标签:sch 时间 分表 mysql 实时 种类 基于 last 调用
本文介绍Phoenix在2345公司的实践,主要是实时查询平台的背景、难点、Phoenix解决的问题、Phoenix-Sql的优化以及Phoenix与实时数仓的融合思路。具体内容如下:
实时数据查询时客服系统中一个很重要的模块,提供全公司所有主要产品的数据的查询功能,由于各产品的数据库、数据表错综复杂、形式多样,在平台建设的初期走了很多弯路。本文后续会详细介绍实时数据查询迭代升级的过程、期间遇到的问题以及对应的解决方案。
目前公司的数据库类型主要有MySQL和MongoDB。它们本身是异构的,二者都会涉及分库、分表,还有冷表、热表。分库分表的字段不同、个数不同;冷热表的实现方式也不同,有些产品是冷热双写,有些则是热表过期插入到冷表;还有周表、月表、自定义分表逻辑等。
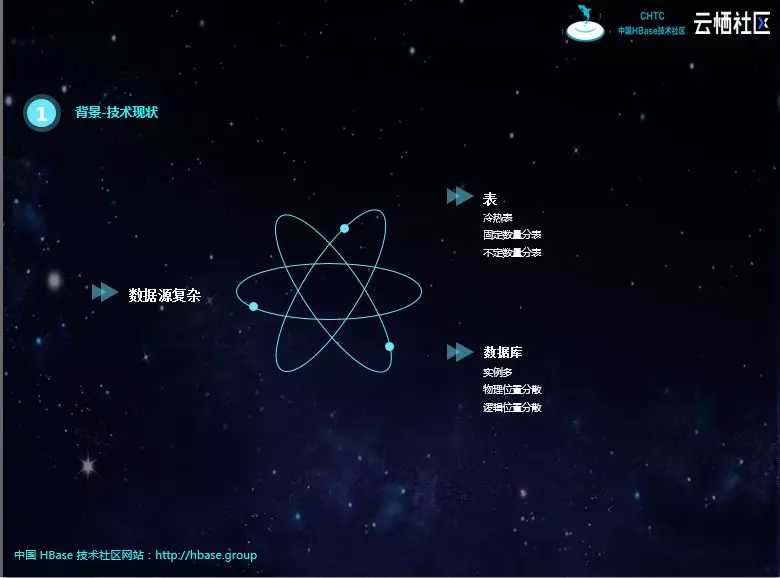
在物理位置上,这些数据库实例会分布在不同的节点,如果用JDBC查询需要配置不同的连接。再加上根据产品性质,一般会查询从库,而由于技术原因,从库的物理位置会变化,配置起来也会比较麻烦。
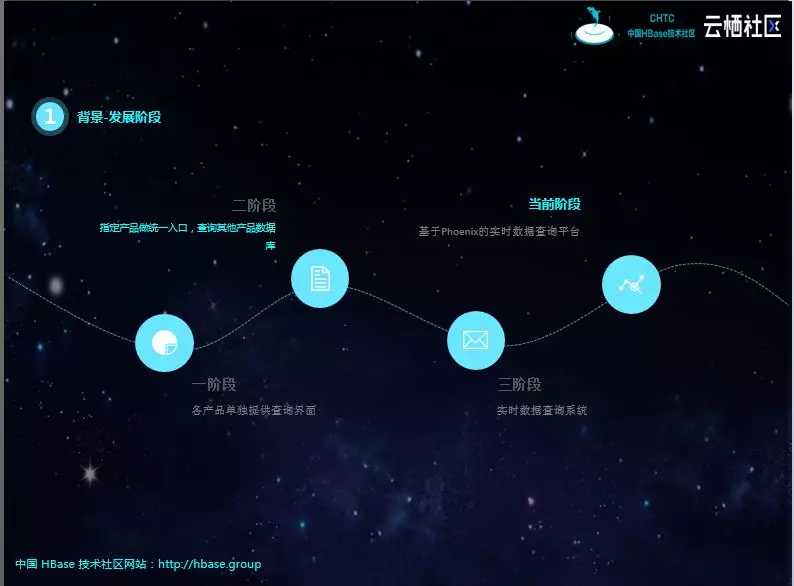
系统的迭代进程大概分为四个阶段。
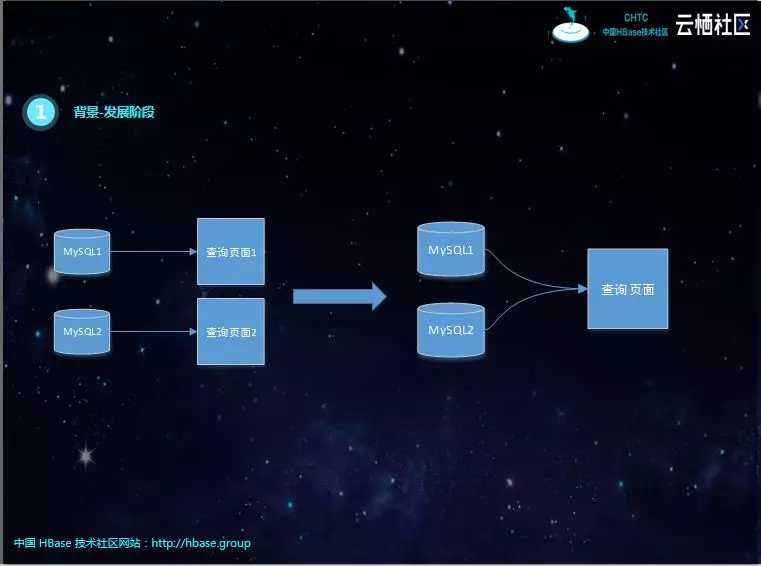
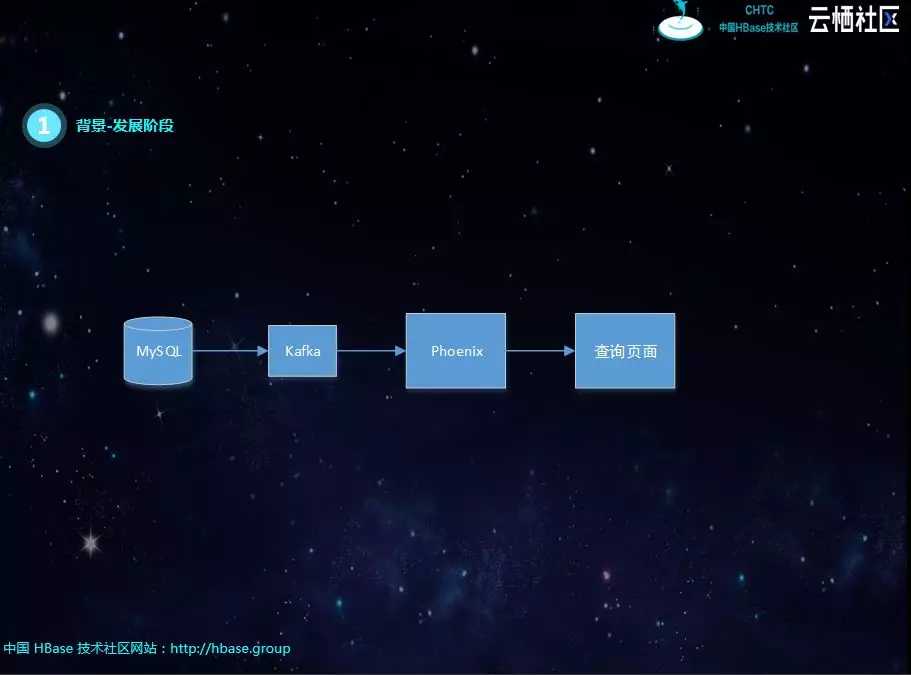
