标签:mes serve may process sso uri reads serialize head
Sample Final Solutions
Page 1 of 8
CS 8803, Spring 2015.
On a single CPU system, consider the following workload and conditions:
10 I/O-bound tasks and 1 CPU-bound task
I/O-bound tasks issue an I/O operation once every 1 ms of CPU computing
I/O operations always take 10 ms to complete
Context switching overhead is 0.1 ms
I/O device(s) have infinite capacity to handle concurrent I/O requests
All tasks are long-running
Now, answer the following questions (for each question, round to the nearest percent):
Analysis:
Round Robin Scheduling


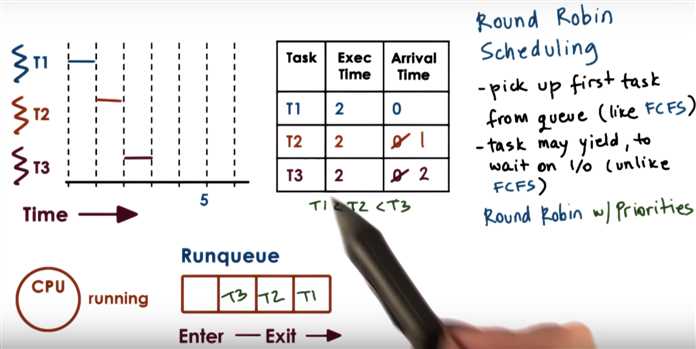
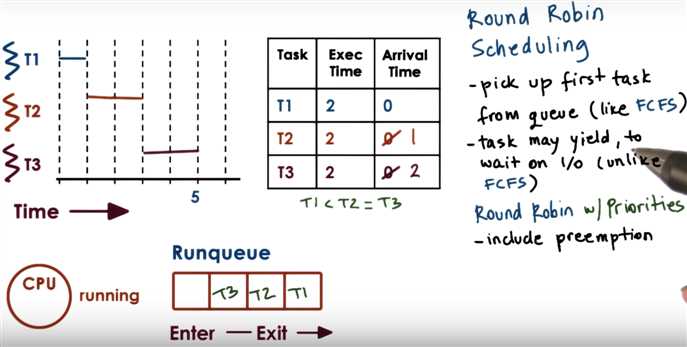
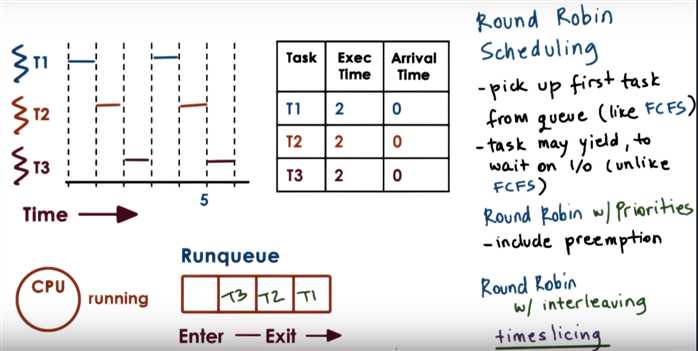
Round-robin rule is: if a task doesn‘t end by itself, end it at each time slice ending (20ms here)
For CPU utility:
There‘re 11 tasks in total, so the CPU running time in a round => 10 I/O-bound tasks cost 10*1ms; 1 CPU-bound task costs 20ms
=> also there‘re 11 context switching => 11*0.1ms wasted in a round => CPU utility = ?
For I/O utility:
Since the the I/O device has infinite ability for concurrency => total I/O device working time in a round = I/O device ending time - starting time
(ps, "all tasks are long-running" => we can assume in a round, the 10 I/O-bound tasks start, then the CPU-bound task starts.)
From another quiz:

