杠都被转义(即斜杠前面再加一个斜杠)的字符串,往往用于模板字符串的处理方法。
3.codePintAt:获取字符串的十进制码点
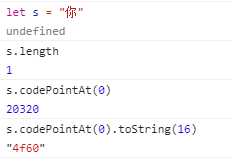
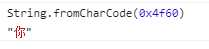
在获取码点的时候使用for..of,它会识别32位的UTF-16 字符。
4.normalize:语调
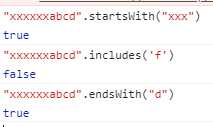
5.includes/startWith/endWith: 查找字符串
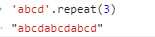
6.repeat:复制
7.padStart/padEnd:补全(如果不设置补全字符,则默认补全空格)
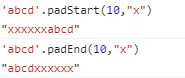
8.trimStart/trimEnd:消除空格(另外还发现了trimLeft 与trimRight,它们是start和end 的别名)

二、正则
如果RegExp构造函数第一个参数是一个正则对象,那么可以使用第二个参数指定修饰符。而且,返回的正则表达式会忽略原有的正则表达式的修饰符,只使用新指定的修饰符。
1.字符串使用:match、matchAll、replace、search、split
2.u修饰符:针对utf-16编码的unicode字符会正确处理
3.点字符:“.” 字符代表除换行符以外的任意单个字符。
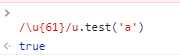
4.Unicode字符:大括号中的61为16进制表示
5.y修饰符:全局匹配(黏连)y修饰符会从上一个匹配的第一个位置开始匹配,而g修饰符只要保证剩余存在即可。
6.sticky:验证是否使用了y修饰符
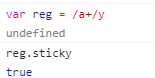
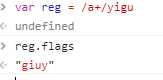
7.flags 属性:返回修饰符
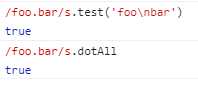
8.dotAll:任意字符
2018新增s修饰符,表示“.”代表一切字符(包括换行符、回车符、分隔符)
9.具名组匹配(对组设置别名,使用group获取)
const RE_DATE = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/; const matchObj = RE_DATE.exec(‘1999-12-31‘); const year = matchObj.groups.year; // 1999 const month = matchObj.groups.month; // 12 const day = matchObj.groups.day; // 31
10.引用:使用\K<组名>重复使用组
const RE_TWICE = /^(?<word>[a-z]+)!\k<word>$/; RE_TWICE.test(‘abc!abc‘) // true RE_TWICE.test(‘abc!ab‘) // false
11.matchAll:返回匹配到的数组
const string = ‘test1test2test3‘;
// g 修饰符加不加都可以
const regex = /t(e)(st(\d?))/g;
for (const match of string.matchAll(regex)) {
console.log(match);
}
// ["test1", "e", "st1", "1", index: 0, input: "test1test2test3"]
// ["test2", "e", "st2", "2", index: 5, input: "test1test2test3"]
// ["test3", "e", "st3", "3", index: 10, input: "test1test2test3"]
三、数值
1.二进制/八进制表示法:0b/0o
如果要将0b和0o前缀的字符串数值转为十进制,要使用Number方法。
Number(‘0b111‘) // 7 Number(‘0o10‘) // 8
2.isFinite/isNaN:检查数字是否是无限或者是无效NaN,传统方法先调用Number()将非数值的值转为数值,再进行判断,而这两个新方法只对数值有效。
3.isInteger:判断是否为整数
4.EPSLION:根据规格,它表示 1 与大于 1 的最小浮点数之间的差。
Math扩展:
1.trunc:除去一个数的小数部分,返回整数
2.sign:判断数为正数、负数、0
它会返回五种值。
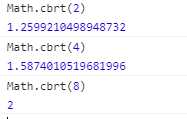
+1;-1;0;-0;NaN。3.cbrt:计算一个数的立方根
4.clz32:转换为32位整数,返回前导0的个数。
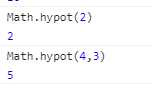
5.hypot:返回所有参数的平方和的平方根
6.指数运算符:** (多个指数运算从右开始计算)

**= 赋值运算符
let a = 1.5; a **= 2; // 等同于 a = a * a; let b = 4; b **= 3; // 等同于 b = b * b * b;
四、函数
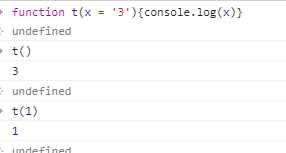
1.函数参数默认值
与解构赋值结合
function foo({x, y = 5}) {
console.log(x, y);
}
foo({}) // undefined 5
foo({x: 1}) // 1 5
foo({x: 1, y: 2}) // 1 2
foo() // TypeError: Cannot read property ‘x‘ of undefined
