一、简单的装饰器
1.为什么要使用装饰器呢?
装饰器的功能:在不修改原函数及其调用方式的情况下对原函数功能进行扩展
装饰器的本质:就是一个闭包函数
那么我们先来看一个简单的装饰器:实现计算每个函数的执行时间的功能


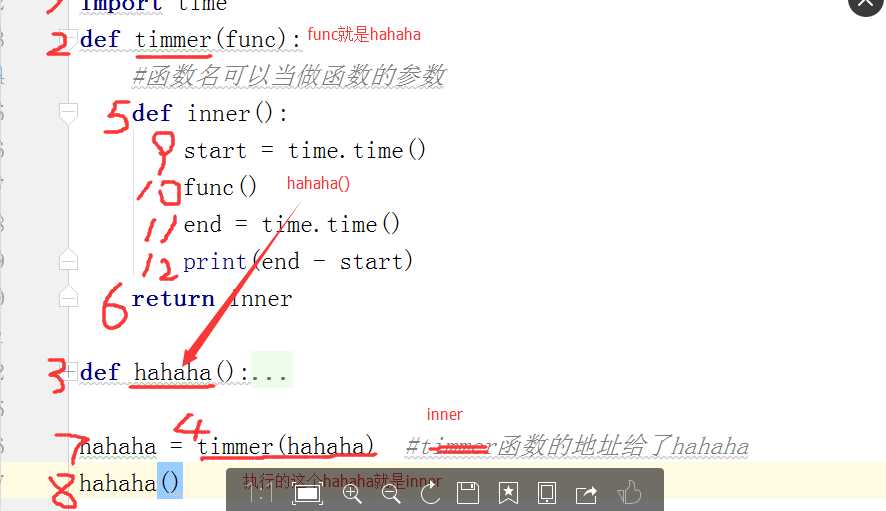
1 import time 2 def wrapper(func): 3 def inner(): 4 start=time.time() 5 func() 6 end=time.time() 7 print(end-start) 8 return inner 9 10 def hahaha(): 11 time.sleep(1) 12 print(‘aaaaa‘) 13 hahaha=wrapper(hahaha) 14 hahaha()
上面的功能有点不简介,不完美,下面就引进了语法糖。
1 import time 2 def wrapper(func): 3 def inner(): 4 start=time.time() 5 func() 6 end=time.time() 7 print(end-start) 8 return inner 9 @wrapper 10 def kkk():#相当于kkk=wrapper(kkk) 11 print(‘aaaaa‘) 12 kkk()
以上的装饰器都是不带参数的函数,现在装饰一个带参数的该怎么办呢?
原函数带一个参数的装饰器
1 import time 2 def timer(func): 3 def inner(*args,**kwargs): 4 start = time.time() 5 re = func(*args,**kwargs) 6 end=time.time() 7 print(end- start) 8 return re 9 return inner 10 11 @timer #==> func1 = timer(func1) 12 def func1(a,b): 13 print(‘in func1‘) 14 print(a,b) 15 16 @timer #==> func1 = timer(func1) 17 def func2(a): 18 print(‘in func2 and get a:%s‘%(a)) 19 return ‘fun2 over‘ 20 21 func1(1,2) 22 print(func2(‘aaaaaa‘))
1 import time 2 def timer(func): 3 def inner(*args,**kwargs): 4 start = time.time() 5 re = func(*args,**kwargs) 6 end=time.time() 7 print(end - start) 8 return re 9 return inner 10 11 @timer #==> func1 = timer(func1) 12 def jjj(a): 13 print(‘in jjj and get a:%s‘%(a)) 14 return ‘fun2 over‘ 15 16 jjj(‘aaaaaa‘) 17 print(jjj(‘aaaaaa‘))
二、开放封闭原则
1.对扩展是开放的
2.对修改是封闭的
三、装饰器的固定结构
1 import time 2 def wrapper(func): # 装饰器 3 def inner(*args, **kwargs): 4 ‘‘‘函数执行之前的内容扩展‘‘‘ 5 ret = func(*args, **kwargs) 6 ‘‘‘函数执行之前的内容扩展‘‘‘ 7 return ret 8 return inner 9 10 @wrapper # =====>aaa=timmer(aaa) 11 def aaa(): 12 time.sleep(1) 13 print(‘fdfgdg‘) 14 aaa()
四、带参数的装饰器
带参数的装饰器:就是给装饰器传参
用处:就是当加了很多装饰器的时候,现在忽然又不想加装饰器了,想把装饰器给去掉了,但是那么多的代码,一个一个的去闲的麻烦,那么,我们可以利用带参数的装饰器去装饰它,这就他就像一个开关一样,要的时候就调用了,不用的时候就去掉了。给装饰器里面传个参数,那么那个语法糖也要带个括号。在语法糖的括号内传参。在这里,我们可以用三层嵌套,弄一个标识为去标识。如下面的代码示例
1 # 带参数的装饰器:(相当于开关)为了给装饰器传参 2 # F=True#为True时就把装饰器给加上了 3 F=False#为False时就把装饰器给去掉了 4 def outer(flag): 5 def wrapper(func): 6 def inner(*args,**kwargs): 7 if flag: 8 print(‘before‘) 9 ret=func(*args,**kwargs) 10 print(‘after‘) 11 else: 12 ret = func(*args, **kwargs) 13 return ret 14 return inner 15 return wrapper 16 17 @outer(F)#@wrapper 18 def hahaha(): 19 print(‘hahaha‘) 20 21 @outer(F) 22 def shuangwaiwai(): 23 print(‘shuangwaiwai‘) 24 25 hahaha() 26 shuangwaiwai()
五、多个装饰器装饰一个函数