初期,产品少、数据库形式简单、库和表数量少,各产品单独提供查询页面。
后面各查询页面整合,提供统一的界面,但随着数据库、表结构形式复杂,开发任务逐渐变得繁重,难以为继。特别是查询条件复杂,需要上游业务表创建对应的索引,对业务具有一定的侵入性。
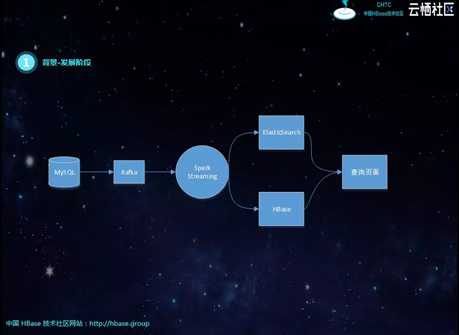
第三阶段,组件单独团队开发,将MongoDB、MySQL实时同步到Kafka,屏蔽分库、分表、冷热表等结构化差异,基于实时流的订阅机制,对数据进行聚合插入ElasticSearch和HBase。但会面临实时流Join,经常丢数据,造成数据不准;性能也跟不上,特别是新增查询表,需要全量铺底的时候。后期增加了T+1补数机制,虽然弥补了数据缺失的问题,但容易造成实时逻辑与离线逻辑不一致的问题。
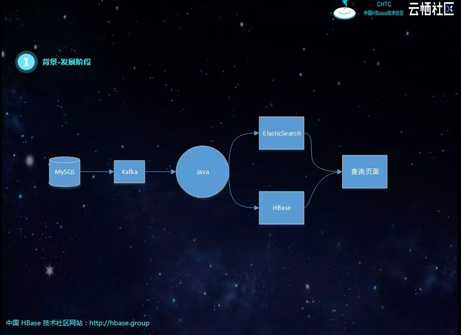
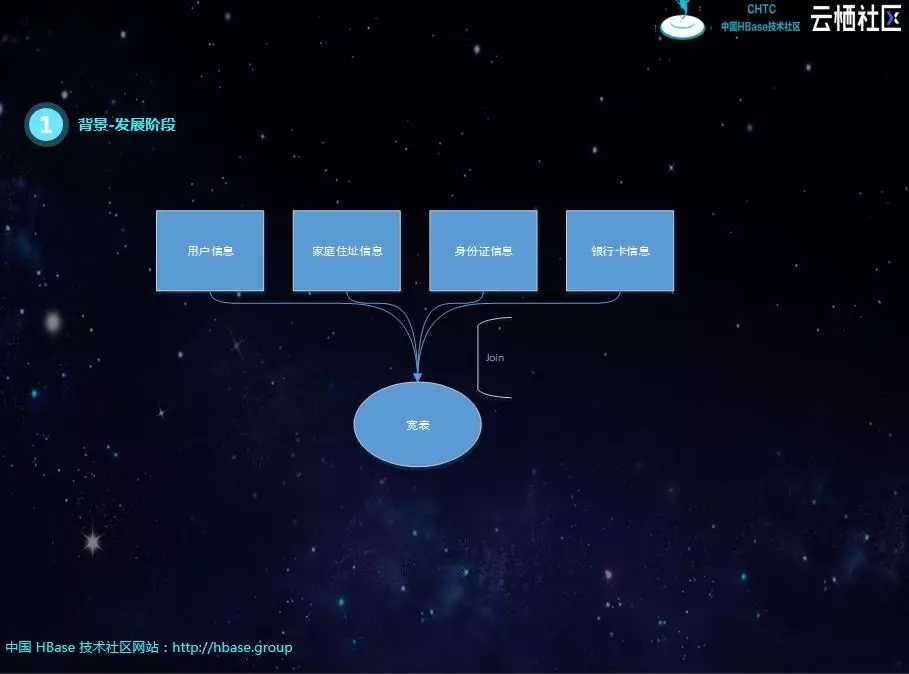
其实这个阶段最大的问题就是实时流的Join,比如下图中有一个宽表需要四个表进行关联,每个表之间的关联字段不同,如果有一个表的数据没有到,就必须等待。刚开始是SparkStreaming进行微批处理,但每个库数据的到达顺序、时延不同,很容易出现关联不上的现象,导致数据丢失。后面有用java代码重构了SparkStreaming的逻辑,将关联不上的数据进行缓存,进行重试,但考虑到网络抖动的问题,不能无限次重试。仍然不能解决数据丢失的问题,由于重试的存在,性能也会受到很大的影响。
