标签:bae 尺寸 产生 高并发 实现 设计原则 delete div lse
互联网的应用场景中,为了支持高并发的请求,服务都是执行的分布式部署,相同的任务可以在集群中不同的服务器上执行,并且现在的服务容器都是支持多线程,相同的任务也可能会被同一个容器多次执行,都要求执行结果都满足幂等性的设计原则。
分布式锁,就是为了确保在分布式的环境下,相同任务只会执行成功的执行一次,后续的执行不会对这些已经产生了变化的业务再次产生影响。
分布式锁的实现有不少的方式,如:
使用RDBMS数据库做为锁不是笔者要讨论的范畴,因为其本身的特性,不太符合在高并发下锁的应用场景,这里以Redis作为分布式锁做为介绍。
Redis本身有一些命令组支持原子性的操作,如getset、setns,这些命令可以用于分布式锁的场景中。
getSet本身是支持原子性的,在写入新值的同时会返回旧的值,用这个写入新值并获取旧值做为分布式锁的控制实现,如果返回的值不为空,那就说明前面已经有其它线程(这里的其它线程可以指当前容器中当前服务的其它线程,也指由部署在其它服务器上的应用中的线程)修改了该值,则可以认为已经有线程在对该请求正在处理,因而可以放弃后面的处理逻辑。
可以将当前系统的时间作为分布式锁key的值,后续其它线程的请求时,将其请求的时间与获取到的锁对应的key的旧值进行比较,比较是否已经超过了一定的时间控制阀值,如果超过了则可以认为(这里存在误判的可能性,因为后续逻辑的数据处理,恰好超过了这个时间比较阀值,就会导致重复执行,因而这里时间控制阀值要设置的比较合理,另外也需要合适的熔断机制用于保证)前面的交易处理失败(如服务恰好在设置了用于分布式锁的key后,立即就挂了,没有执行到后面的删除操作)导致用于分布式锁的key没有被删除掉,可以继续处理该请求的后续交易逻辑。
这个是非常轻量级的事务控制,不会对Redis产生外部事务(应用与Redis之间的交互事务),只是需要对Redis多进一次getset操作,流程图如下:
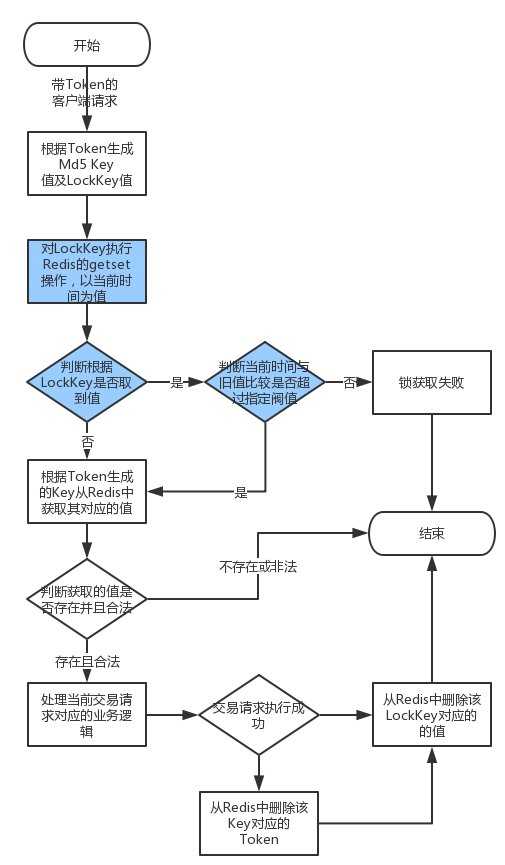
![]() ?
?
其中蓝色部分表示获取锁的逻辑。
Java代码实现如下:
setnx和getset的执行逻辑不同,getset是设置新值并返回旧值,setnx如果存在旧值时可以通过参数控制不设置值并返回0,不存在旧值时才设值并返回1。
二者处理流程上都是相同的,不同之处在于获取锁的实现,setnx的实现逻辑如下:
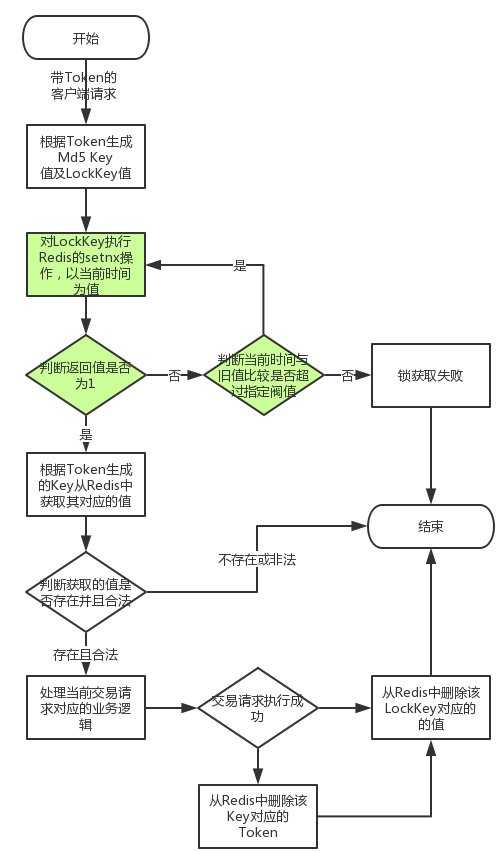
![]() ?
?
其中绿色部分为setnx获取锁的逻辑,这个和getset是不同的实现逻辑。
setnx获取锁的Java代码实现如下:
/** * 根据setnx的命令的特性,如果写入数据成功,可以用于当示锁获取成功,写入失败表示未获取到锁 * * @param lockKey * @param value * @param expire * @return true表示获取到锁,false表示未获取到锁 */ public boolean getLock(String lockKey) { long now = System.currentTimeMillis(); // Redis的GetSet返回的值必须是字符串,否则会抛异常,因而将其转换为字符串 String nowTime = String.valueOf(now); RedisConnection connection = redisTemplate.getConnectionFactory().getConnection(); JedisCommands commands = (JedisCommands) connection.getNativeConnection(); boolean con = false; do { con = false; // 返回1表示锁获取成功,返回0表示锁取失败 String result = commands.set(lockKey, nowTime, "NX", "PX", expire); if ("1".equals(result)) { return true; } else { String oldTime = redisTemplate.opsForValue().get(lockKey); // 检查锁lockKey的值是不是超过了设定的时间,如2秒钟,如果超过了则继续尝试获取锁,直到获取到锁,或者数据未超期时退出; // 循环判断可以解决死锁的问题 if (now - Long.parseLong(oldTime) >= expire) {// 数据已经过期了 con = true; } } } while (con); return false; }
标签:bae 尺寸 产生 高并发 实现 设计原则 delete div lse
原文地址:https://www.cnblogs.com/fenglibing/p/11020472.html