标签:没有 批量 机器学习算法 基本 适用于 bat 提取 基本概念 红点
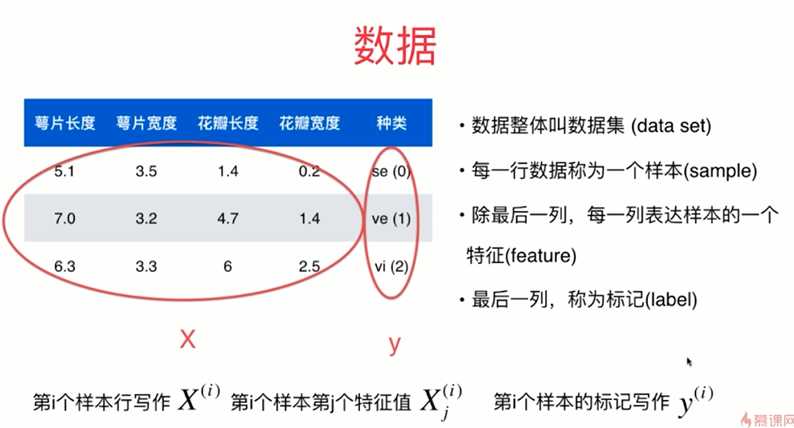
数据的整体叫做数据集 ( data set )
每一行数据被称为一个样本 ( sample )
最后一列, 称为标记 ( label )
表中的每个列都是一个特征, 用特征向量来表示一个特征值

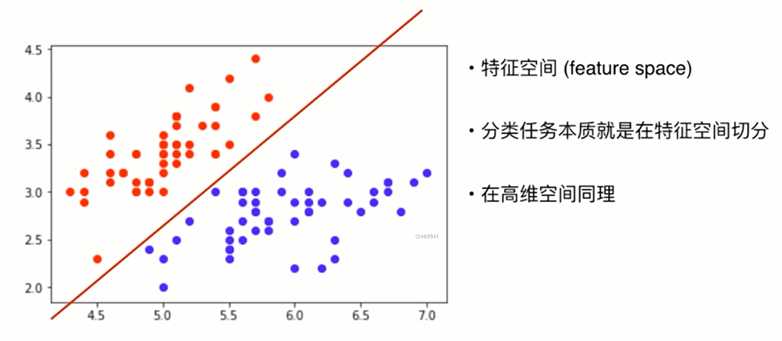
特征进行数据表示后的范围空间
此图中的形式是一个二维的特征空间, 高维的话则基于低维进行推导即可
很多的特征并不一定非要具体, 比如图像识别像素点








![]()
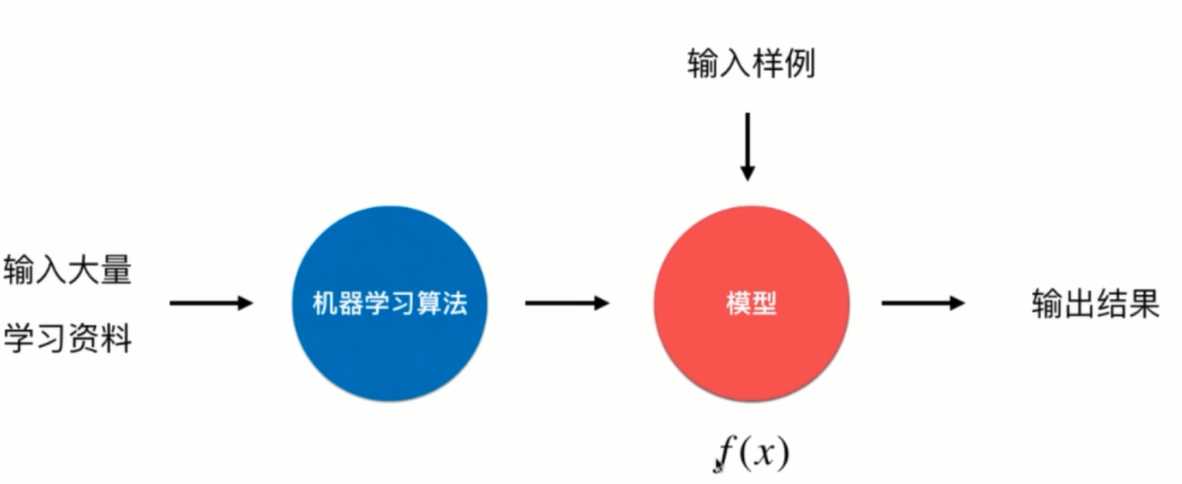
给机器的训练数据拥有 "标记" 或者 "答案"