最后选择Phoenix作为数据存储和查询引擎,基本解决了所有的难题。数据经过Kafka写入Phoenix表,不再进行实时ETL也就是没有实时join 。该方案屏蔽了数据库异构,形式不同的问题;查询页面通过Phoenix-Sql,也解决了实时流Join的问题。虽然没有解决数据时延,但数据到齐后即可查询到,不存在重试和丢数据。
下面介绍引入思路。其实就是参考Schema on Read & Schema on Write的概念,把Schema on Write 改成Schema on Read ,其实就是计算逻辑后置到查询的时候。虽然简单,但有时候思路决定出路。
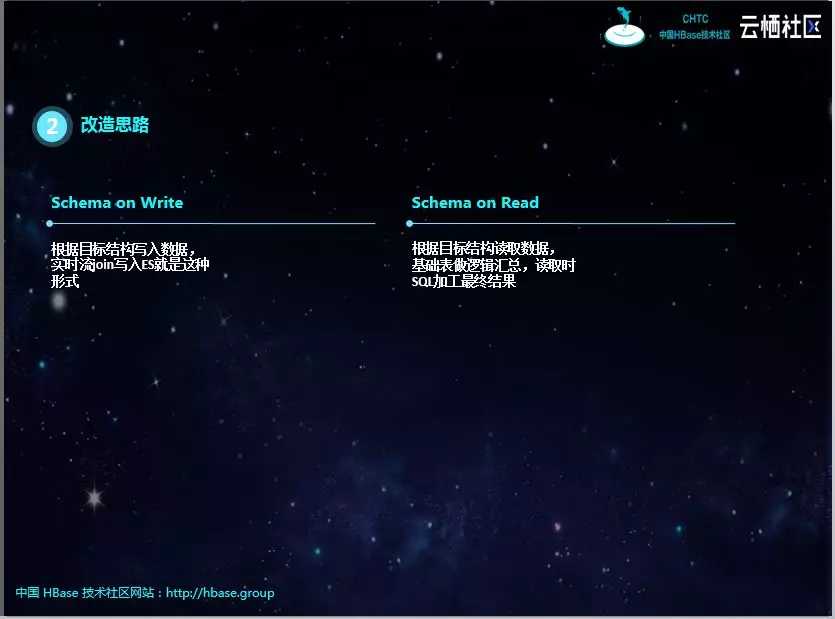
Schema on Write 定义好目标表结构,根据定义写入数据,需要提前进行关联清洗;Schema on Read 直接源表数据进行查询,不再提前进行清洗,优先写入数据。知道了二者的差别,改造起来也变得简单了。
思路有了,就要选择技术。其实根据上面的思路,选择用MySQL做数据存储和查询引擎也是可以的。但考虑到上游业务库的数量和数据量,同步到一个MySQL压力还是很大的。如果并发写入,MySQL可能扛不住,串行则写入性能低下。综合Phoenix的优点,最终选择了它。
Phoenix可以帮助我们屏蔽数据源的异构、数据库SCHEMA和表的异构,统一了数据视图。
