标签:转换 azkaban list 用户 sqoop 接收 开源 生产者 ima
离线部分:
Hadoop->离线计算(hdfs / mapreduce) yarn
zookeeper->分布式协调(动物管理员)
hive->数据仓库(离线计算 / sql)easy coding
flume->数据采集
sqoop->数据迁移mysql->hdfs/hive hdfs/hive->mysql
Azkaban->任务调度工具
hbase->数据库(nosql)列式存储 读写速度
实时:
kafka
storm
官网:
http://kafka.apache.org/
ApacheKafka®是一个分布式流媒体平台
流媒体平台有三个关键功能:
发布和订阅记录流,类似于消息队列或企业消息传递系统。
以容错的持久方式存储记录流。
记录发生时处理流。
Kafka通常用于两大类应用:
构建可在系统或应用程序之间可靠获取数据的实时流数据管道
构建转换或响应数据流的实时流应用程序
在流计算中,kafka主要功能是用来缓存数据,storm可以通过消费kafka中的数据进行流计算。
是一套开源的消息系统,由scala写成。支持javaAPI的。
kafka最初由LinkedIn公司开发,2011年开源。
2012年从Apache毕业。
是一个分布式消息队列,kafka读消息保存采用Topic进行归类。
发送消息:Producer(生产者)
接收消息:Consumer(消费者)
为什么要用消息队列
1)解耦
为了避免出现问题
2)拓展性
可增加处理过程
3)灵活
面对访问量剧增,不会因为超负荷请求而完全瘫痪。
4)可恢复
一部分组件失效,不会影响整个系统。可以进行恢复。
5)缓冲
控制数据流经过系统的速度。
6)顺序保证
对消息进行有序处理。
7)异步通信
akka,消息队列提供了异步处理的机制。允许用户把消息放到队列 , 不立刻处理。
kafka依赖zookeeper,用zk保存元数据信息。
搭建kafka集群要先搭建zookeeper集群。
zk在kafka中的作用?
保存kafka集群节点状态信息和消费者当前消费信息。
1)官网下载安装包
2)上传安装包
3)解压安装包
4)重命名
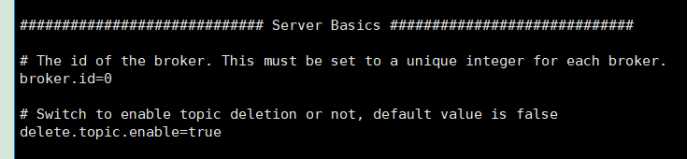
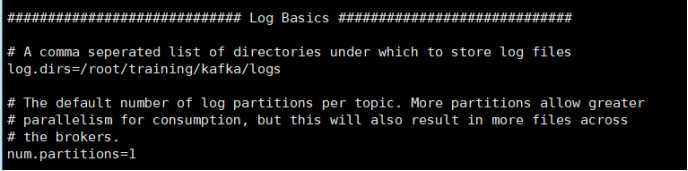
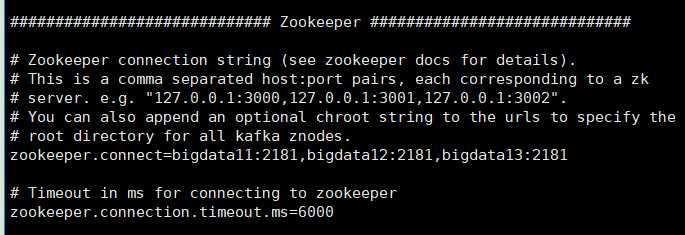
5)修改配置文件 (config/server.properties)
broker.id=0 #每台机器的id不同即可
delete.topic.enable=true #是否允许删除主题
log.dirs=/root/training/kafka/logs #运行日志保存位置(需提前在kafka目录下创建logs目录)
zookeeper.connect=bigdata11:2181,bigdata12:2181,bigdata13:2181
6)启动集群
bin/kafka-server-start.sh config/server.properties &
7)关闭
bin/kafka-server-stop.sh
1)查看当前集群中已存在的主题topic
bin/kafka-topics.sh --zookeeper bigdata11:2181 --list
2)创建topic
bin/kafka-topics.sh --zookeeper bigdata11:2181 --create --replication-facto
r 3 --partitions 1 --topic guanxuan
--zookeeper 连接zk集群
--create 创建
--replication-factor 副本
--partitions 分区
--topic 主题名
3)删除主题
bin/kafka-topics.sh --zookeeper bigdata11:2181 --delete --topic morning
4)发送消息
生产者启动:
bin/kafka-console-producer.sh --broker-list bigdata11:9092 --topic morning
消费者启动:
bin/kafka-console-consumer.sh --bootstrap-server bigdata11:9092 --topi
c morning--from-beginning
5)查看主题详细信息
bin/kafka-topics.sh --zookeeper bigdata11:2181 --describe --topic morning
标签:转换 azkaban list 用户 sqoop 接收 开源 生产者 ima
原文地址:https://www.cnblogs.com/hidamowang/p/10971485.html