给机器的训练数据没有 "标记" 或者 "答案"
对没有 "标记" 的数据进行分类 - 聚类分析
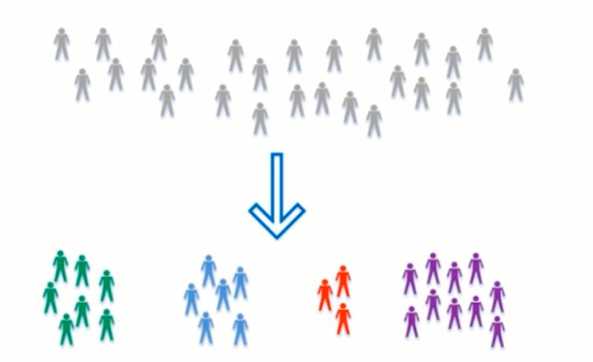
特征提取
信用卡的评级和人的身高如何关系?
特征压缩
PCA, 如下图这种二维的特征表示呈现出一种一维的线性表现, 这时可进行特征压缩
在尽量少损失特征信息的情况下, 将高维的特征向量压缩成低纬的特征向量, 大大提高效率而且不会降低质量
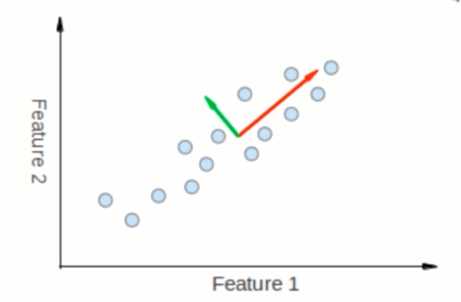
方便可视化
高维有点不好处理, 降维自然容易理解
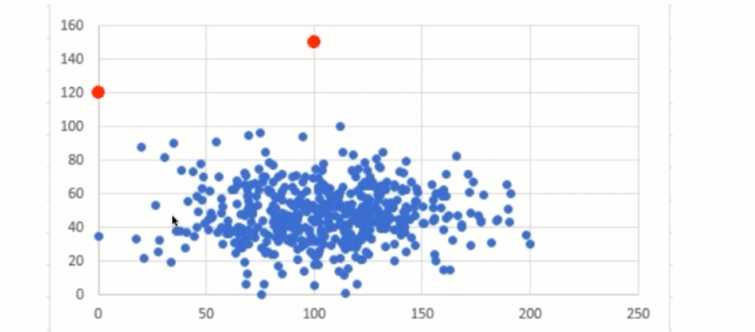
异常检测
如下图中的两个红点就很不适合整体的状态, 因此检测出后进行干预即可
给机器的训练数据一部分有 "标记" 或者 "答案", 另一部分没有
在现实中更常见, 各种原因都会产生标记的缺失