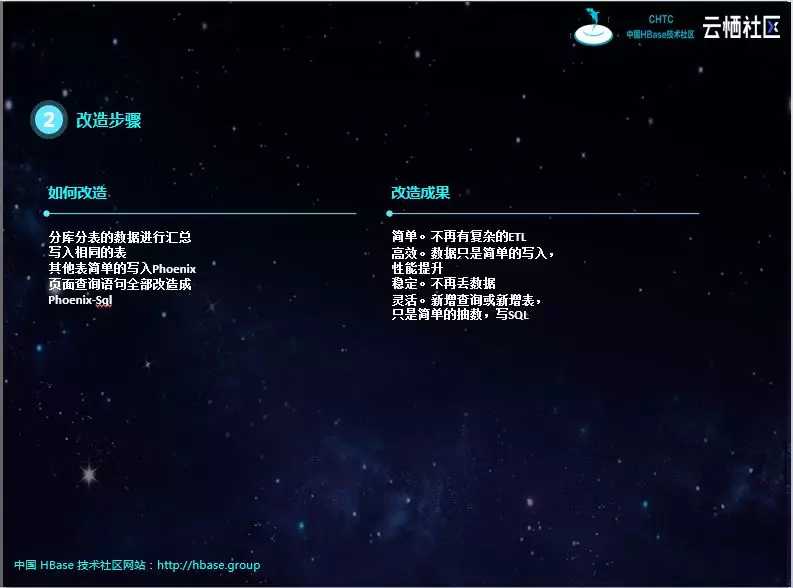
有了思路和技术方案,改造起来就顺利多了。简单来说就是把上游业务库的数据简单的同步到Phoenix中,结构相同的数据写入同一张Phoenix表,比如分库分表、冷热表;对Phoenix表按照查询条件创建二级索引;查询页面调用后台的SQL语句即可。但注意Phoenix表的主键是源表分库分表的序号和源表主键组合而成。
改造后的实时查询平台,变得简单、高效、稳定、灵活,用户体验非常好。
高性能的SQL是系统升级的关键。如果查询性能和写入性能跟不上,会直接宣告升级失败。
写入性能跟HBase的节点数、预分区个数有关,这里不再详细介绍。主要讲解如何进行查询优化,简单来说就是创建合理的索引。
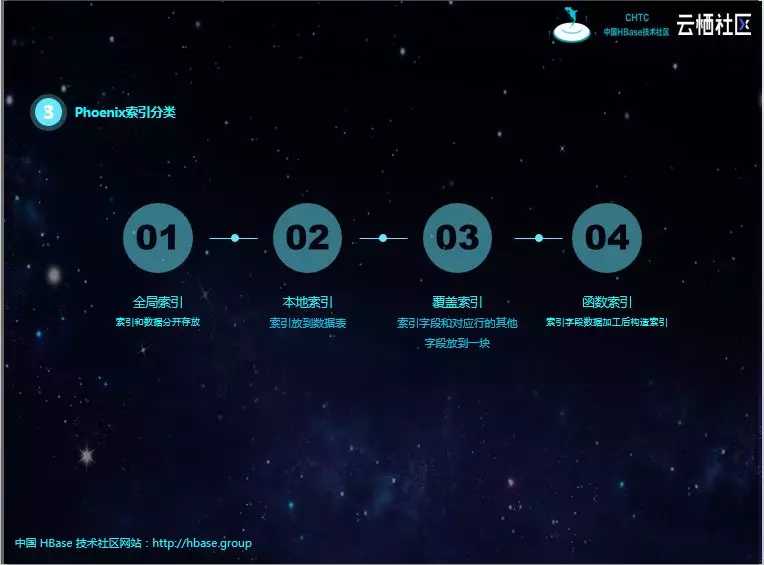
Phoenix的索引类型有以下四种。
全局索引适用于多读少写的场景。写入时可能跨region。
本地索引适用于写多读少,空间有限的场景,和全局索引一样,Phoneix在查询时会自动选择是否使用本地索引,为避免进行写操作所带来的网络开销,索引数据和表数据都存放在相同的服务器中,当查询的字段不完全是索引字段时本地索引也会被使用,与全局索引不同的是,所有的本地索引都单独存储在同一张共享表中,由于无法预先确定region的位置,所以在读取数据时会检查每个region上的数据因而带来一定性能开销。
