标签:height 找不到 hellip 链式存储 总结 one 并且 组成 随机
第七章小结
先列出一些基本的概念:
①关键字:数据元素(记录)中某个数据项的值,用它可以表示一个数据元素。
②动态查找表/静态查找表:若在查找的过程中进行修改操作(插入或删除),则相应的表为动态查找表,否则为静态查找表。
③平均查找长度:为确定记录在查找表中的位置,需和给定值进行比较的关键字个数的期望值称为查找算法在查找成功时的平均查找长度。公式如下:ASL=∑PiCi (i=1,2,3,…,n),可以简单以数学上的期望来这么理解。其中:Pi 为查找表中第i个数据元素的概率,Ci为找到第i个数据元素时已经比较过的次数。
下图为本章的思维导图
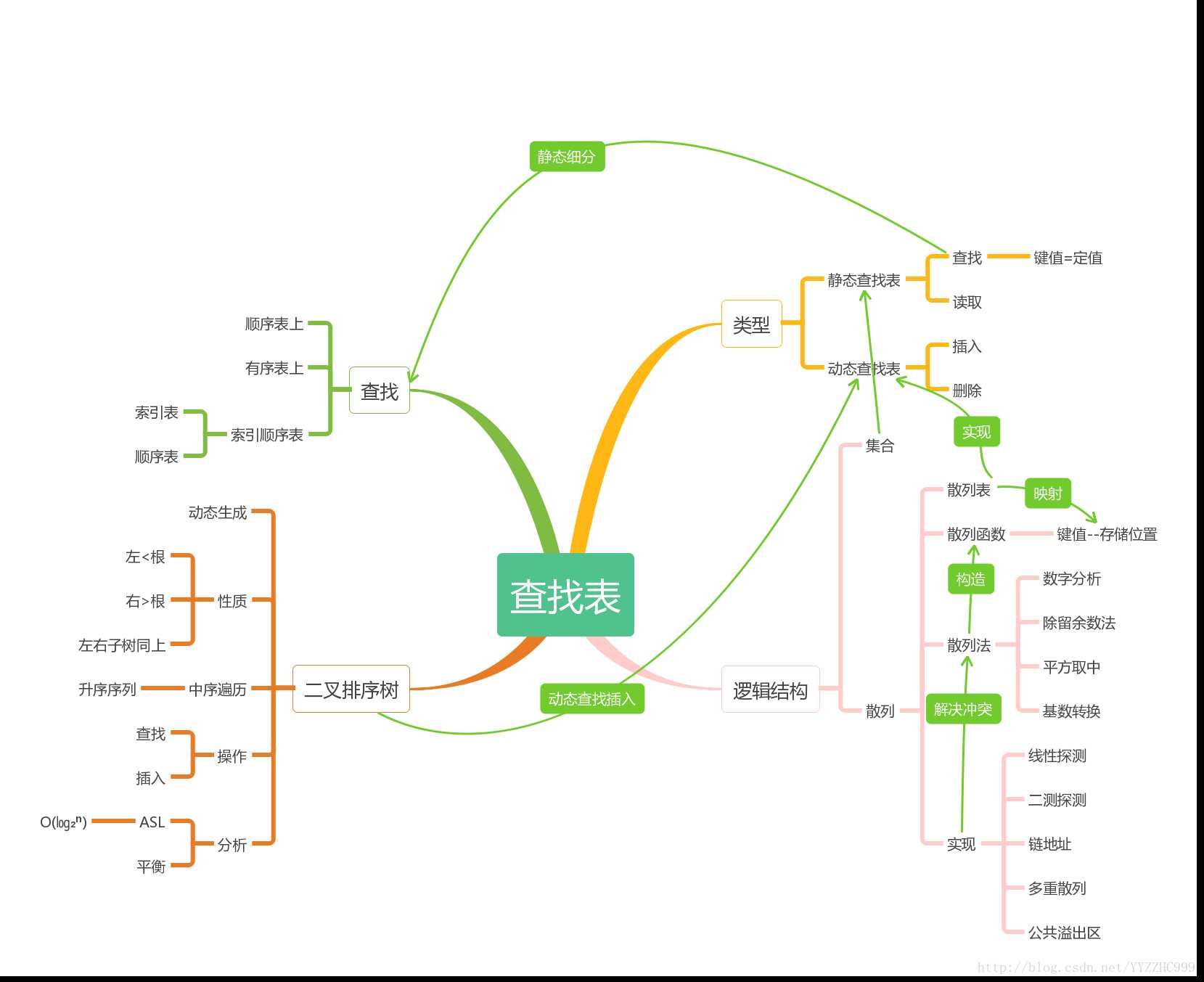
1. 顺序查找
从表的一端开始,顺序扫描表,依次将扫描到的结点关键字和给定值(假定为a)相比较,若当前结点关键字与a相等,则查找成功;若扫描结束后,仍未找到关键字等于a的结点,则查找失败。
顺序查找也是最普通的一种方法,我们刚开始学习的时候几乎都会用这种查找方法,也就是从头开始,一个一个地进行比较,所以这也是效率最低的一个方法。
适用于线性表的顺序存储结构和链式存储结构。
查找成功时的平均查找长度为: ASL = 1/n(1+2+3+…+n) = (n+1)/2 ;
2. 折半查找
搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如 果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
折半计算mid的公式
mid = (low+high)/2;
if(a[mid]==value)
return mid;
if(a[mid]>value)
high = mid-1;
if(a[mid]<value)
low = mid+1;
3. 分块查找
