标签:esc cal 爬取 命令 基于 error int 依次 运行
1.
回顾 - 全站数据爬取(分页) - 手动请求的发送Request(url,callback) - post请求和cookie处理 - start_requests(self) - FromRequest(url,callback,formdata) - cookie操作是自动处理 - 请求传参 - 使用场景: - 实现:scrapy.Request(url,callback,meta={‘‘:‘‘}) callback:response.meta[‘‘] - 中间件 - 下载中间件:批量拦截所有的请求和响应 - 拦截请求:UA伪装(process_request),代理ip(process_exception:return request) - 拦截响应:process_response
2.
- CrawlSpider 作用:就是用于进行全站数据的爬取 - CrawlSpider就是Spider的一个子类 - 如何新建一个基于CrawlSpider的爬虫文件 - scrapy genspider -t crawl xxx www.xxx.com - LinkExtractor连接提取器:根据指定规则(正则)进行连接的提取 - Rule规则解析器:将链接提取器提取到的链接进行请求发送,然后对获取的页面数据进行 指定规则(callback)的解析 - 一个链接提取器对应唯一一个规则解析器
3.高效的全栈数据爬取
新建一个抽屉的项目,我们对其进行全栈数据的爬取

下图是页码对应的url

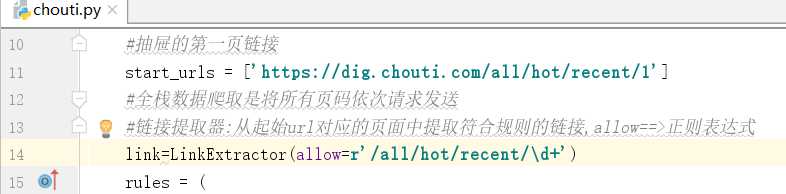
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class ChoutiSpider(CrawlSpider): name = ‘chouti‘ # allowed_domains = [‘www.xxx.com‘] #抽屉的第一页链接 start_urls = [‘https://dig.chouti.com/all/hot/recent/1‘] #全栈数据爬取是将所有页码依次请求发送 #链接提取器:从起始url对应的页面中提取符合规则的链接,allow==>正则表达式 link=LinkExtractor(allow=r‘/all/hot/recent/\d+‘) rules = ( #规则解析器,可以有多个规则:将链接提取器提取到的链接对应的页面源码进行制定规则的解析 Rule(link, callback=‘parse_item‘, follow=False), ) def parse_item(self, response): # item = {} #item[‘domain_id‘] = response.xpath(‘//input[@id="sid"]/@value‘).get() #item[‘name‘] = response.xpath(‘//div[@id="name"]‘).get() #item[‘description‘] = response.xpath(‘//div[@id="description"]‘).get() # return item print(response)
修改下面的内容:
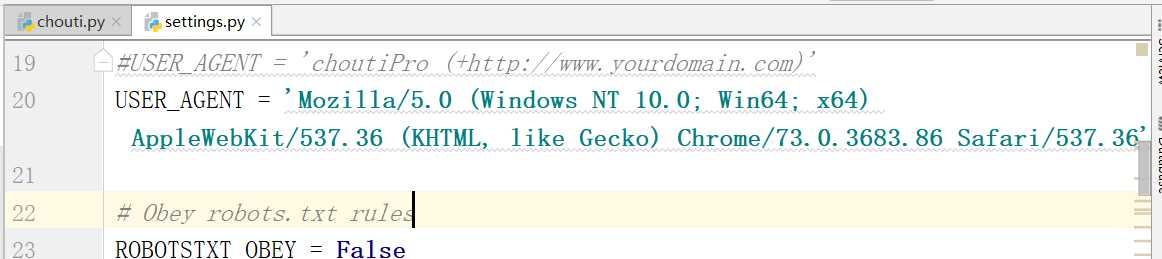
LOG_LEVEL=‘ERROR‘
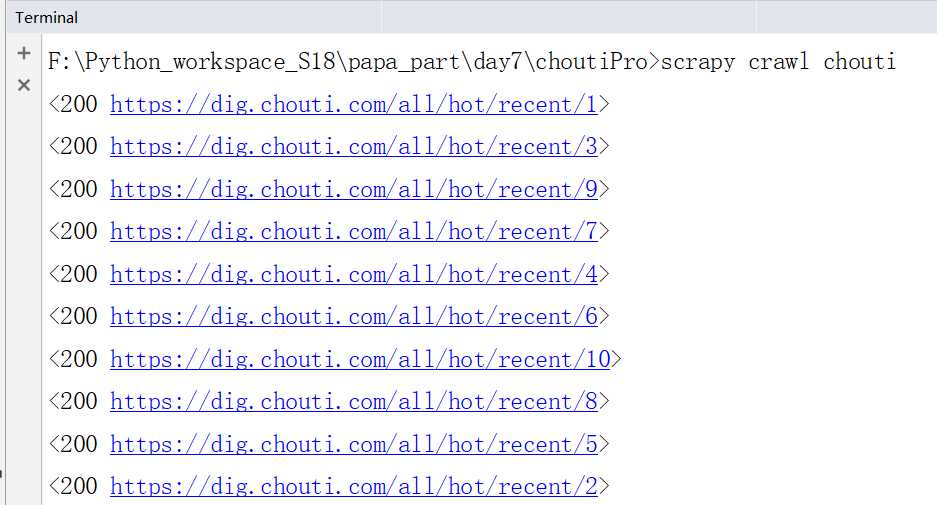
下面我们提取指定的规则执行下面的命令:
运行之后,我们只是爬取到了10条数据
我们需要将最后一个界面作为起始,也就是follow=True就可以了
再次运行下面的命令:
成功取到120页的数据.
标签:esc cal 爬取 命令 基于 error int 依次 运行
原文地址:https://www.cnblogs.com/studybrother/p/10976957.html