首页
Web开发
Windows程序
编程语言
数据库
移动开发
系统相关
微信
其他好文
会员
首页
>
其他好文
> 详细
EMC存储Raid故障数据分析报告
时间:
2019-05-28 12:37:56
阅读:
123
评论:
0
收藏:
0
[点我收藏+]
标签:
技术
code
崩溃
个数
校验
报错
类型
硬盘掉线
alt
一、故障描述
用户的EMC FC AX-4存储出现崩溃现象,整个存储空间由12块1TB STAT的硬盘组成的,其中10块硬盘组成一个RAID5的阵列,其余两块做成热备盘使用。由于RAID5阵列中出现2块硬盘损坏,而此时只有一块热备盘成功激活,因此导致RAID5阵列瘫痪,上层LUN无法正常使用。
二、检测磁盘
由于存储是因为某些磁盘掉线,从而导致整个存储不可用。因此接收到磁盘以后先对所有磁盘做物理检测,检测完后发现没有物理故障。接着使用坏道检测工具检测磁盘坏道,发现也没有坏道。
三、备份数据
考虑到数据的安全性以及可还原性,在做数据恢复之前需要对所有源数据做备份,以防万一其他原因导致数据无法再次恢复。使用winhex将所有磁盘都镜像成文件,由于源磁盘的扇区大小为520字节,因此还需要使用特殊工具将所有备份的数据再做520 to 512字节的转换。
四、故障分析及恢复过程
1、分析故障原因
由于前两个步骤并没有检测到磁盘有物理故障或者是坏道,由此推断可能是由于某些磁盘读写不稳定导致故障发生。因为EMC控制器检查磁盘的策略很严格,一旦某些磁盘性能不稳定,EMC控制器就认为是坏盘,就将认为是坏盘的磁盘踢出RAID组。而一旦RAID组中掉线的盘到达到RAID级别允许掉盘的极限,那么这个RAID组将变的不可用,上层基于RAID组的LUN也将变的不可用。目前初步了解的情况为基于RAID组的LUN只有一个,分配给SUN小机使用,上层文件系统为ZFS。
2、分析RAID组结构
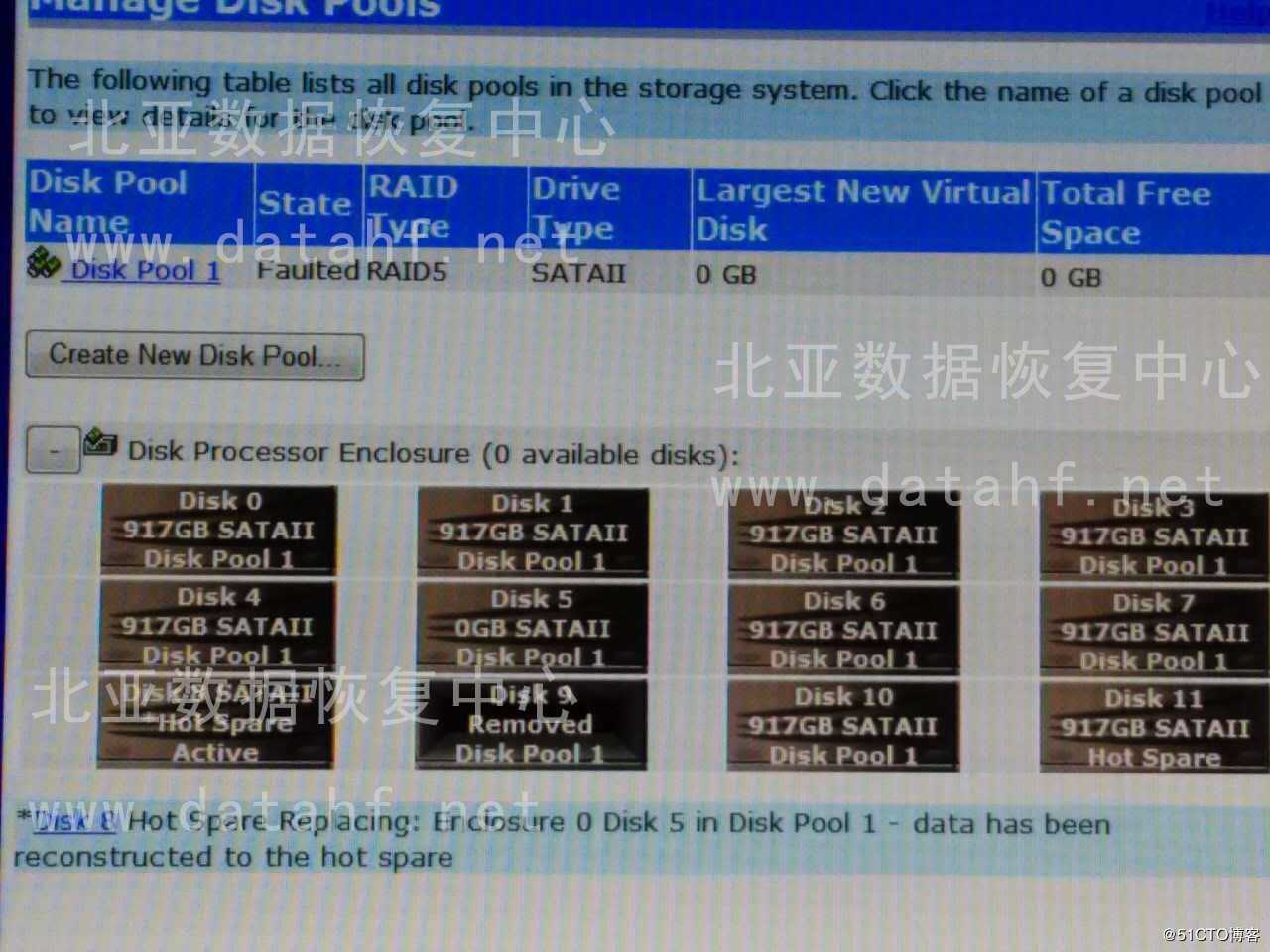
EMC存储的LUN都是基于RAID组的,因此需要先分析底层RAID组的信息,然后根据分析的信息重构原始的RAID组。分析每一块数据盘,发现8号盘和11号盘完全没有数据,从管理界面上可以看到8号盘和11号盘都属于Hot Spare,但8号盘的Hot Spare替换了5号盘的坏盘。因此可以判断虽然8号盘的Hot Spare虽然成功激活,但由于RAID级别为RAID5,此时RAID组中还缺失一块硬盘,所以导致数据没有同步到8号硬盘中。继续分析其他10块硬盘,分析数据在硬盘中分布的规律,RAID条带的大小,以及每块磁盘的顺序。