二分查找表使分块有序的线性表和索引表(抽取各块中的最大关键字及其起始位置构成索引表)组成,由于表是分块有序的,所以索引表是一个递增有序表,因此采用顺序或二分查找索引表,以 确定待查结点在哪 一 块,由于块内无序,只能用顺序查找。
4. 树表查找
二叉排序树(Binary Sort Tree),又称为二叉查找树。它或者是一棵空树,或者是具有下列性质的二叉树。
若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若它的右子树不空 ,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉排序树。
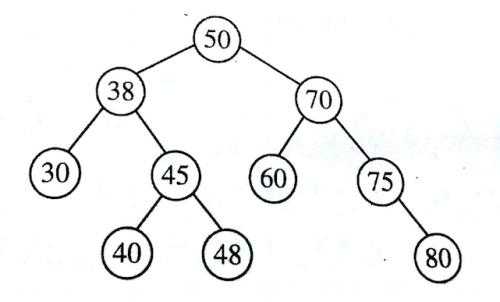
平衡二叉树(AVL树)
平衡二叉树,是一种二叉排序树,其中每一个节点的左子树和右子树的高度差至多等于1。
从平衡二叉的英文名字(AVL树),你也可以体会到,它是一种高度平衡的二叉排序树。
高度平衡意思是说,要么它是一棵空树,要么它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。
B-树
B树可以看作是对查找树的一种扩展,即他允许每个节点有M-1个子节点。
根节点至少有两个子节点
每个节点有M-1个key,并且以升序排列
位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
其它节点至少有M/2个子节点
B+树
B+树是对B树的一种变形树,它与B树的差异在于:
5. 散列表
(2)散列函数的构造方法:
数字分析法;平方取中法;折叠法;除留余数法 (假设散列表表长为m,选择一个不大于m的数p,用p去除关键字,除后所得余数为散列地址)
(3)处理冲突的办法
开放地址法:线性探测法;二次探测法;伪随机探测法
链地址法
上一次的目标基本达成,还顺带学习了一下map的用法,
下一阶段的目标:备考准备,好好复习。
标签:height 找不到 hellip 链式存储 总结 one 并且 组成 随机
原文地址:https://www.cnblogs.com/hxyawsl/p/10963574.html