标签:muse 爬虫学习 rmi 随机 logger 请求 use 工程 mes
scrapy源码解析参考连接:https://www.jianshu.com/p/d492adf17312 ,直接看大佬的就行了,这里便就不多说了。
今天要学习的是:Scrapy框架中的download middlerware【下载中间件】用法。
一:官方文档中,对下载中间件的解释如下
下载中间件是介于scrapy的requests/response处理的钩子框架,是用于全局修改scrapy requests和response的一个轻量、底层的系统。
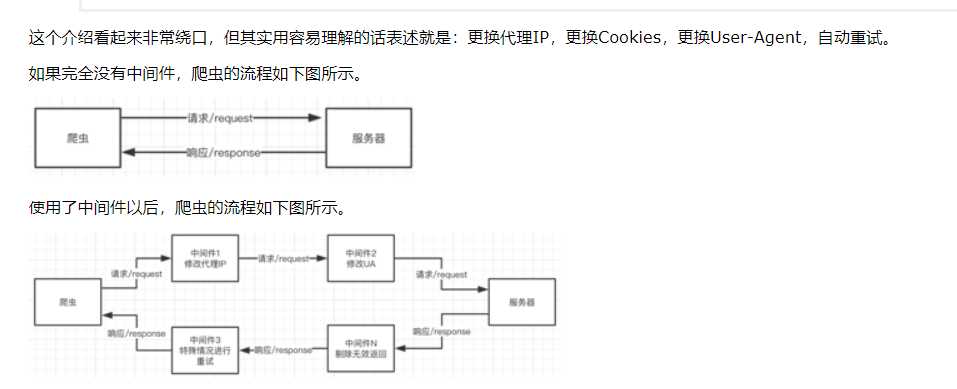
二:使用下载器中间件时必须激活这个中间件,方法是在settings.py文件中设置DOWNLOADER_MIDDLEWARES这个字典,格式类似如下
DOWNLOADER_MIDDLEWARES = {
‘scrapy_test.middlewares.ScrapyTestDownloaderMiddleware‘: 543,
}
数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,processrequest()优先处理;数字越大的,process_response()优先处理;
若需要关闭某个中间件直接设为None即可。由于中间件是按顺序运行的,因此如果遇到后一个中间件依赖前一个中间件的情况,中间件的顺序就至关重要如何确定后面的数字应该怎么写呢?
最简单的办法就是从543开始,逐渐加一,这样一般不会出现什么大问题。如果想把中间件做得更专业一点,那就需要知道Scrapy自带中间件的顺序,如图下图1.1所示。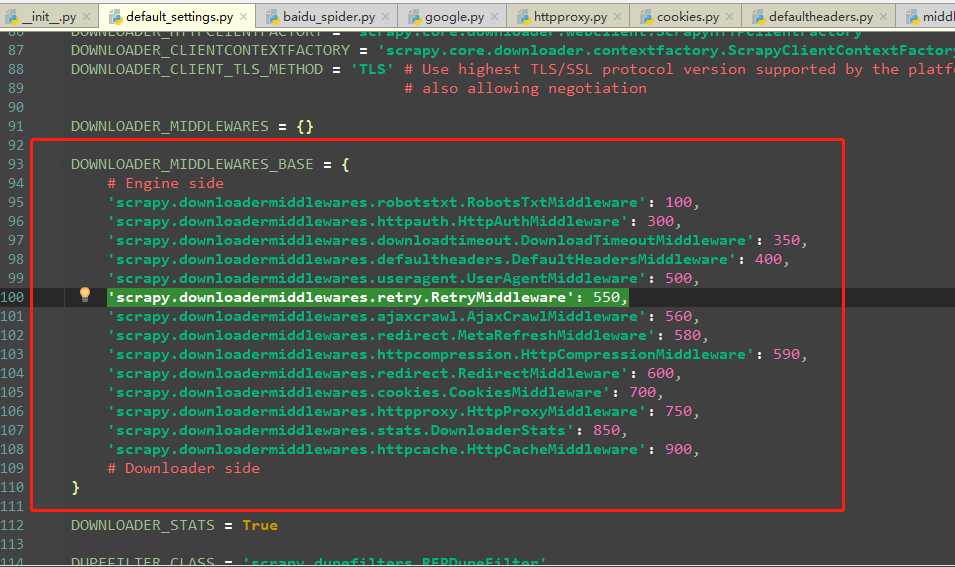
三:中间件的理解
中间件本身是一个Python的类,只要爬虫每次访问网站之前都先“经过”这个类。在创建一个Scrapy工程以后,工程文件夹下会有一个middlewares.py文件,打开以后其内容如下图 2 所示。
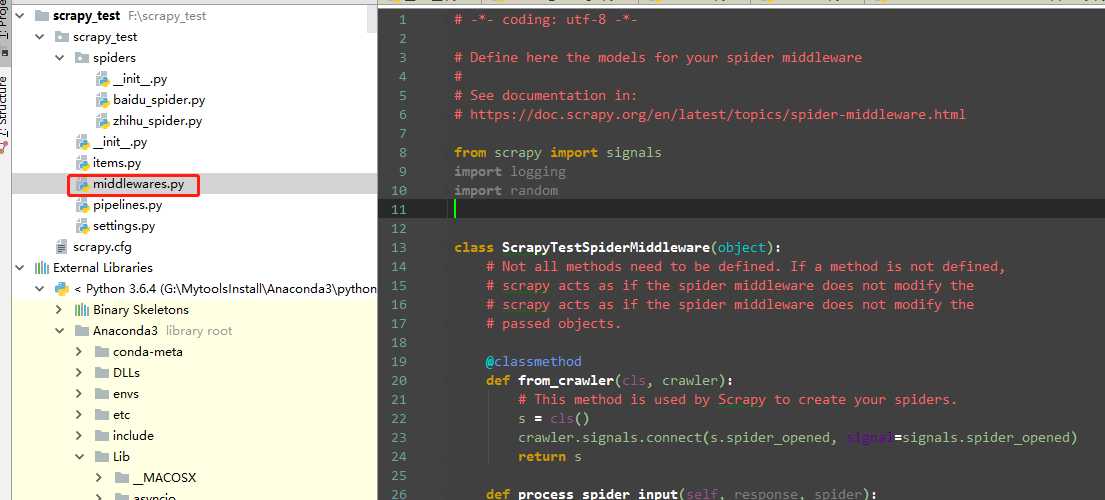
Scrapy自动创建的这个中间件是一个爬虫中间件。而我们学习这些中间件的目的就是为了自己改写添加一些中间件。那么我们就需要看懂这些中间件做了什么。我们基本上是需要修改,代理中间件、UA中间件.....
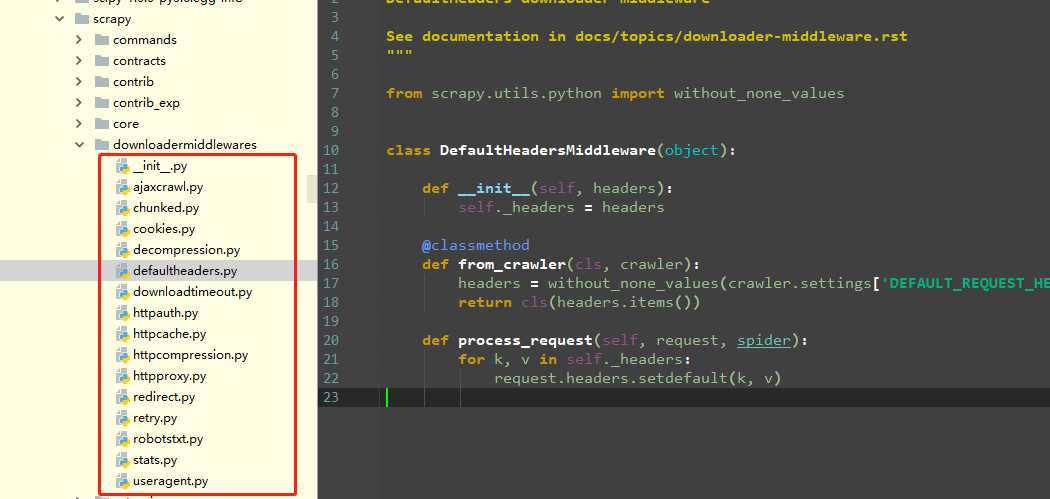
首先去看一下下载中间件信息如图3,这里中间件包含了请求头的设置、代理的设置、以及robot协议,那么单独去看一下这些默认信息。
四:那么这里便改写两个中间件,第一个是改写代理 IP、第二个是改写 UA、
一:由于当每个request通过下载中间件时,process_request(request,spider) 该方法被调用,直接看一下大佬理解的图片 5 如下:

4.1:第一个是改写代理 IP
4.1.1:修改代理 在middlewares.py中添加下面一段代码:
# 自己配置的都放在下面
class ProxyMiddleware(object):
logger = logging.getLogger(__name__)
def process_request(self, request, spider):
self.logger.debug("using Proxy")
request.meta[‘proxy‘] = ‘http://120.79.62.89:3128‘ # 自己去免费的代理网站采集几个。
return None
4..1.2:在settings文件中添加这段代码:
DOWNLOADER_MIDDLEWARES = {
# ‘scrapy_test.middlewares.ScrapyTestDownloaderMiddleware‘: 543,
‘scrapy_test.middlewares.ProxyMiddleware‘: 400,
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘: None, # 这个是吧默认的default_setting文件中的给禁掉。
}
4.1.3:测试网站是:http://httpbin.org/get
4.1.4:spider代码
# -*- coding: utf-8 -*-
import scrapy
class HttpbinSpider(scrapy.Spider):
name = ‘httpbin‘
allowed_domains = [‘httpbin.com‘]
start_urls = [‘http://httpbin.org/get‘]
def parse(self, response):
print(response.text)
# print("此状态吗为:", response.status)
4.1.5:运行结果如下截图6所示:
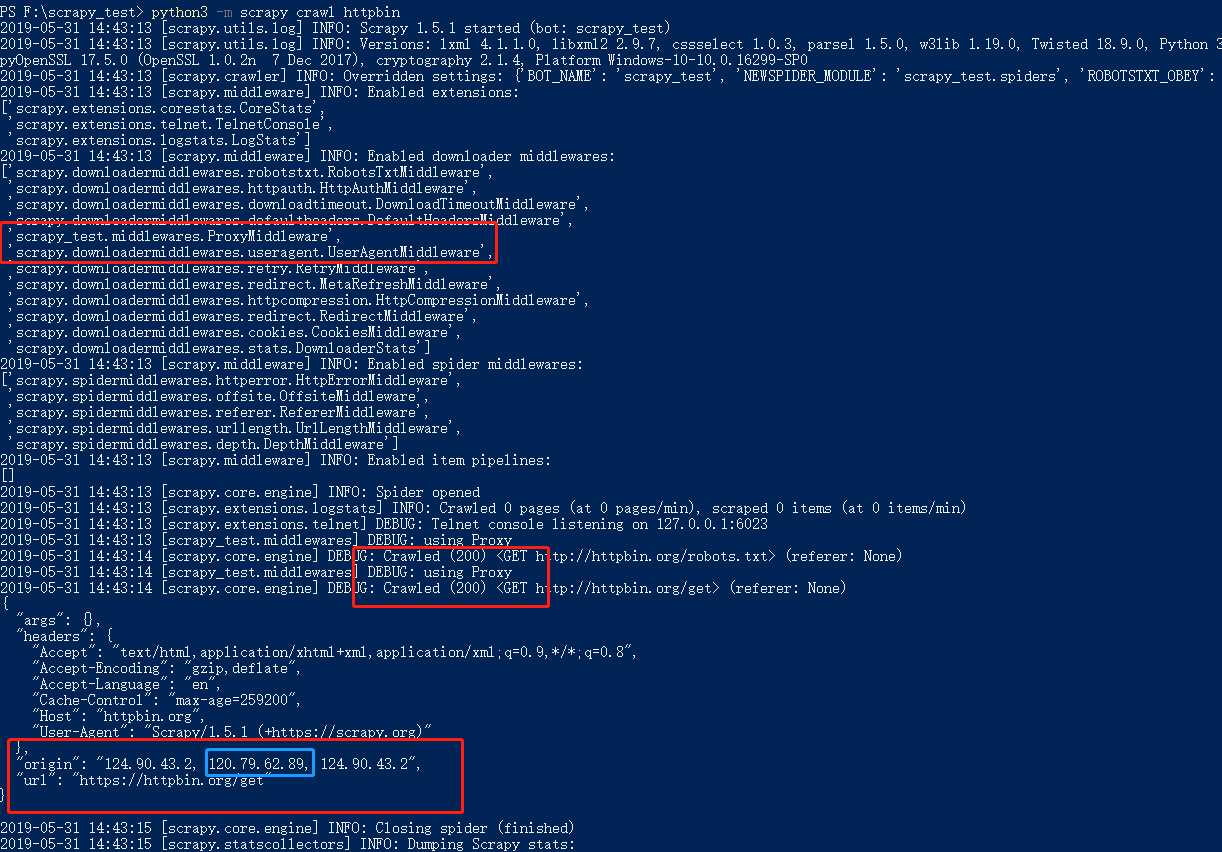
4.2:开发UA中间件
4.2.1:当我们不改变代理的情况下可以看一下默认的代理是如下图 7:
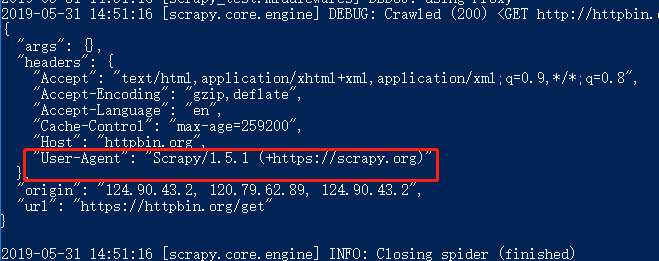
开发UA中间件和开发代理中间件几乎一样,它也是从settings.py配置好的UA列表中随机选择一项,加入到请求头中。代码如下:
4.2.2:middlewares.py
import random
from scrapy_test.settings import USER_AGENT_LIST
class RandomUserAgentMiddleware(object):
logger = logging.getLogger(__name__)
