标签:程序编写 out 网络状态 cell 输入 requests end 教程 err
request库是一个简介且简单的处理HTTP请求的第三方库,它最大的优点是程序编写过程更接近正常URL访问过程。
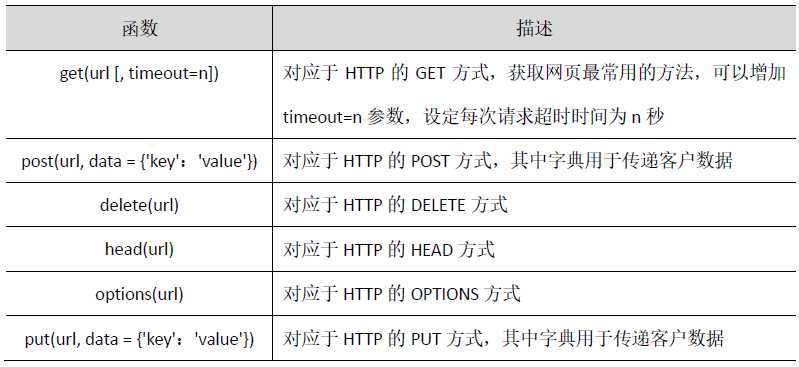
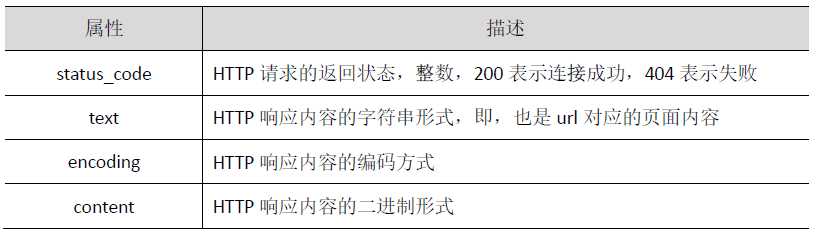

又称Beautiful Soup库或bs4库,用于解析和处理HTML和XML。它最大的优点是能根据HTML和XML语法建立解析树,进而高效解析其中的内容。
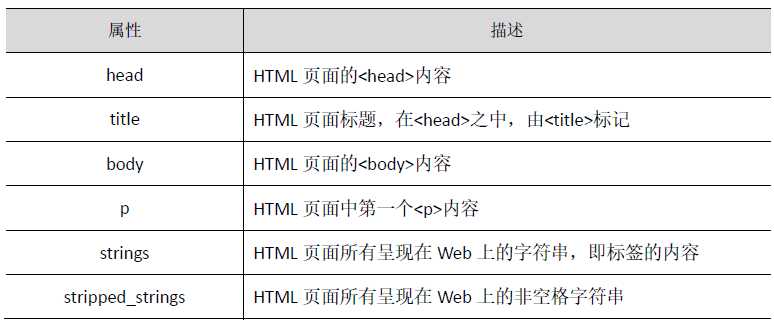
在BeautifulSoup4库中每一个Tag标签,也称为Tag对象
标签Tag有4个常用属性为 :


了解了基础知识,我们开始进行网络爬虫吧。
利用request库的get()函数对必应访问 20次,输入代码如下:
import requests def getHTMLText(url): print("第",i+1,"次访问") try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=‘utf-8‘ print("网络状态码:",r.status_code) print("text属性长度:",len(r.text)) print("content属性长度:",len(r.content)) return r.text except: return "error" url="http://cn.bing.com" #print(getHTMLText(url)) for i in range(20): print(getHTMLText(url))
结果(内容超级多,就展示一小片段):

运用菜鸟教程,输入代码获取一个简单的HTML页面
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题(学号30)</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> <tr> </table> </html>
得到的结果:

现在我们来爬一下中国大学排名网站
输入如下代码:
import requests from bs4 import BeautifulSoup allUniv = [] def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = ‘utf-8‘ return r.text except: return "" def fillUnivList(soup): data = soup.find_all(‘tr‘) for tr in data: ltd = tr.find_all(‘td‘) if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{:^4}{:^10}{:^5}{:^8}{:^10}".format("排名","学校名称","省市","总分","科研规模")) for i in range(num): u=allUniv[i] print("{:^4}{:^10}{:^5}{:^8}{:^10}".format(u[0],u[1],u[2],u[3],u[6])) def main(): url = ‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html‘ html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") fillUnivList(soup) printUnivList(10) main()
得出前10个大学排名的结果:
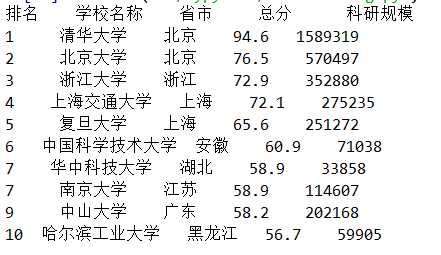
好!完成!(有点丑。。。哈哈)
标签:程序编写 out 网络状态 cell 输入 requests end 教程 err
原文地址:https://www.cnblogs.com/hjy567jiayouya/p/10947162.html