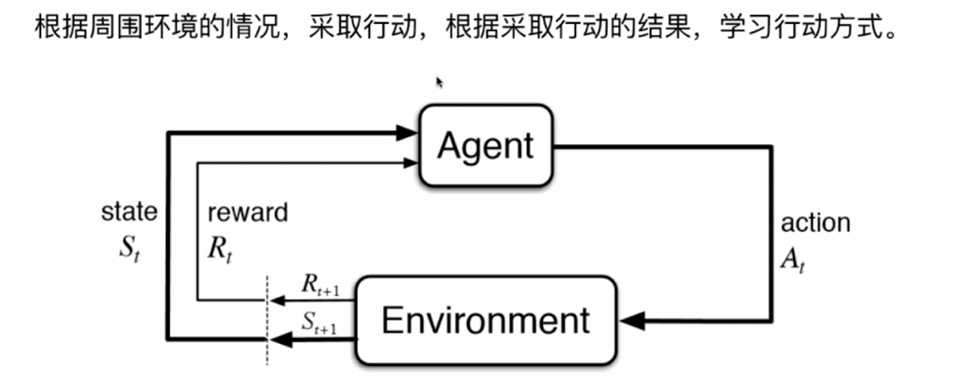
无人驾驶, 机器人等应用场景
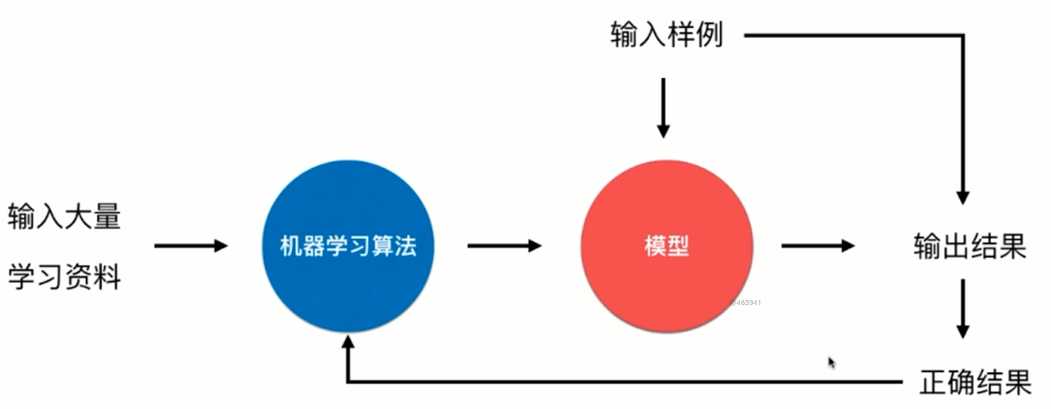
进行一个批次的数据样本进行学习以及辨识, 训练出的算法线上投入使用
不会对新的数据样本来更新自己的学习能力, 运算识别能力基于最初的效率和质量
优点 简单
如何适应环境变化 ? - 定时重新批量学习
缺点 每次重新批量学习, 运算量巨大, 某些环境变化快的情况下, 基本无望
进行一个批次的数据样本进行学习以及辨识, 训练出的算法线上投入使用
会对新的数据样本来更新自己的学习能力, 运算识别能力会基于最初的版本不断的自动优化提升适应当前的样本情景
优点 及时反映新的环境变化
新数据带来不好的变化 ? - 加强对数据的监控
其他 也适用于数据量巨大, 完全无法批量学习的环境
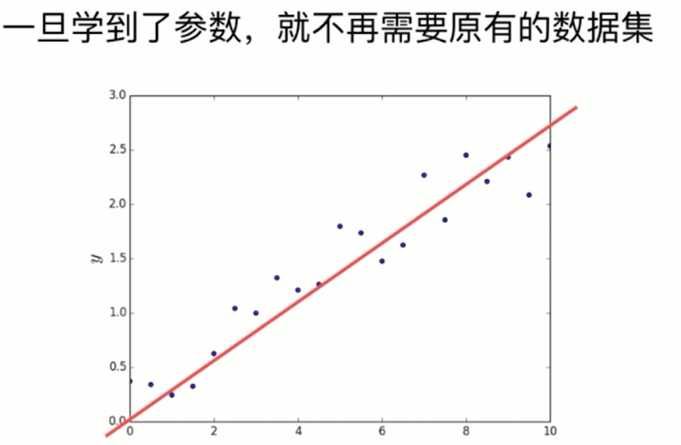
假设存在某个参数, 大量的数据集都是基于此参数存在的一个具体实例
分析数据集本身就是为了获得参数







![]()
标签:没有 批量 机器学习算法 基本 适用于 bat 提取 基本概念 红点
原文地址:https://www.cnblogs.com/shijieli/p/10957779.html