标签:出现 告诉 遇到 mozilla ram 应用 urllib2 参数 三方
基于想自己下载网络小说的念头,认识到了python. 使用过后真是觉得是一门适合网络的语言,加上数不清的第三方库可以使用。适合快速开发。当然python也在数据分析,自然语义方面也有很多优势。这里主要介绍在网络方面的应用。
说到网络,和我们最接近的就是网页了。网页主要技术是http,当然还有javascript,XML,JSON,TCP连接等一大堆前端,后端的东东,关于http的知识这里不做多的描述,推荐看下http权威指南。

网页都是用html语言写的,关于HTML语言W3CSCHOOL上面有大量的介绍。而网络爬虫就是主要针对HTML语言而言。不如下面的百度的界面,用google浏览器点击F12,IE右击鼠标,然后选择查看网页源代码。左边是我们上网看到的百度页面,右边就是html源代码。被script包含的部分就是javascript。 这个页面主要是动态加载的页面,显示的内容主要是用javascript来驱动。看上去还不太直观。下面我们看一个更简单的
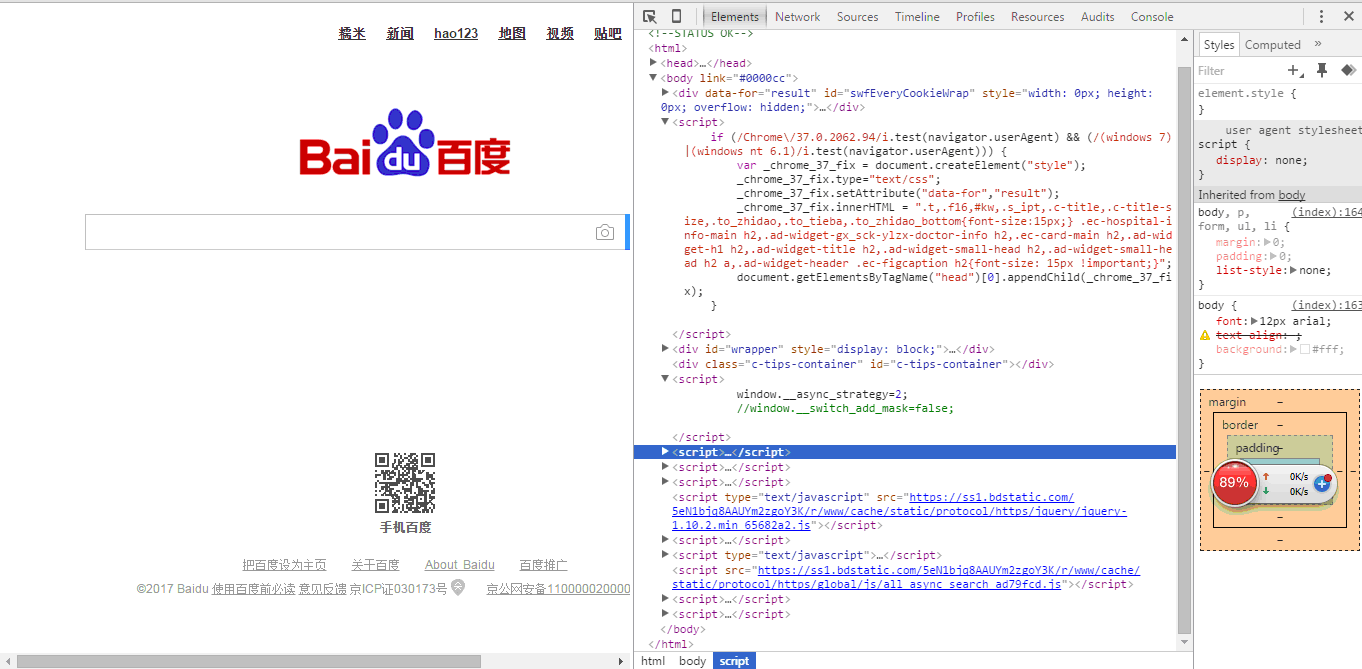
在百度一下上右击鼠标,然后选择审查元素,对于的HMTL代码就显示出来
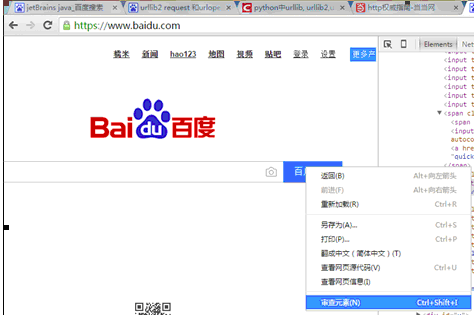
具体的代码:可以看到百度一下的这几个字在input元素里面,代表的是这是一个输入框
也许有人问,这和网络爬虫以及下载小说有啥关系,别急,前面的只是个网页的入门介绍。下面我们来看个小说的界面:下面是迅读网的小说,左边是小说正文,右边是相关的网页代码。大家看到没有,所有的小说正文都包含在标签是<div>并且id=”content_1”的的元素里面
如果我们能有工具能自动将HTML代码对应元素内容自动下载下来。不就可以自动下载小说了。这就是网络爬虫的功能,说白了网络爬虫就是解析HMTL代码并保存下来然后进行后处理的。简单来说就三个步骤:1 解析网页得到数据,2 保存数据 3 数据的后处理。下面我们就首先从第一步解析网页得到数据开始。
访问网页首先要请求URL,也就是网址链接。Python提供了urllib2函数进行链接。具体如下:
import urllib2
req=urllib2.Request(‘http://www.baidu.com.cn‘)
fd=urllib2.urlopen(req)
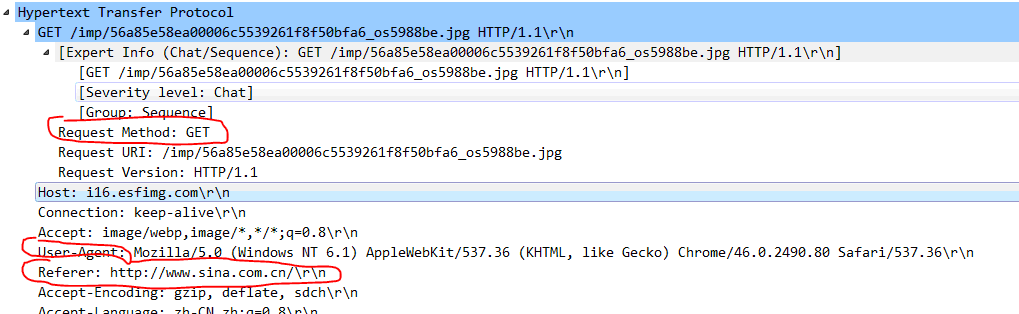