![]()
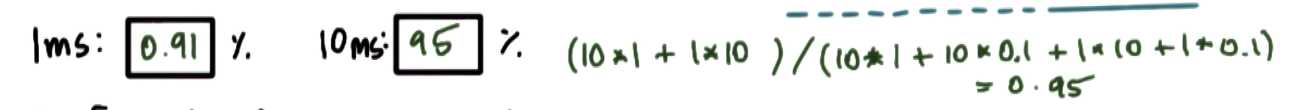
For the case when we have a round robin scheduler with a 10 ms timeslice, as we‘re going through the 10 I/O bound tasks,
every single one of them will run just for 1ms and then we will have to stop because of issuing an I/O request, so we‘ll have them context switch in that case.
From CPU utilization perspective, having a large timeslice that favors the CPU bound task is better.
CPU Utilization Formula:
Helpful Steps to Solve:
CPU utilization
((10 * 1ms) + 1 * 20ms) / ((10 * 1ms) + 1 * 20ms + 11 * 0.1ms ) = 30 / 31.1 = 97%
I/O utilization
the first I/O request is issued at 1 ms time
the last I/O request is issued at (1 ms + 9 * 1ms + 9 * 0.1) = 10.9 ms, and it will take 10 ms to complete, so it will complete at 20.9 ms
total time there are I/O requests being processed is 20.9 - 1 = 19.9 ms
the CPU bound task will complete at time 31.1 ms (which is also the total time for the set of tasks)
19.9 / 31.1 = 64%
For the next four questions, consider a Linux system with the following assumptions:
Provide answers to the following:
Recall:
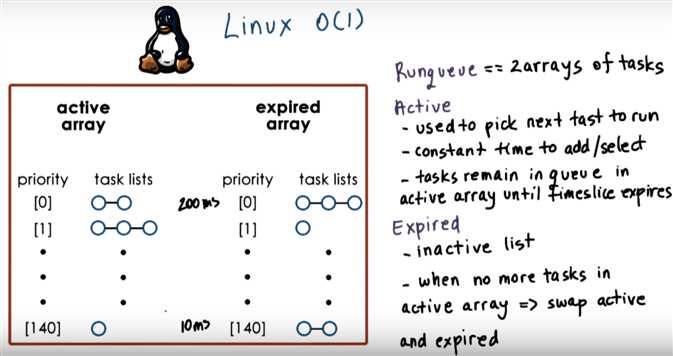
Linux O(1) Scheduler
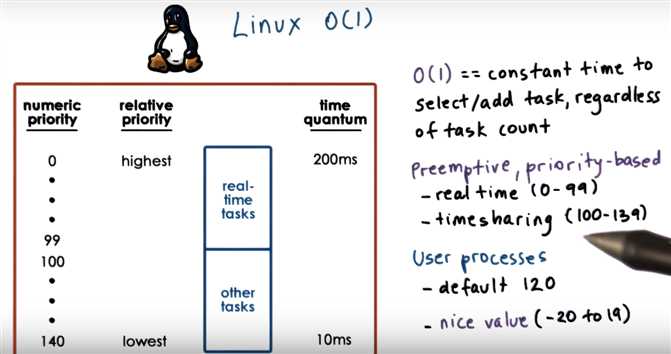
t1 (in O(1) lower priority => greater numerical value; so t1 has higher priority)
t1 (in O(1) lower priority tasks => smaller time quantum; so t1 will have longer time quantum)
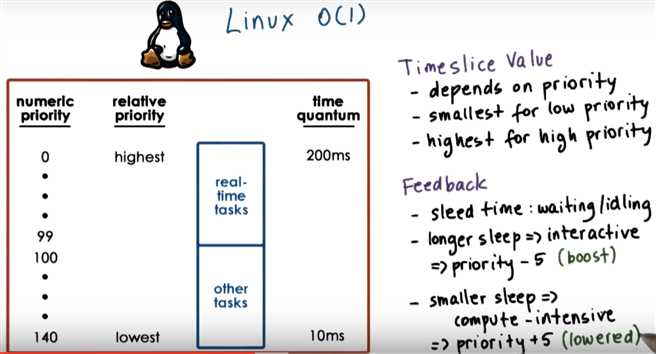
increase (since it used up all of its quantum without blocking, it means that it’s CPU bound, so it’s priority level should be lowered, which means the numerical value of its priority should be increased)
decrease (since it blocked, it’s more I/O intensive, will get a boost in priority, which means that the numerical value will be decreased)
Consider a quad-core machine with a single memory module connected to the CPU‘s via a shared “bus”. On this machine, a CPU instruction takes 1 cycle, and a memory instruction takes 4 cycles.
The machine has two hardware counters:
Answer the following:
Scheduling with Hardware Counters