3、分析RAID组掉线盘
根据上述分析的RAID信息,尝试通过北亚自主开发的RAID虚拟程序将原始的RAID组虚拟出来。但由于整个RAID组中一共掉线两块盘,因此需要分析这两块硬盘掉线的顺序。仔细分析每一块硬盘中的数据,发现有一块硬盘在同一个条带上的数据和其他硬盘明显不一样,因此初步判断此硬盘可能是最先掉线的,通过北亚自主开发的RAID校验程序对这个条带做校验,发现除掉刚才分析的那块硬盘得出的数据是最好的,因此可以明确最先掉线的硬盘了。
4、分析RAID组中的LUN信息
由于LUN是基于RAID组的,因此需要根据上述分析的信息将RAID组重组出来。然后分析LUN在RAID组中的分配信息,以及LUN分配的数据块MAP。由于底层只有一个LUN,因此只需要分析一份LUN信息就OK了。然后根据这些信息使用北亚raid恢复(datahf.net)程序,解释LUN的数据MAP并导出LUN的所有数据。
五、解释ZFS文件系统并修复
1、解释ZFS文件系统
利用北亚数据恢复(datahf.net)自主开发的ZFS文件系统解释程序对生成的LUN做文件系统解释,发现程序在解释某些文件系统元文件的时候报错。迅速安排开发工程师对程序做debug调试,分析程序报错原因。接着安排文件系统工程师分析ZFS文件系统是否因为版本原因,导致程序不支持。经过长达7小时的分析与调试,发现ZFS文件系统因存储突然瘫痪导致其中某些元文件损坏,从而导致解释ZFS文件系统的程序无法正常解释。
2、修复ZFS文件系统
上述分析明确了ZFS文件系统因存储瘫痪导致部分文件系统元文件损坏,因此需要对这些损坏的文件系统元文件做修复,才能正常解析ZFS文件系统。分析损坏的元文件发现,因当初ZFS文件正在进行IO操作的同时存储瘫痪,导致部分文件系统元文件没有更新以及损坏。人工对这些损坏的元文件进行手工修复,保证ZFS文件系统能够正常解析。
六、导出所有数据
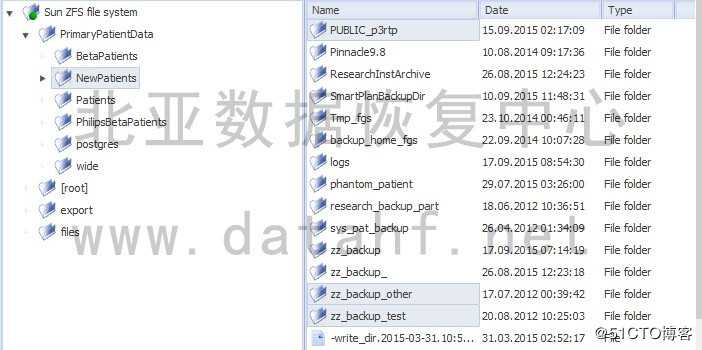
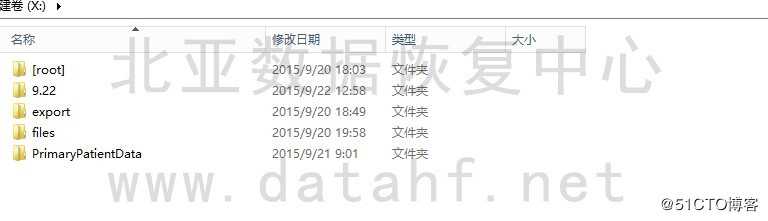
利用程序对修复好的ZFS文件系统做解析,解析所有文件节点及目录结构。部分文件目录截图如下:
七、验证最新数据
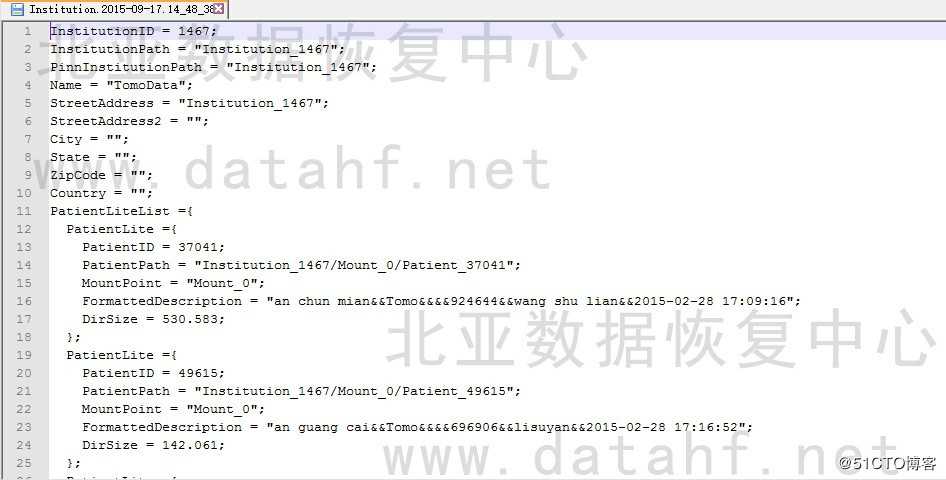
由于数据都是文本类型及DCM图片,需要搭建太多的环境。由用户方工程师指点某些数据进行验证,验证结果都没有问题,数据均完整。部分文件验证如下:
八、数据恢复结论
由于故障发生后保存现场环境良好,没用做相关危险的操作,对后期的数据恢复有很大的帮助。整个数据恢复过程中虽然遇到好多技术瓶颈,但也都一一解决。最终在预期的时间内完成数据恢复,经用户验收数据无误,至此数据恢复工作结束。
EMC存储Raid故障数据分析报告
标签:
技术
code
崩溃
个数
校验
报错
类型
硬盘掉线
alt
原文地址:https://blog.51cto.com/sun510/2401250
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年07月29日 (22)
2021年07月28日 (40)
2021年07月27日 (32)
2021年07月26日 (79)
2021年07月23日 (29)
2021年07月22日 (30)
2021年07月21日 (42)
2021年07月20日 (16)
2021年07月19日 (90)
2021年07月16日 (35)
周排行
更多
分布式事务
2021-07-29
OpenStack云平台命令行登录账户
2021-07-29
getLastRowNum()与getLastCellNum()/getPhysicalNumberOfRows()与getPhysicalNumberOfCells()
2021-07-29
【K8s概念】CSI 卷克隆
2021-07-29
vue3.0使用ant-design-vue进行按需加载原来这么简单
2021-07-29
stack栈
2021-07-29
抽奖动画 - 大转盘抽奖
2021-07-29
PPT写作技巧
2021-07-29
003-核心技术-IO模型-NIO-基于NIO群聊示例
2021-07-29
Bootstrap组件2
2021-07-29
友情链接
兰亭集智
国之画
百度统计
站长统计
阿里云
chrome插件
新版天听网
关于我们
-
联系我们
-
留言反馈
© 2014
mamicode.com
版权所有 联系我们:gaon5@hotmail.com
迷上了代码!