Request里面的第一个参数为网址的链接,里面还可以携带头信息以及具体要传递给网址的信息。这样说比较抽象。我们用wireshark抓取一个上网的报文。在google浏览器中输入www.sina.com.cn.可以看到如下信息。这就是从电脑上发出去的请求。其中有几个关键信息:Request Method: Get. 这里有两种方式,Get和Post,Get主要是用于请求数据,Post可以用来提交数据。
User-Agent指的是用户代码,什么意思呢。通过这些消息,服务器就能够识别客户使用的操作系统以及浏览器。一般服务器可以通过来识别是否是爬虫。这个后面讲
Referer可以认为是你需要从服务器上请求什么网址,这里可以看到就是sina
Accet-Encoding: 这是告诉电脑可以接受的数据压缩方式。
上图是浏览器上输入网址得到的抓包结果。如果我们运行程序结果会如何呢。下图是刚才python代码的截图结果。访问的网址是百度。从下面可以看到明显的差别。最重要的就是User-Agent变成了Python-urllib2/2.7. 这个字段给服务器一个明确的提示,这是一个程序发起的网页链接,也就是爬虫,而不是坐在电脑前的人在访问。由于爬虫进行链接一样会进行TCP等底层链接,因此为了防止大规模爬虫同时进行网页爬取。服务器会根据User-Agent来判断,如果是爬虫,则直接拒绝。
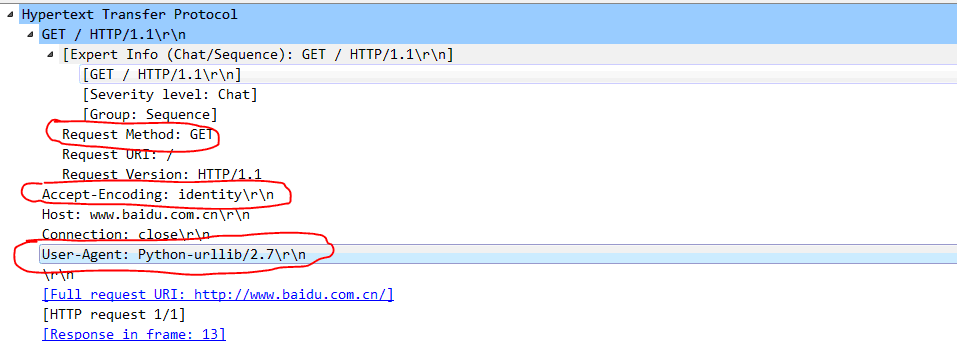
那么为了防止服务器禁掉我们的申请,该如何应对呢。我们自程序中自己构造一个和真实浏览器一样的User_Agent不就一样了。
user_agent="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
headers={‘User-Agent‘:user_agent}
req=urllib2.Request(‘http://www.baidu.com.cn‘,‘‘,headers)
fd=urllib2.urlopen(req)
添加了headers的描述。Request的第一个参数是网址,第二个参数是提交的数据,第三个参数是头信息。这里第二个参数暂时为空。第三个参数添加头信息,以字典的形式。可以看到抓包信息如下。这里就变成了我们和浏览器一样的形式,这样服务器就不会认为是爬虫了。下一步就是放心的抓取网页数据了。

有同学可能会问,如果我不小心输错了网址,该怎么办呢。这就要用到python的异常保护机制了。代码可以修改如下:
try:
user_agent="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
headers={‘User-Agent‘:user_agent}
