标签:相等 src 产生 要求 就会 出现 avl details 通过
因为PTA上的题目会涉及,所以在这里提一下
参考:精度评定中的准确率(Precision)和召回率(Recall),怎样量化评价搜索引擎的结果质量
当进行查找的时候,样本会被分成两类,在这里举例:苹果和非苹果
那么进行检索的时候,就会出现四种情况:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
假如分类器只将苹果特征十分明显、是苹果的概率非常高的样本分为苹果,其余的样本分为非苹果,此时该分类器的准确率就会非常的高,但是它因为将所有疑似苹果都错误分为非苹果,召回率变得非常低。
假如分类器将所有可能为苹果的样本全部划分为苹果,其余的样本为非苹果,此时该分类器的召回率会非常之高,但是它因为将所有可能为苹果的样本分为苹果时引入了许多错误,准确率不高。
召回率衡量一个查询搜索到所有相关文档的能力,而准确率(Precision)衡量搜索系统排除不相关文档的能力。
通俗来说,召回率表示所有靠谱的结果中,有多少被你给找回来了;准确率就是算一算你查询得到的结果中有多少是靠谱的
参考:在哈希表中查找成功和不成功时的平均查找长度如何计算?
传说中的ASL(Average Search Length),分为查找成功的ASL(ASLsucc)和和查找失败的ASL(ASLunsucc),下面的例子都以查找概率相等为前提
其实就是在构造散列表的时候,把所有关键字的比较次数加起来求平均值,假设有以下散列表:7,8,30,11,18,9,14 根据H(key) = (3*key) MOD 7放入长度为10的散列表中,用线性探测处理冲突
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 关键字 | 7 | 14 | 9 | 8 | | 11 | 30 | 18 | | |
| 比较次数 | 1 | 2 | 1 | 1 | | 1 | 1 | 3 | | |
ASLsucc=(1+2+1+1+1+1+3)/7=10/7
计算查找不成功的次数就直接找关键字到第一个地址上关键字为空的距离即可,因为不管经过计算得到的下标是什么,通过线性探测,只要遇到第一个空位前都没找到,那就是找不到了。
不同于ASLsucc,ASLunsucc不是针对关键字的比较次数,而是所有关键存放的位置到空着的位置的距离。由于我们是通过MOD 7的来的下标,所以需要比较的下标为0-6即可,所有也是0-6下标到空位的距离相加
要注意的是这里的距离实际上指的是从该位置开始到空位的比较次数,我们从下标0开始看
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 关键字 | 7 | 14 | 9 | 8 | | 11 | 30 | 18 | | |
| 到空位的距离 | 5 | 4 | 3 | 2 | 1 | 4 | 3 | | | |
下标0到第一个空位置(下标4)要比较5次才能确定不存在,因此距离为5,以此类推。到下标6时,比较到下一个空位置(下标8)要经过3次比较,比较完后结束比较。
ASLunsucc=(5+4+3+2+1+4+3)/7=22/7
注意:ASLsucc的分母由关键字的个数决定,而ASLunsucc的分母由初次计算所得结果的个数决定(比如MOD 7,会有0-6七个结果),上面相等是个巧合...
这一章有很多方法,为了避免搞混(因为已经搞混了)所以在这里试着罗列一下
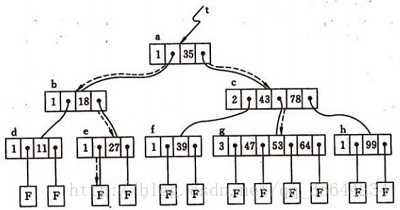
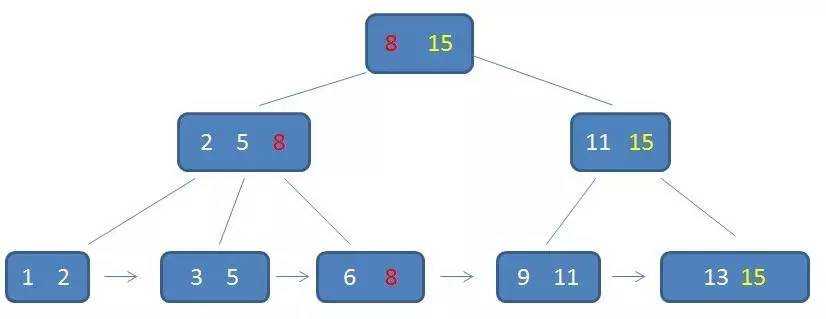
散列表查找法/哈希查找,主要是散列表的构建和冲突的解决
分为开放地址法和链地址法
伪随机探测法:利用随机数来进行冲突时位置的选择。创建时需要记录随机数生成的顺序,用以之后查找
类似邻接表,将所有冲突的地址以链式存储的形式放在相应位置的后面。
上次学习小结匆匆忙忙赶出来的,感觉效果不理想,所以还是要认真总结。
这次因为有很多概念,所以参考了很多其他博客,感觉效果不错。很多人能把复杂的概念讲的很具体,会举例子,配图,很容易理解。
虽然上次的总结比较草率,但之后还是有去补上代码啦,多敲代码还是有好处的。不过还是希望能匀出更多的时间看一些文字,比如STL,比如高质量编程指南。
标签:相等 src 产生 要求 就会 出现 avl details 通过
原文地址:https://www.cnblogs.com/luoyang0515/p/10963020.html