在解构赋值的基础上追加默认值
function foo({x, y = 5} = {}) {
console.log(x, y);
}
作用域:不多表,对于默认值,看准其内部解构,另外默认值的参数会形成单独的作用域,如果默认值是函数的话,需看清是否是声明变量还是向上提升,亦或是let声明的。在此推荐使用let 声明(如果默认参数是函数的话)
2.rest参数:可变参数(真正的数组而argument是一个类似数组的对象),在其后不能再有其他参数
function add(...values) {
let sum = 0;
for (var val of values) {
sum += val;
}
return sum;
}
add(2, 5, 3) // 10
3.name属性:返回函数的name(如果使用表达式的方式声明一个函数,那么在es6中返回的是这个变量的名称,如果具名函数,则返回具名函数的名称)
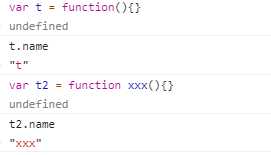
使用构造函数声明的function,那么为anonymous
使用bind 硬绑定的函数name属性会加上bound前缀~
function foo() {};
foo.bind({}).name // "bound foo"
(function(){}).bind({}).name // "bound "
4.箭头函数:=>
如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分,
如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回。
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号,否则会报错。
如果箭头函数只有一行语句,且不需要返回值:
let fn = () => void doesNotReturn();
简化回调(当只有一行代码的时候最明显):
// 正常函数写法
[1,2,3].map(function (x) {
return x * x;
});
// 箭头函数写法
[1,2,3].map(x => x * x);
箭头函数有几个使用注意点。
(1)函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。(内部作用域,个人理解与let相似,关于this之前文章中有提到)
(2)不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
关于this:具体涉及到作用域的问题,这里提到的是普通对象是没有内在作用域,但是函数有,所以在看阮一峰大神讲到这里的时候需要注意下。
关于嵌套(这里地方搞了我1个多小时),阮大神的一个例子:
const pipeline = (...funcs) => val => funcs.reduce((a, b) => b(a), val); const plus1 = a => a + 1; const mult2 = a => a * 2; const addThenMult = pipeline(plus1, mult2); addThenMult(5)
看的时候就懵逼了,翻译后如下:
var s = function(...funcs){function redu(a,b){return b(a)}; return function(val){ return funcs.reduce(redu,val) }}
var tt = s(function(a){return a+1},function(b){return b*2})
tt(3); // 8
回调函数套多了,容易懵。。 所以要记住 如果只有一行代码的箭头函数默认是return的。
5.尾调用:函数的最后一步调用另一个函数(需要return的,并且只是调用,没有其他操作才叫尾调用)
下面是引用:
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
尾递归:大家都知道如果操作不好很容易发生栈溢出。
阮大神的例子:
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
factorial(5) // 120 首先上面有其他操作,也就是需要n相乘,所以不是尾调用
//改为尾递归:
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5, 1) // 120 把操作丢到参数里,实现尾调用
柯里化:将多参数的函数转换成单参数的形式。(采用 ES6 的函数默认值)
function factorial(n, total = 1) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5) // 120
另外:ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
非严格模式:蹦床模式(名字不孬)
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
上面没有循环调用,而是执行一个新的函数。另外阮大神写了另一种方法通过状态,有兴趣的去翻翻。
!尾逗号:函数中的参数最后一个允许存在逗号!~ 不必每次修改代码的时候再在最后先加上,然后再写了~
function clownsEverywhere(
param1,
param2,
) { /* ... */ }
clownsEverywhere(
‘foo‘,
‘bar‘,
);
五、数组
六、对象
标签:柯里化 大于 rop 开始 on() date today map red
原文地址:https://www.cnblogs.com/jony-it/p/10934139.html