req=urllib2.Request(‘http://www.baidu.com.cn‘,‘‘,headers)
fd=urllib2.urlopen(req)
print fd.read().decode(‘utf-8‘).encode(‘GB18030‘)
html=BeautifulSoup(fd.read(),"lxml")
# print html.encode(‘gbk‘)
except urllib2.URLError,e:
print e.reason
增加了保护机制,其中URLError在没有网络连接或者服务器不存在的情况下产生,这种情况下,异常通常会带有reason属性.HTTP的错误码如下,具体参考HTTP权威指南
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304 请求的资源未更新 处理方式:丢弃
400 非法请求 处理方式:丢弃
401 未授权 处理方式:丢弃
403 禁止 处理方式:丢弃
404 没有找到 处理方式:丢弃
5XX 回应代码以“5”开头的状态码表示服务器端发现自己出现错误,不能继续执行请求 处理方式:丢弃
下面就是要打印出获取到的网页信息了。Request返回一个获取网页的实体,urlopen则是实现打开网页fd.read()则可以打印出网页的具体信息
代码里面有这个decode和encode的消息。这个是干嘛用的呢。这个主要是针对网页中的中文。Python3之前的中文输出是一个很忧伤的事情。
print fd.read().decode(‘utf-8‘).encode(‘GB18030‘)
网页上的数据也有自己的编码方式,从下面的截图的网页代码看到编码方式是utf-8.而在windows中中文的编码方式是GBK。
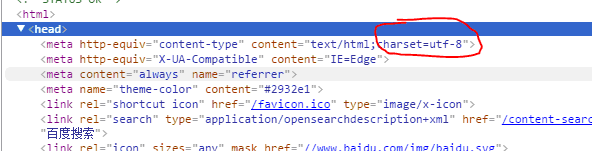
因此如果不进行编码转换的话,网页中的中文就会是乱码形式:

那么是否可以提前获取网页的编码方式呢,这也是可以的。如下代码就可以得到网页返回的编码方式
fd1=urllib2.urlopen(req).info()
print fd1.getparam(‘charset‘)
到此,我们已经成功的进行网页链接,并获取到了网页内容。下一步就是进行网页解析了。后面讲介绍beautifulSoup,lxml,HTMLParser,scrapy,selenium等常用的爬虫工具用法
标签:出现 告诉 遇到 mozilla ram 应用 urllib2 参数 三方
原文地址:https://www.cnblogs.com/ltn26/p/10981386.html