标签:obs nal immediate different efi sam com min divide
Partitioner:
Partitioning and Combining take place between Map and Reduce phases. It is to club the data which should go to the same reducer based on keys. The number of partitioners is equal to the number of reducers. That means a partitioner will divide the data according to the number of reducers. Therefore, the data passed from a single partitioner is processed by a single Reducer. HashPartitioner is the default Partitioner in hadoop.
A partitioner partitions the key-value pairs of intermediate Map-outputs. It partitions the data using a user-defined condition, which works like a hash function. The total number of partitions is same as the number of Reducer tasks for the job. Records having the same key value go into the same partition (within each mapper).
Partition doing jobs on local machine.
Combiner:
Combiner is a ‘mini-reducer‘ (semi-reducer), used to process reducer‘s work before transfering data onto reducers. It can reduce network congestion. An example is shown below:
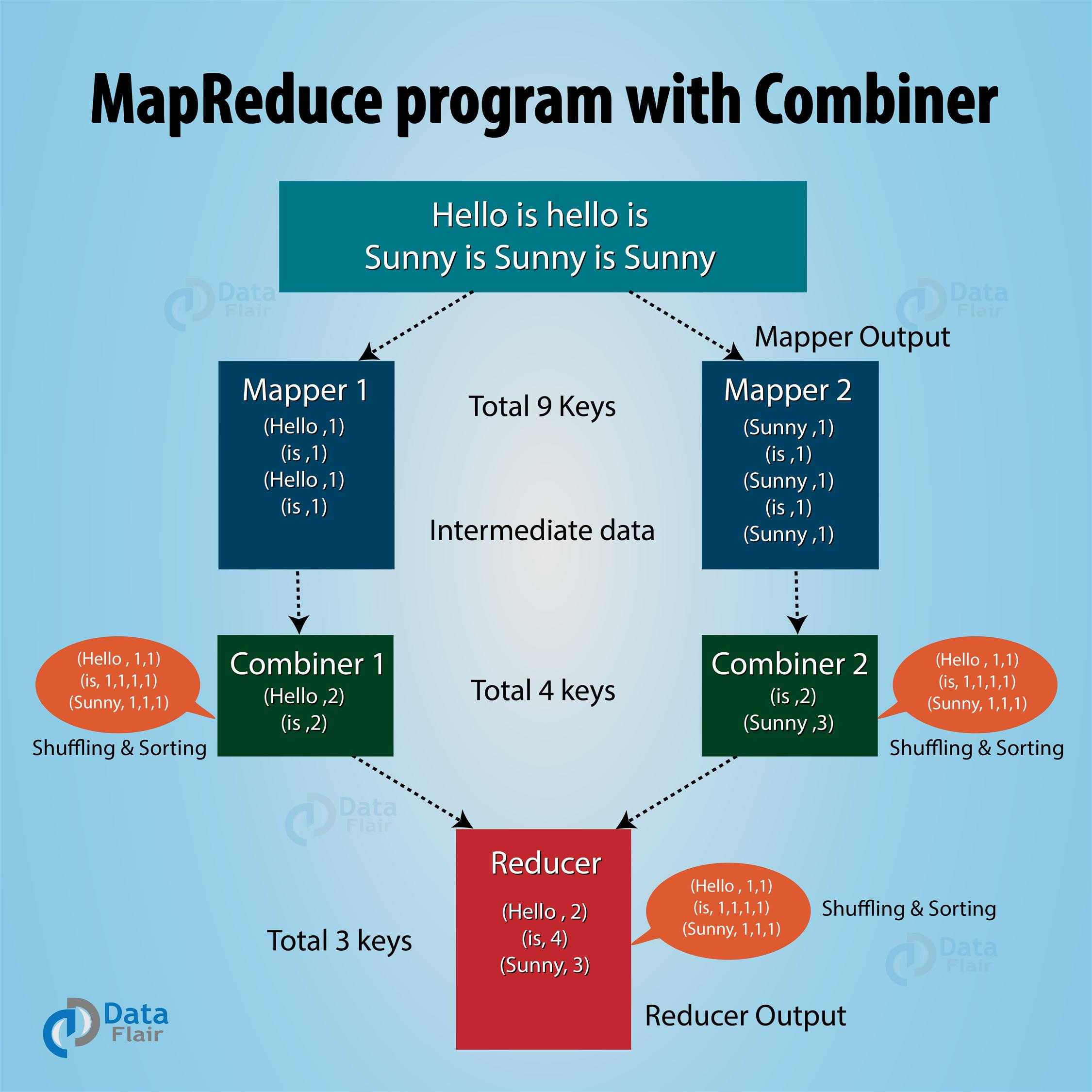
Shuffle:
shuffle notify master to copy files onto reducer machines. In the final output of map task there can be multiple partitions and these partitions should go to different reduce task. Shuffling is basically transferring map output partitions to the corresponding reduce tasks. Map task notified application master about completion of map task and application master notifies corresponding reducer to copy the map output into reduce machine.
References:
https://www.cnblogs.com/hadoop-dev/p/5910459.html
https://blog.csdn.net/bitcarmanlee/article/details/60137837
http://geekdirt.com/blog/map-reduce-in-detail/
Using hash function to map immediate K,V pairs
https://en.wikipedia.org/wiki/Hash_function
https://www.tutorialspoint.com/map_reduce/map_reduce_partitioner.htm
https://data-flair.training/blogs/hadoop-partitioner-tutorial/
MapReduce(3): Partitioner, Combiner and Shuffling
标签:obs nal immediate different efi sam com min divide
原文地址:https://www.cnblogs.com/rhyswang/p/10946833.html