def process_request(self, request, spider):
rand_use = random.choice(USER_AGENT_LIST)
if rand_use:
self.logger.debug("using Random Headers")
request.headers.setdefault(‘User-Agent‘, rand_use)
4.2.3:settings文件
DOWNLOADER_MIDDLEWARES = {
# ‘scrapy_test.middlewares.ScrapyTestDownloaderMiddleware‘: 543,
‘scrapy_test.middlewares.ProxyMiddleware‘: 400,
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘: None,
# 添加这两项即可。
‘scrapy_test.middlewares.RandomUserAgentMiddleware‘: 400,
‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware‘: None,
}
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Dalvik/1.6.0 (Linux; U; Android 4.2.1; 2013022 MIUI/JHACNBL30.0)",
"Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; HUAWEI MT7-TL00 Build/HuaweiMT7-TL00) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"AndroidDownloadManager",
"Apache-HttpClient/UNAVAILABLE (java 1.4)",
"Dalvik/1.6.0 (Linux; U; Android 4.3; SM-N7508V Build/JLS36C)",
"Android50-AndroidPhone-8000-76-0-Statistics-wifi",
"Dalvik/1.6.0 (Linux; U; Android 4.4.4; MI 3 MIUI/V7.2.1.0.KXCCNDA)",
"Dalvik/1.6.0 (Linux; U; Android 4.4.2; Lenovo A3800-d Build/LenovoA3800-d)",