覆盖索引只需要通过索引就能返回所要查询的数据,所以索引的列必须包含所需查询的列(SELECT的列和WHRER的列)。
函数索引从Phoeinx4.3开始支持函数索引,其索引不局限于列,可以合适任意的表达式来创建索引,当在查询时用到了这些表达式时就直接返回表达式结果。
此次改造我们只使用了全局索引,因为如果使用得当,完全没有使用其他三种类型索引的必要。
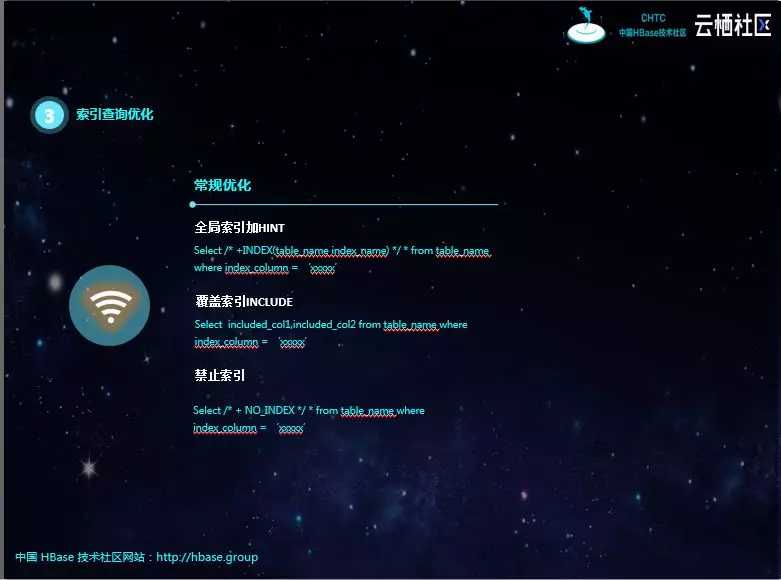
全局索引加HINT是一种常见的优化方案,因为如果不显式的加HINT,是不会走索引的。但这种方式的问题就是索引的名称无法修改。
覆盖索引会无形增加存储的压力,个人觉得很不划算,而且如果临时需要增加一个查询字段,是需要修改索引的。如果源表数据量很大,重建索引的代价是非常大的。
禁止索引也是一种常规优化。如果不是前缀扫描,查询索引的性能损耗是非常大的,得不偿失,此时禁止索引是最好的选择。
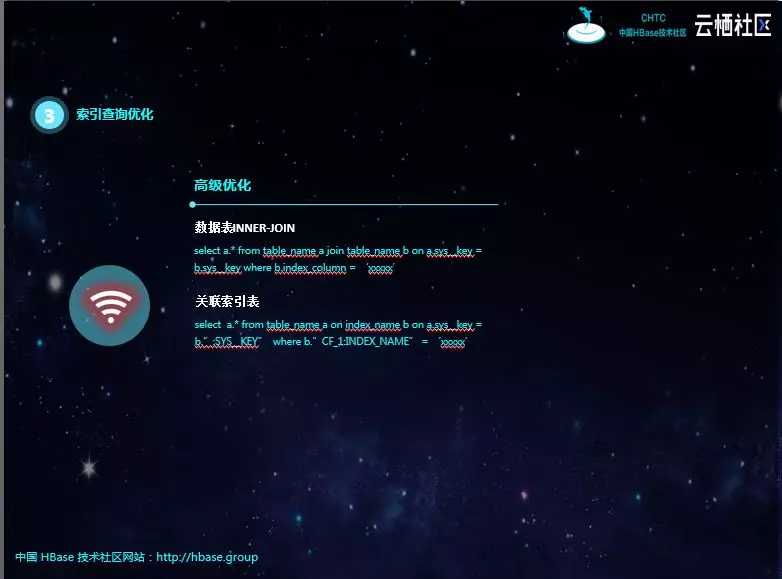
高级优化有两种方式,这需要对Phoenix的索引原理有深刻的理解,才能知道这两种优化的由来及其原理。Inner-join其实深刻理解了走Phoenix索引的机制:当查询字段全都在索引表中时才会走索引。Phoenix索引包含索引字段和主键,通过inner-join,其中一个表只查询索引字段和主键,则一定会走索引,另一个表通过主键查询其他字段是很快的。所以,这个inner-join先通过查询字段找到对应数据的主键,再通过主键反查数据表得到数据的其他字段,而索引查询和主键查询都是非常快的。