instructions per cycle
cycles per instruction
4 (best case scenario: if all cores execute CPU-bound instructions, 4 instructions can be completed in a single cycle)
16 (worst case scenario: if all cores issue a memory instruction at the same time, the instructions will contend on the shared bus and the shared memory controller. so one of them can take up to 4 * 4 cycles = 16 cycles to complete)
In a multi-processor system, a thread is trying to acquire a locked mutex.
If owner of mutex is running on a another CPU -> spin; otherwise block
Owner may release mutex quickly; may be faster to wait for owner to complete than to pay overhead for context switching twice.
On uniprocessor, always block, there is no way for owner to be running at the same time, since there is only CPU.
For the following question, consider a multi-processor with write-invalidated cache coherence.
Determine whether the use of a dynamic (exponential backoff) delay has the same, better, or worse performance than a test-and-test-and-set (“spin on read”) lock. Then, explain why.
Make a performance comparison using each of the following metrics:
dynamic (exponential backoff) delay :

test-and-test-and-set (“spin on read”) lock
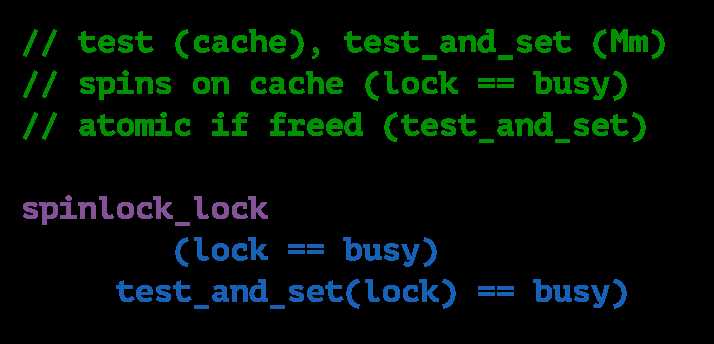
recall:

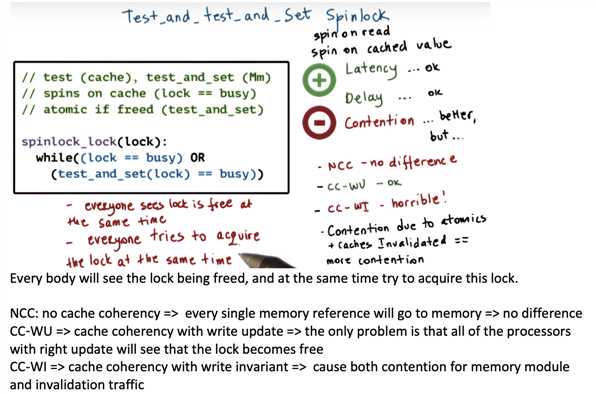

same. if you look at the pseudocode for the two algorithms, if the lock is free then exactly the same operations will be executed in both cases.
worse. because of the delay, the lock may be released while delaying, so the overall time that it will take to acquired a freed lock will be potentially longer
better. in the delayed algorithm, some of the invalidations are not observed because of the wait, so those will not trigger additional memory accesses, therefore overall memory bus/interconnect contention is improved.
Consider a 32-bit (x86) platform running Linux that uses a single-level page table. What are the maximum number of page table entries when the following page sizes are used?
recall:
Page Table Size

page size => size of offset region => size of each frame in physical memory (fixed and small)
page table is a map, transforming a page index of the virtual memory to a frame index of the physical memory.