"Lite 1.0 ( http://litesuits.com )",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Linux; U; Android 4.1.1; zh-cn; HTC T528t Build/JRO03H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30; 360browser(securitypay,securityinstalled); 360(android,uppayplugin); 360 Aphone Browser (2.0.4)",
]
4.2.4:spider代码
# -*- coding: utf-8 -*-
import scrapy
class HttpbinSpider(scrapy.Spider):
name = ‘httpbin‘
allowed_domains = [‘httpbin.com‘]
start_urls = [‘http://httpbin.org/get‘]
def parse(self, response):
print(response.text)
# print("此状态吗为:", response.status)
4.2.5:结果如下图8所示
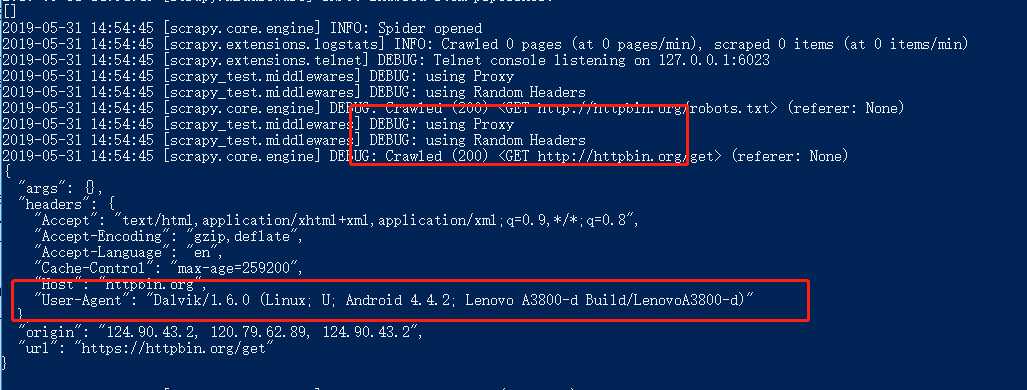
4.2.6:当然这是全局修改请求头,你也可以单独修改一个spiders的请求头,例如看源码
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
"""
name = None
custom_settings = None # 这点就可以单独在每一个爬虫中修改。
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, ‘name‘, None):
raise ValueError("%s must have a name" % type(self).__name__)
4.2.6.1:那么修改spider的代码如下:
# -*- coding: utf-8 -*-
import scrapy
class HttpbinSpider(scrapy.Spider):
name = ‘httpbin‘
allowed_domains = [‘httpbin.com‘]
start_urls = [‘http://httpbin.org/get‘]
custom_settings = {
"DEFAULT_REQUEST_HEADERS": {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36‘,
}}
def parse(self, response):
print(response.text)
# print("此状态吗为:", response.status)
4.2.6.2:看结果如下图 9 所示:
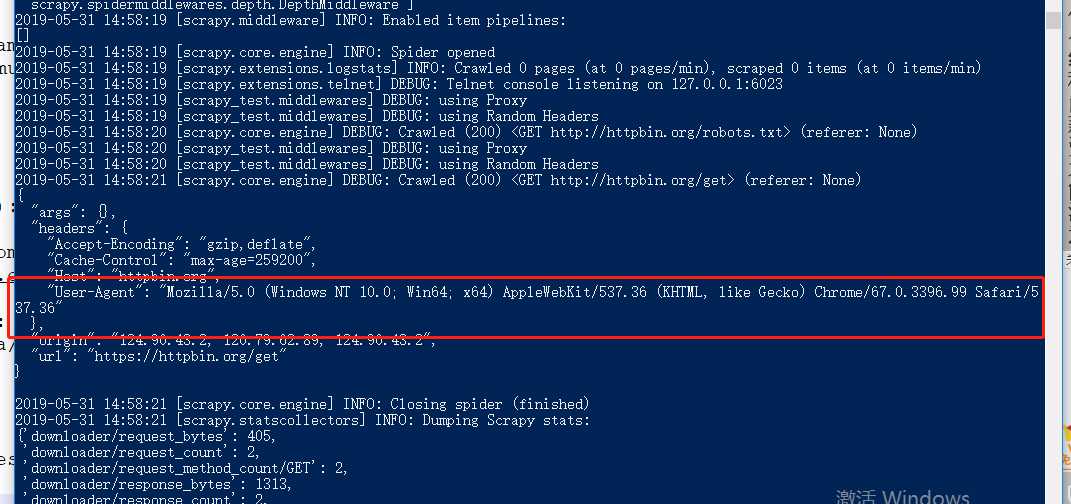
当然还有第三种、第四种方法如下:
修改settings文件如下:
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,
‘Accept-Language‘: ‘en‘,
# 打开默认,覆盖掉 request headers,结果是相同的。
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36‘,
}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# ‘scrapy_test.middlewares.ScrapyTestSpiderMiddleware‘: 543,
# }
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# # ‘scrapy_test.middlewares.ScrapyTestDownloaderMiddleware‘: 543,
# ‘scrapy_test.middlewares.ProxyMiddleware‘: 400,
# ‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘: None,
# ‘scrapy_test.middlewares.RandomUserAgentMiddleware‘: 400,
# ‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware‘: None,
#
# }
结果和上图一样,这里就不展示了。
你以为就这么多方法,当然还有还是在settings文件找到如下代码:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = ‘scrapy_test (+http://www.yourdomain.com)‘ 把这个打开并修改掉
例如改成:
USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36‘
## 参考大佬博客如下:
https://www.cnblogs.com/zhaof/p/7345856.html
https://blog.csdn.net/mouday/article/details/80776030
https://www.cnblogs.com/xieqiankun/p/know_middleware_of_scrapy_1.html
标签:muse 爬虫学习 rmi 随机 logger 请求 use 工程 mes
原文地址:https://www.cnblogs.com/fierydragon/p/10984114.html