1 def qqqxing(fun): 2 def inner(*args,**kwargs): 3 print(‘in qqxing: before‘) 4 ret = fun(*args,**kwargs) 5 print(‘in qqxing: after‘) 6 return ret 7 return inner 8 9 def pipixia(fun): 10 def inner(*args,**kwargs): 11 print(‘in qqxing: before‘) 12 ret = fun(*args,**kwargs) 13 print(‘in qqxing: after‘) 14 return ret 15 return inner 16 @qqqxing 17 @pipixia 18 def dapangxie(): 19 print(‘饿了吗‘) 20 dapangxie() 21 22 ‘‘‘ 23 @qqqxing和@pipixia的执行顺序:先执行qqqxing里面的 print(‘in qqxing: before‘),然后跳到了pipixia里面的 24 print(‘in qqxing: before‘) 25 ret = fun(*args,**kwargs) 26 print(‘in qqxing: after‘),完了又回到了qqqxing里面的 print(‘in qqxing: after‘)。所以就如下面的运行结果截图一样 27 ‘‘‘

上例代码的运行结果截图
六、统计多少个函数被装饰了的小应用
1 统计多少个函数被我装饰了 2 l=[] 3 def wrapper(fun): 4 l.append(fun)#统计当前程序中有多少个函数被装饰了 5 def inner(*args,**kwargs): 6 # l.append(fun)#统计本次程序执行有多少个带装饰器的函数被调用了 7 ret = fun(*args,**kwargs) 8 return ret 9 return inner 10 11 @wrapper 12 def f1(): 13 print(‘in f1‘) 14 15 @wrapper 16 def f2(): 17 print(‘in f2‘) 18 19 @wrapper 20 def f3(): 21 print(‘in f3‘) 22 print(l)
一、可迭代协议:可以被迭代要满足要求的就叫做可迭代协议。内部实现了__iter__方法
iterable:可迭代的------对应的标志
什么叫迭代?:一个一个取值,就像for循环一样取值
字符串,列表,元组,集合,字典都是可迭代的
二、迭代器协议:内部实现了__iter__,__next__方法
迭代器大部分都是在python的内部去使用的,我们直接拿来用就行了
迭代器的优点:如果用了迭代器,节约内存,方便操作
dir([1,2].__iter__())是列表迭代器中实现的所有的方法,而dir([1,2])是列表中实现的所有方法,都是以列表的方式返回给我们,为了方便看清楚,我们把他们转换成集合,然后取差集,然而,我们看到列表迭代器中多出了三个方法,那么这三个方法都分别是干什么的呢?
1 print(dir([1,2].__iter__()))#查看列表迭代器的所有方法 2 print(dir([1,2]))#查看列表的所有方法 3 print(set(dir([1,2].__iter__()))-set(dir([1,2])))

1 iter_l=[1,2,3,4,5,6].__iter__() 2 3 print(iter_l.__length_hint__())#获取迭代器中元素的长度 4 # print(iter_l.__setstate__(4))#根据索引指定从哪里开始迭代 5 6 print(iter_l.__next__()) 7 print(iter_l.__next__()) 8 print(iter_l.__next__())#一个一个的取值 9 print(next(iter_l)) 10 #next(iter_l)这个方法和iter_l.__next__()方法一样,推荐用next(iter_l)这个
1 l=[1,2,3,4,5] 2 a=l.__iter__() 3 4 # print(next(a)) 5 # print(next(a)) 6 # print(next(a)) 7 # print(next(a)) 8 # print(next(a)) 9 # print(next(a)) #上面的列表长度只有5个,而你多打印了,就会报错。处理的情况如下,就不会报错了 10 11 while True: 12 try: 13 item=a.__next__() 14 print(item) 15 except StopIteration: # 异常处理 16 break
三、可迭代和迭代器的相同点:都可以用for循环
四、可迭代和迭代器的不同点:就是迭代器内部多实现了一个__next__方法
五、判断迭代器和可迭代的方法:
第一种:判断内部是不是实现了__next__方法
1 ‘__iter__‘ in dir(str)#如果__iter__在这个方法里面,就是可迭代的。
第二种:
Iterable 判断是不是可迭代对象
Iterator 判断是不是迭代器
用法:
1 from collections import Iterable 2 from collections import Iterator 3 4 #比如给一个字符串 5 s=‘abc‘ 6 print(isinstance(s,Iterable))#isinstance判断类型的 7 print(isinstance(s,Iterator))
判断range函数和map函数
1 map1=map(abs,[1,-2,3,-4]) 2 print(isinstance(map1,Iterable)) 3 print(isinstance(map1,Iterator))#map方法自带迭代器 4 5 s=range(100)#是一个可迭代的,但是不是迭代器 6 print(isinstance(s,Iterable)) 7 print(isinstance(s,Iterator))
五、生成器函数:常规定义函数,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果。生成器的好处,就是一下子不会在内存中生成太多的数据
python中提供的生成器:1.生成器函数 2.生成器表达式
生成器的本质:就是一个迭代器
