标签:second option sparksql main 定义 应用程序 png res tap
官网http://spark.apache.org/docs/latest/streaming-programming-guide.html
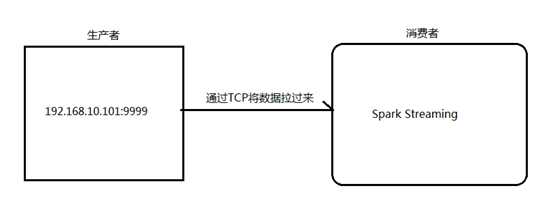
1.安装并启动生成者
首先在一台Linux(ip:192.168.10.101)上用YUM安装nc工具
yum install -y nc
启动一个服务端并监听9999端口
nc -lk 9999
2.编写Spark Streaming程序
package cn.itcast.spark.streaming import cn.itcast.spark.util.LoggerLevel import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} object NetworkWordCount { def main(args: Array[String]) { //设置日志级别 LoggerLevel.setStreamingLogLevels() //创建SparkConf并设置为本地模式运行 //注意local[2]代表开两个线程 val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") //设置DStream批次时间间隔为2秒 val ssc = new StreamingContext(conf, Seconds(2)) //通过网络读取数据 val lines = ssc.socketTextStream("192.168.10.101", 9999) //将读到的数据用空格切成单词 val words = lines.flatMap(_.split(" ")) //将单词和1组成一个pair val pairs = words.map(word => (word, 1)) //按单词进行分组求相同单词出现的次数 val wordCounts = pairs.reduceByKey(_ + _) //打印结果到控制台 wordCounts.print() //开始计算 ssc.start() //等待停止 ssc.awaitTermination() } }
3.启动Spark Streaming程序:由于使用的是本地模式"local[2]"所以可以直接在本地运行该程序
注意:要指定并行度,如在本地运行设置setMaster("local[2]"),相当于启动两个线程,一个给receiver,一个给computer。如果是在集群中运行,必须要求集群中可用core数大于1
4.在Linux端命令行中输入单词

5.在IDEA控制台中查看结果

问题:结果每次在Linux段输入的单词次数都被正确的统计出来,但是结果不能累加!如果需要累加需要使用updateStateByKey(func)来更新状态,下面给出一个例子:
package cn.itcast.spark.streaming import cn.itcast.spark.util.LoggerLevel import org.apache.spark.{HashPartitioner, SparkConf} import org.apache.spark.streaming.{StreamingContext, Seconds} object NetworkUpdateStateWordCount { /** * String : 单词 hello * Seq[Int] :单词在当前批次出现的次数 * Option[Int] : 历史结果 */ val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => { //iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x))) iter.flatMap{case(x,y,z)=>Some(y.sum + z.getOrElse(0)).map(m=>(x, m))} } def main(args: Array[String]) { LoggerLevel.setStreamingLogLevels() val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkUpdateStateWordCount") val ssc = new StreamingContext(conf, Seconds(5)) //做checkpoint 写入共享存储中 ssc.checkpoint("c://aaa") val lines = ssc.socketTextStream("192.168.10.100", 9999) //reduceByKey 结果不累加 //val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_) //updateStateByKey结果可以累加但是需要传入一个自定义的累加函数:updateFunc val results = lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true) results.print() ssc.start() ssc.awaitTermination() } }
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} /** * Created by wangsenfeng on 2016/10/27. */ object SparkSqlTest { def main(args: Array[String]) { LoggerLevels.setStreamingLogLevels() val conf = new SparkConf().setAppName("sparksql").setMaster("local[2]") val ssc = new StreamingContext(conf,Seconds(5)) ssc.checkpoint("./") val textStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.56.151",9999) val result: DStream[(String, Int)] = textStream.flatMap(_.split(" ")).map((_,1)).reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(5),Seconds(5)) result.print() ssc.start() ssc.awaitTermination() } }
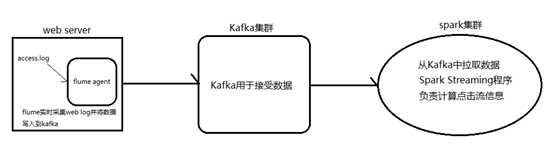
1.安装并配置zk
2.安装并配置Kafka
3.启动zk
4.启动Kafka
5.创建topic
bin/kafka-topics.sh --create --zookeeper node1.itcast.cn:2181,node2.itcast.cn:2181 \
--replication-factor 3 --partitions 3 --topic urlcount
6.编写Spark Streaming应用程序
package cn.itcast.spark.streaming package cn.itcast.spark import org.apache.spark.{HashPartitioner, SparkConf} import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object UrlCount { val updateFunc = (iterator: Iterator[(String, Seq[Int], Option[Int])]) => { iterator.flatMap{case(x,y,z)=> Some(y.sum + z.getOrElse(0)).map(n=>(x, n))} } def main(args: Array[String]) { //接收命令行中的参数 // val Array(zkQuorum, groupId, topics, numThreads, hdfs) = args val Array(zkQuorum, groupId, topics, numThreads) = Array[String]("master1ha:2181,master2:2181,master2ha:2181","g1","wangsf-test","2") //创建SparkConf并设置AppName val conf = new SparkConf().setAppName("UrlCount") //创建StreamingContext val ssc = new StreamingContext(conf, Seconds(2)) //设置检查点 ssc.checkpoint(hdfs) //设置topic信息 val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap //重Kafka中拉取数据创建DStream val lines = KafkaUtils.createStream(ssc, zkQuorum ,groupId, topicMap, StorageLevel.MEMORY_AND_DISK).map(_._2) //切分数据,截取用户点击的url val urls = lines.map(x=>(x.split(" ")(6), 1)) //统计URL点击量 val result = urls.updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true) //将结果打印到控制台 result.print() ssc.start() ssc.awaitTermination() } }
生产数据测试:
kafka-console-producer.sh --broker-list h2slave1:9092 --topic wangsf-test
标签:second option sparksql main 定义 应用程序 png res tap
原文地址:https://www.cnblogs.com/feifeicui/p/11017411.html