直接查询索引表,需要理解Phoenix索引其实就是一个普通的Phoenix表。可以直接关联索引表进行查询,这种方式跟inner-join差不多,只不过更直接,且不会受索引状态的影响。如果索引失效,inner-join也会很慢,但这种方式就不会。
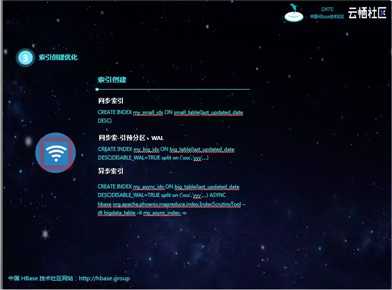
索引的创建也是我们此次优化的重点。
创建同步索引适用于小表;设置预分区和禁止WAL一般适用大表;对于特大表,一般使用官方提供的IndexScrutinyTool工具创建异步索引。但该工具的原理是创建MR作业,并行扫描源表然后创建索引,其实速度还是有一定限制的。如果表数据量过大,该工具的性能也不太好,而且也容易失败。
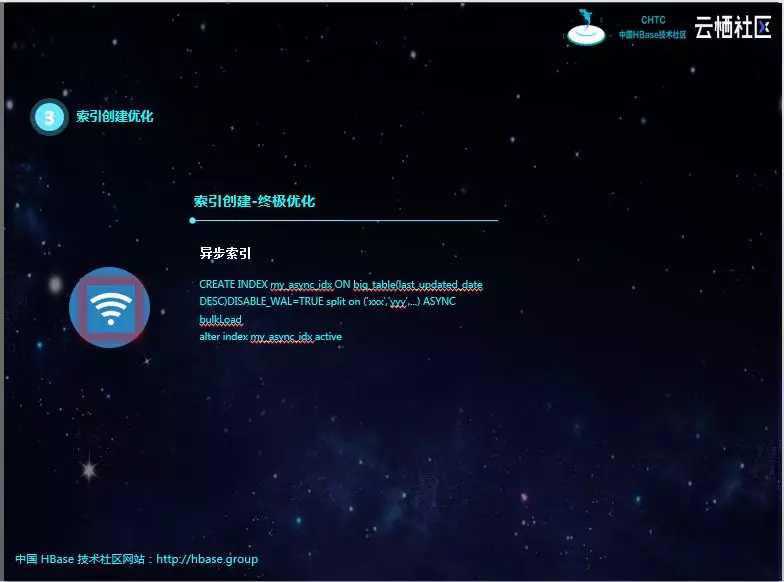
经过研究以及对Phoenix索引原理的深刻理解,我们对异步索引的创建方式进行了改进。数据在导入Phoenix之前,HIVE中会有一份全量数据,一般进行离线分析。而我们可以通过HQL将该数据按照索引的格式,直接导出为HFile文件,再通过HBase提供的bulkLoad将索引的HFile直接导入,最后将其状态改成ACTIVE即可完成索引的创建。此种方式的性能最高,但需要额外的全量数据和HIVE技术栈。