1 def func(): #这是一个简单的函数 2 a=1 3 return a 4 print(func()) 5 6 7 def func(): 8 print(‘aaaaaaaaaaa‘) 9 a = 1 10 yield a # 返回第一个值 11 print(‘bbbbbb‘) 12 yield 12 # 返回第二个值 13 14 15 ret = func() # 得拿到一个生成器 16 # print(ret)#返回的是一个地址 17 print(next(ret))#取第一个值 18 print(next(ret))# 取第二个值 19 print(next(ret))# 取第三个值,会报错,因为没有yield第三个值
假如我想让工厂给学生做校服,生产2000000件衣服,我和工厂一说,工厂应该是先答应下来,然后再去生产,我可以一件一件的要,也可以根据学生一批一批的找工厂拿。
而不能是一说要生产2000000件衣服,工厂就先去做生产2000000件衣服,等回来做好了,学生都毕业了。。。
1 def make_cloth(): 2 for i in range(1,20000): 3 yield ‘第%s件衣服‘%(i) 4 ret = make_cloth() 5 print(next(ret)) 6 print(next(ret)) 7 print(next(ret)) 8 for i in range(100): 9 print(next(ret))
1 必须先用next再用send 2 def average(): 3 total=0 #总数 4 day=0 #天数 5 average=0 #平均数 6 while True: 7 day_num = yield average #average=0 8 total += day_num 9 day += 1 10 average = total/day 11 avg=average() #直接返回生成器 12 next(avg)#激活生成器,avg.send(),什么都不传的时候send和next的效果一样 13 print(avg.send(10)) 14 print(avg.send(20))#send 1.传值 2.next 15 print(avg.send(30))
1 让装饰器去激活 2 def wrapper(func): 3 def inner(*args,**kwargs): 4 ret = func(*args,**kwargs) 5 next(ret) 6 return ret 7 return inner 8 9 @wrapper 10 def average(): 11 total=0 #总数 12 day=0 #天数 13 average=0 #平均数 14 while True: 15 day_num = yield average #average=0 16 total += day_num 17 day += 1 18 average = total/day 19 20 21 ret=average() #直接返回生成器 22 print(ret.send(10)) 23 print(ret.send(20))#send 1.传一个值过去 2.让当前yield继续执行 24 print(ret.send(30))
1 import time 2 3 4 def tail(filename): 5 f = open(filename) 6 f.seek(0, 2) #从文件末尾算起 7 while True: 8 line = f.readline() # 读取文件中新的文本行 9 if not line: 10 time.sleep(0.1) 11 continue 12 yield line 13 14 tail_g = tail(‘tmp‘) 15 for line in tail_g: 16 print(line)
六、yield from
1 def func(): 2 # for i in ‘AB‘: 3 # yield i 4 yield from ‘AB‘ yield from ‘AB‘就相当于上面的for循环,吧循环简化了 5 yield from [1,2,3] 6 7 g=func() 8 print(list(g)) 9 # print(next(g)) 10 # print(next(g))
七、列表推导式:
1 举例一 2 y=2 3 #for i in range(100): 4 # print(i*y) 5 6 7 #列表推导式是for循环的简写 8 l=[i*y for i in range(100)] 9 10 举例二 11 l=[{‘name‘:‘v1‘,‘age‘:‘22‘},{‘name‘:‘v2‘}] 12 # for dic in l: 13 # print(dic[‘name‘]) 14 name_list=[dic[‘name‘] for dic in l] 15 print(name_list)
# ======一层循环======
l = [i*i for i in range(1,10)]
print(l)
# 上面的列表推倒式就相当于下面的
l = []
for i in range(1,10):
l.append(i*i)
print(l)
l = []
# ======多层循环========
# 1.列表推倒式
l = [i*j for i in range(1,10) for j in range(1,10)]
print(l)
# 2.循环
l = []
for i in range(1,10):
for j in range(1,10):
s = i*j
l.append(s)
print(l)
八、生成器表达式:类似于列表推倒式,就是把列表推导式的【】改为了()
1 l=[{‘name‘:‘v1‘,‘age‘:‘22‘},{‘name‘:‘v2‘}]
2
3 name_list=(dic[‘name‘] for dic in l)#吧列表生成器的[]改成()
4 print(name_list)#取出的是一个生成器,而不是要取得值,所以得加上next
5 print(next(name_list))
6 print(next(name_list))
7 # print(next(name_list))