标签:blog label mamicode 代码 mil 返回值 run 大小 import
前面一篇博客讲解了softmax函数,下面讲解一下这个代码的意思:
具体的执行流程大概分为两步:
1 第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes
2 第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵,公式如下:
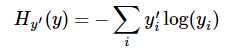
其中yi‘指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
yi就是softmax的输出向量[Y1,Y2,Y3...]中,第i个元素的值
显而易见,预测越准确,结果的值越小(别忘了前面还有负号),最后求一个平均,得到我们想要的loss
这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到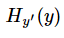
tf.reduce_mean操作,对向量求均值!
tf.nn.softmax_cross_entropy_with_logits(logits= , labels=)。
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
交叉熵代码:
import tensorflow as tf #our NN‘s output logits=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]]) #step1:do softmax y=tf.nn.softmax(logits) #true label y_=tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]]) #step2:do cross_entropy cross_entropy = -tf.reduce_sum(y_*tf.log(y)) #do cross_entropy just one step ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=tf.argmax(y_, 1)) cross_entropy2=tf.reduce_sum(ce) #cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits, y_)) #dont forget tf.reduce_sum()!! with tf.Session() as sess: softmax=sess.run(y) c_e = sess.run(cross_entropy) c_e2 = sess.run(cross_entropy2) print("step1:softmax result=") print(softmax) # print("step2:cross_entropy result=") print(c_e) print("Function(softmax_cross_entropy_with_logits) result=") print(c_e2)
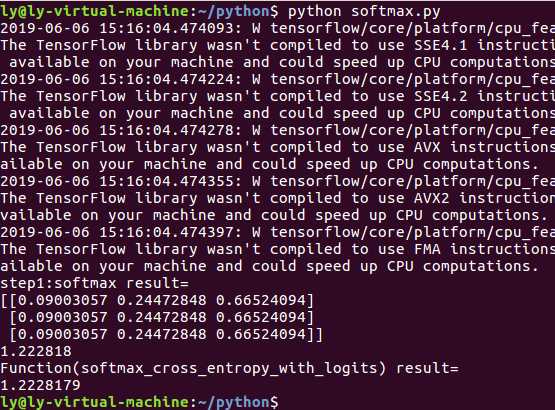
求出交叉熵符合公式推导
tf.nn.softmax_cross_entropy_with_logits的用法
标签:blog label mamicode 代码 mil 返回值 run 大小 import
原文地址:https://www.cnblogs.com/fcfc940503/p/10985129.html