Phoenix在完成对数据查询平台的改造和升级之后,还可以做更多的事。Phoenix是对HBase的扩展,数据存入Phoenix也就是存入HBase,所有其他基于HBase的应用都可以创建,再加上hive映射HBase进行离线分析,数据查询平台就变成了数据中台。
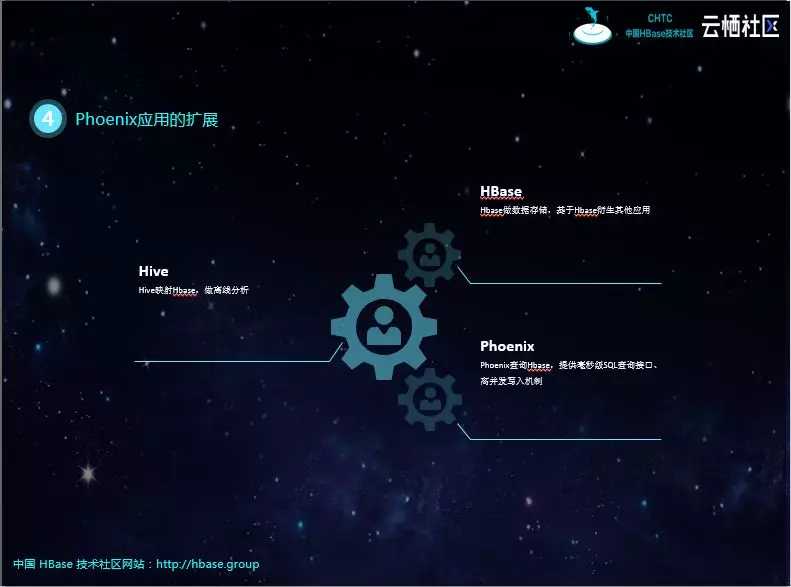
下面是我们基于Phoenix数据做的应用扩展,可以发现该架构下,既可以做实时查询,又可以做T+1离线分析,还可以做准实时(每小时或每30分钟甚至更短)报表。
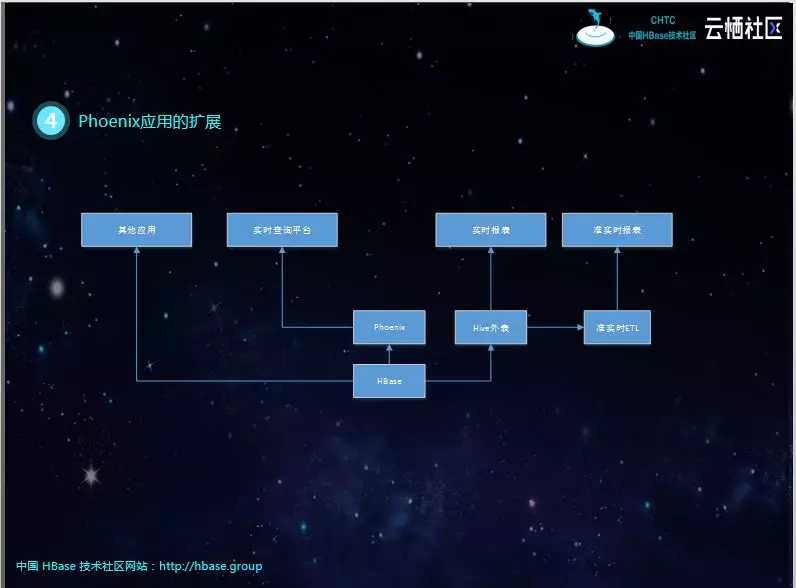
可以说上面的架构图极大的扩展了我们数据服务的边界。
最后说一下我们遇到的难题,以及对应的解决方案。

首先就是数据铺底的问题。Phoenix表是先导入数据,再创建索引,还是先创建索引再导入数据呢?我们选择了前者,因为数据和索引我们都是通过bulkLoad的方式导入的,速度非常快。
补数是必不可少的。无论是CDC故障还是网络抖动,数据总是有可能丢失的。映射Phoenix底层的HBase表后,我们会使用HQL对数据进行校验,计算出丢失的数据,再通过HIVE映射Phoenix表将数据补进去。
数据覆盖的问题也是很头疼的。其实就是同一个ID的两条更新数据没有按照顺序写入Phoenix时,如何确保最新的数据被写入。补数和实时写入就引起有顺序错乱的问题,比如补数脚本运行时候,发现数据缺失,在补数之前,实时又写入了最新数据,补数就会覆盖这个最新数据,造成数据的不一致。