regular 4kB pages: 32 - 12 bits = 20bits => need 2^20 entries for each virtual page
large 2MB pages: 32 - 21bits = 11 bits => need 2^11 entries for each virtual page
Answer the following questions about PIO:
recall:
Method1:Device Access PIO
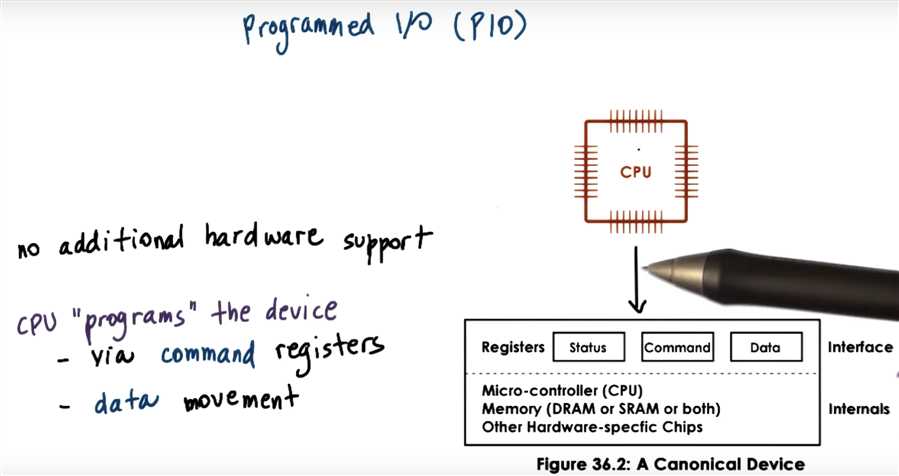
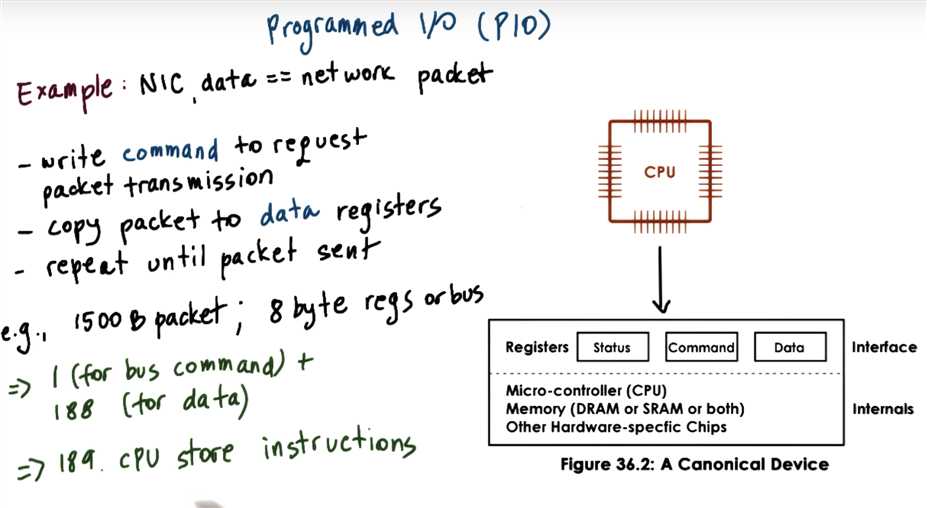
programmed I/O
write ‘command’ to the device to send a packet of appropriate size; copy the header and data in a contiguous memory location; copy data to NIC / device data transfer registers; read status register to confirm that copied data was successfully transmitted; repeat last two steps as many times as needed to transmit the full packet, until end-of-packet is reached.
Assume an inode has the following structure:
![inode-structure] (https://s3.amazonaws.com/content.udacity-data.com/courses/ud923/notes/ud923-final-inodes.png)
Also assume that each block pointer element is 4 bytes.
If a block on the disk is 4 kB, then what is the maximum file size that can be supported by this inode structure?
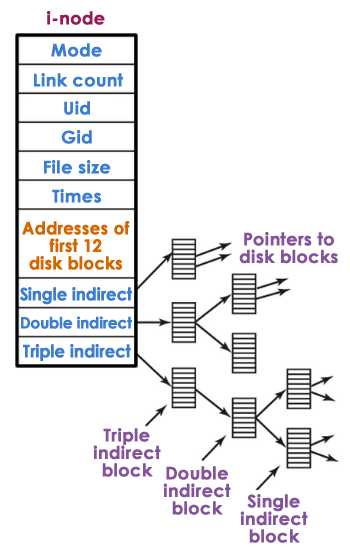
recall:

Maximum File Size:
You do not have to include units in your answers.
Properly rounding up the first answer results in 17GB or 16GiB (where GB is 10^(33) and GiB is 2^(310).
For 4KB = 4kB / 4 = 1k elements: (12 * 4kB) + (1k * 4kB) + (1k^2 * 4kB) + (1k^3 * 4kB) = …
Approx (using last term only) = (2^10)^3 * (2^2)*(2^10) = 2^(30+2+10) = 4TB
A RPC routine get_coordinates() returns the N-dimensional coordinates of a data point, where each coordinate is an integer.
Write the elements of the C data structure that corresponds to the 3D coordinates of a data point.
recall:
Marshalling
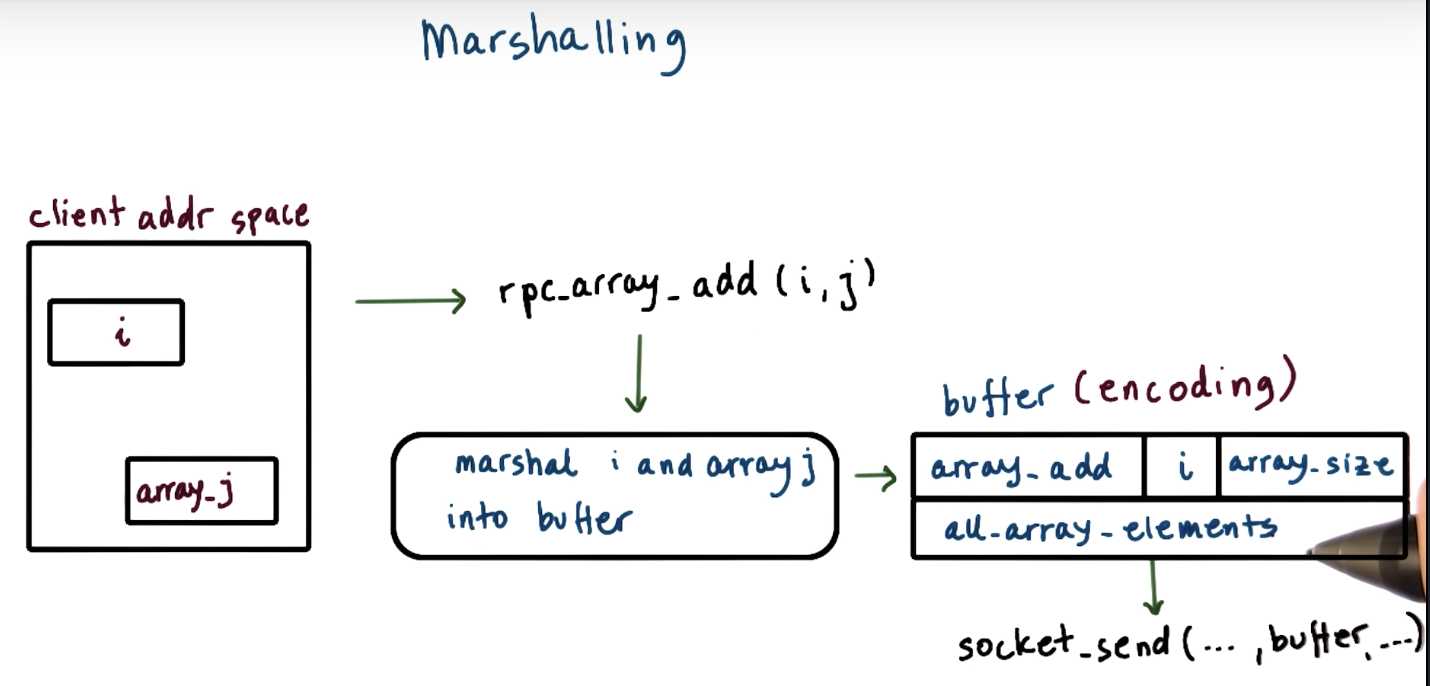
The encoding specifies the data layout when it‘s serialized to the bytee stream, so that anybody that looks at it can actually make sense of it.
The return value will be an array of N integers. Since it’s not specified what is the value of N, the type of the return argument in XDR will be defined as a variable length array of integers:
int data<>
When compiled with rpcgen, this data type will correspond to a data structure in C with two elements, an integer—len—that correspond to the value of N, and a pointer to an integer— val—which will correspond to the pointer to the integer array.
int len (or length)
int * val (or value… )
Consider the following timeline where ‘f’ is distributed shared file and P1 and P2 are processes:

Other Assumptions:
For each of the following DFS semantics, what will be read -- the contents of ‘f‘ -- by P2 when t = 4s?
recall:
File Sharing Semantics on a DFS
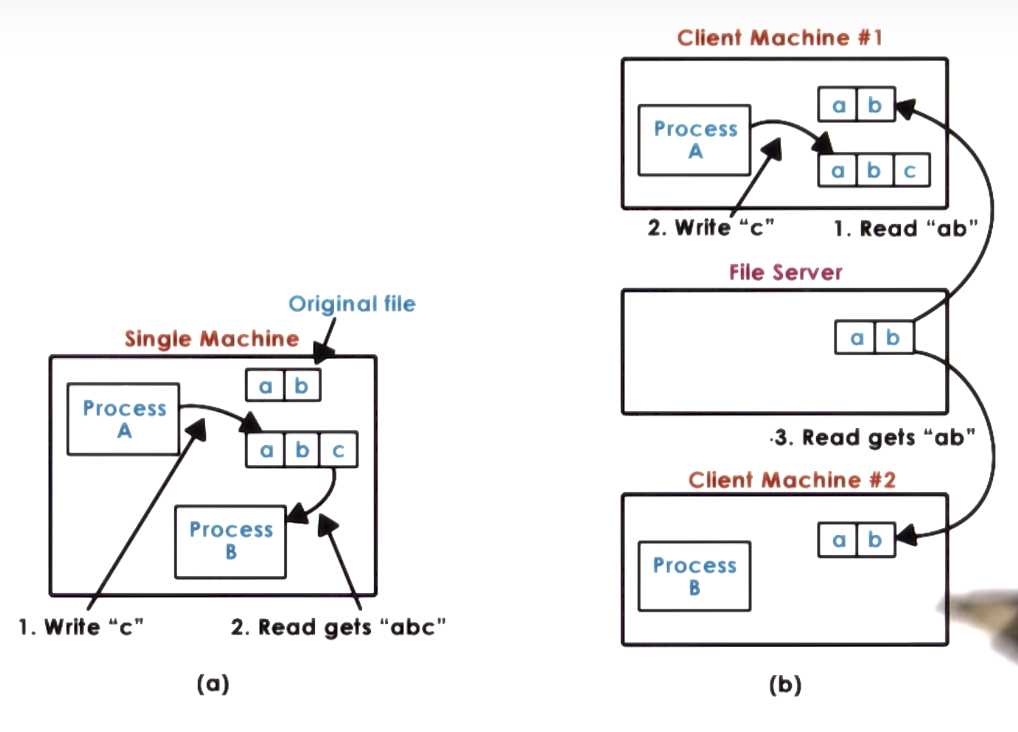

NFS Versions


UNIX: ab (all updates are instantaneously visible)
NSF: a (session semantics, + period updates, but for files that’s 3sec, so the write at t=2s would not propagate)
Consider the following sequence of operations by processors P1, P2, and P3 which occurred in a distributed shared memory system:

Notation
Answer the following questions:
recall:
Causal Consistency
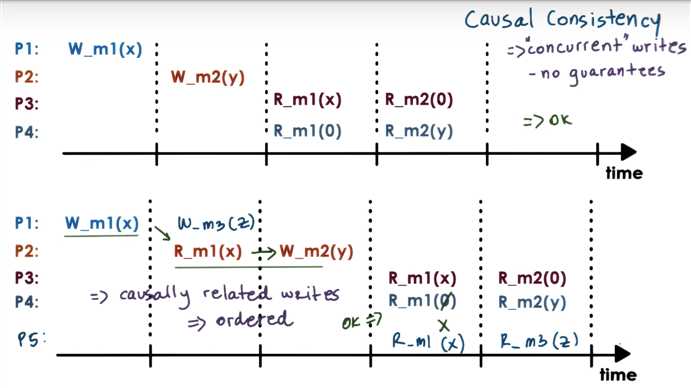
P1 and P2 only.
No. W_m1(3)@P1 and W_m1(2)@ P2 are causally related (via R_m1(2) @P1), so these two writes cannot be seen in reverse order, as currently seen by P3. P3 doesn’t observe causally consistent reads.
You are designing the new image datastore for an application that stores users’ images (like Picasa). The new design must consider the following scale:
Answer the following:
Partitioning. Current data set is ~30 PB, so cannot store it on one machine
10% since requests are evenly distributed.
[Operating System] {ud923} == Sample Final Questions ==
标签:mes serve may process sso uri reads serialize head
原文地址:https://www.cnblogs.com/ecoflex/p/10958316.html