标签:放大 table 绘制 验证码 join inf eset event save
图片验证码基本上是有数字和字母或者数字或者字母组成的字符串,然后通过一些干扰线的绘制而形成图片验证码。
例如:知网的注册就有图片验证码
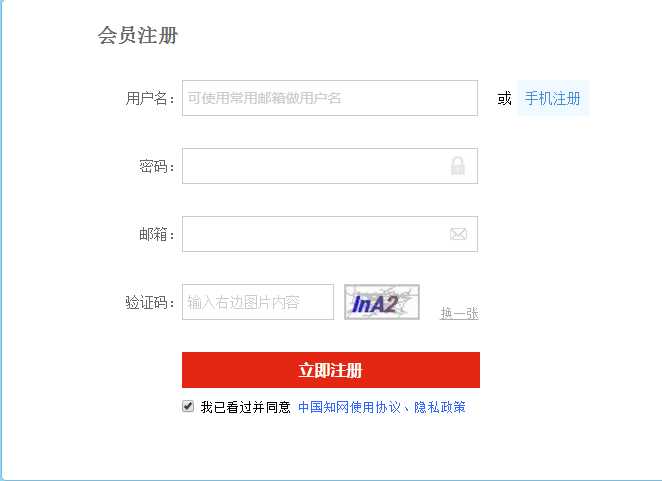
首先我们需要获取验证码图片,通过开发者工具我们可以得到验证码url链接
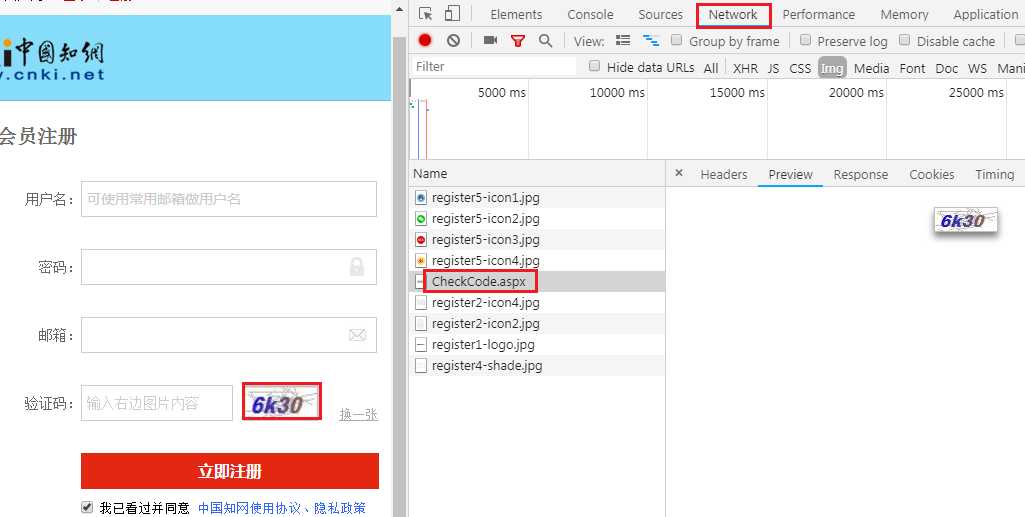
其次就是通过Pillow类库和tesserocr进行识别,代码如下:

1 # -*- coding:utf-8 -*- 2 import tesserocr 3 from PIL import Image 4 import requests 5 6 # 通过url链接获取验证码图片,并写入本地文件夹里 7 def get_image(path,url): 8 """ 9 :param path: 文件夹路径 10 :param url: 验证码url链接 11 """ 12 respon = requests.get(url=url) # 请求验证码url 13 with open(path,"wb") as file: 14 file.write(respon.content) # 将验证码写到本地 15 16 17 # 由于验证码图片太小,需要对验证码图片放大处理,以便识别 18 def reset_image_size(image_path): 19 """ 20 :param image_path: 图片所在的路径 21 :return: 22 """ 23 image = Image.open(fp=image_path) # 打开图片 24 pic_resize = 5 # 设置图片放大或者缩小倍数 25 (x, y) = image.size # 获取图片的大小 26 x_s = int(x * pic_resize) # 放大5倍(可调) 27 y_s = int(y * pic_resize) # 放大5倍(可调) 28 out = image.resize((x_s, y_s), Image.ANTIALIAS) # ANTIALIAS表示高质量图片 29 out.save(image_path) 30 31 32 # 读取验证码图片文本 33 def read_image(image_path): 34 """ 35 :param image_path: 验证码图片路径 36 :return: 37 """ 38 image = Image.open(fp=image_path) # 打开验证码图片 39 image = image.convert(‘L‘) # 将验证码图片转换为灰度图(L表示灰度图) 40 threshold = 127 # 设置灰度图二值化阈值 41 table = [] 42 for i in range(256): # 像素为256 43 if i < threshold: 44 table.append(0) 45 else: 46 table.append(1) 47 image = image.point(table, ‘1‘) # 二值化处理后的副本(1表示二值化) 48 image.show() 49 result = tesserocr.image_to_text(image) # 验证码图片转换为文本 50 return result 51 52 53 # 验证码识别信息脏数据处理 54 def VerifInfo(result): 55 """ 56 :param result: 验证码图片通过初步识别后得到的脏数据 57 :return: 58 """ 59 verif_str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890" 60 verif_list = [] 61 for i in result: 62 if i in verif_str: 63 verif_list.append(i) 64 return "".join(verif_list) 65 66 67 68 if __name__ == ‘__main__‘: 69 img_path = "D:\photo\image" # 文件夹目录 70 img_path = img_path + "\VerificationCode.png" # 验证码图片所在的目录及名称 71 img_url = "http://my.cnki.net/elibregister/CheckCode.aspx" # 验证码url 72 get_image(img_path,img_url) # 获取验证码图片 73 reset_image_size(img_path) # 调整验证码图片大小 74 result = read_image(img_path) # 读取验证码图片内容 75 verif_info = VerifInfo(result) # 验证码内容数据处理 76 verif_len = len(verif_info) # 验证码识别长度 77 if verif_len == 4 and verif_info: 78 print(verif_info) 79 else: 80 pass
最后就是看看识别的效果吧。前者为原始验证码图片,后者是经过二值化处理的图片。

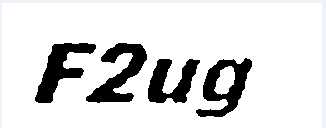
输出的结果为:FZug
显然使用tesserocr识别还是有误差的,以后可以用深度学习的方式训练处一个模型,可以提高识别效率,后期会跟进实现的。
标签:放大 table 绘制 验证码 join inf eset event save
原文地址:https://www.cnblogs.com/zhaco/p/10960339.html