通过修改Phoenix的源码,我们完美解决了这个问题。
简单来说就是增加了一个ROW_TS数据类型,该数据类型的字段的值会写入底层HBase的rowtimestamp,也就是数据的版本号。这样无论数据的写入顺序是怎样的,只要数据的更新时间映射到HBase的rowtimestamp就不会有问题,因为查询时候只能查询到版本最大也就是数据更新时间最大的那条记录。
时效性其实比较麻烦。目前CDC是接入到业务库的从库,如果从库数据有延时,Phoenix的数据就一定有延时,且不可控。另外如果集群写入压力过大,写入也会有延时。
离线分析性能也需要优化。Hive映射HBase进行分析时,也会遇到性能问题。比如分析师只需要查询最近几天的数据,在Hive中可以按照时间创建分区表,但Phoenix并没有分区的概念。后期我们将考虑修改Phoenix源码,增加分区的概念,将Phoenix表映射为底层不同的HBase表,也就是每个分区对应一个HBase表。同时具有统一的查询视图,也就是屏蔽分区表的底层逻辑。这样Hive就可以映射对应的分区HBase表,减少数据读取的数量。

本文转自:https://yq.aliyun.com/articles/704404
标签:sch 时间 分表 mysql 实时 种类 基于 last 调用
原文地址:https://www.cnblogs.com/gabry/p/10735889.html