标签:查找 检测 map block -o round 推理 vgg 虚线
目标检测,即在一幅图里框出某个目标位置.有2个任务.
一种暴力的目标检测方法就是使用滑动窗口,从左到右,从上到下扫描图片,然后用分类器识别窗口中的目标.为了检测出不同的目标,或者同一目标但大小不同,必须使用不同大小,不同宽高比的滑动窗口.

把滑动窗口框出来的图片块resize(因为很多分类器只接受固定大小的图片输入)后,送给CNN分类器,CNN提取出4096个特征.然后使用SVM做分类,用线性回归做bounding box预测.

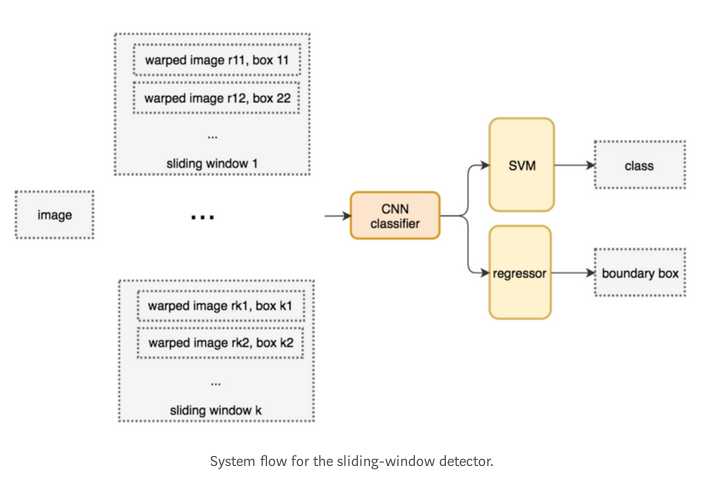
伪代码如下
for window in windows
patch = get_patch(image, window)
results = detector(patch)
提高性能的一个明显的方法就是减少window数量.
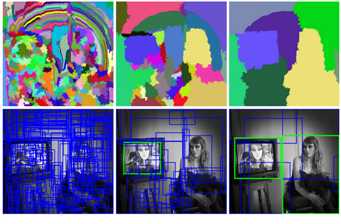
相比于暴力搜索,我们使用一种区域建议(region proposal)方法去创建roi(感兴趣区域region of intrest).在selective search(SS)中,我们从将每一个像素作为一个group开始,接下来我们计算每一个group的texture,然后合并最接近的group.为例避免某个区域吞并了其他区域,我们优先合并较小的group,不断的合并各个group直到不能再合并了.如下图:第一行图显示了region是怎么不断地增长的,第二行的蓝色框显示了在不断地合并的过程里,是怎么产生ROI的.
R-CNN采取区域建议方法创建2000个ROI.然后这些区域的图片被送到CNN,提取特征,然后送给全连接层做边界框预测和类别预测
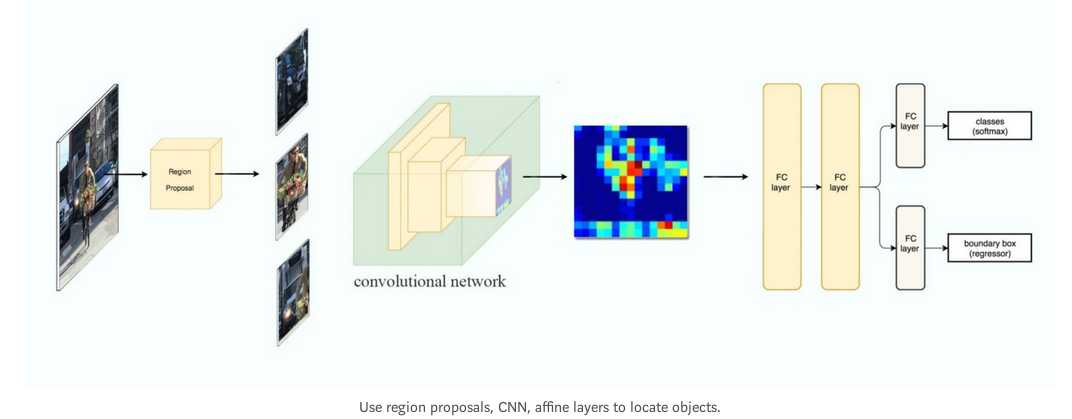
流程如下:
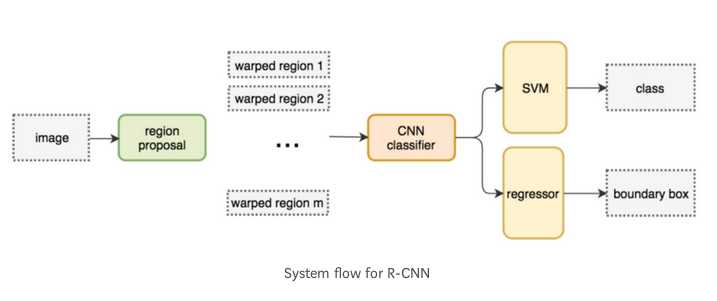
由于有了数量少质量高的ROI,R-CNN相比于暴力的滑动窗口搜索,要快的多,也准确的多.
ROIs = region_proposal(image)
for ROI in ROIs
patch = get_patch(image, ROI)
results = detector(patch)区域建议方法是需要大量算力的.为了加速ROI寻找的过程,我们往往选择一个不需要巨量算力的区域建议方法来创建ROI,再用线性回归器(使用全连接层)对边界框做微调.

R-CNN需要大量的ROI,并且这些ROI很多都是重叠的.所以R-CNN在无论是训练还是推理都很慢.如果我们有2000个建议区域,每一个都要被CNN处理一次,也就是说,对于不同的ROI,特征提取重复了2000次.
换个思路,对整幅图片做特征提取,然后在特征图的基础上做ROI的查找.通过池化层做resize,然后送给全连接层做边界框预测和分类.由于只做了一次特征提取,Fast R-CNN的性能显著提高.
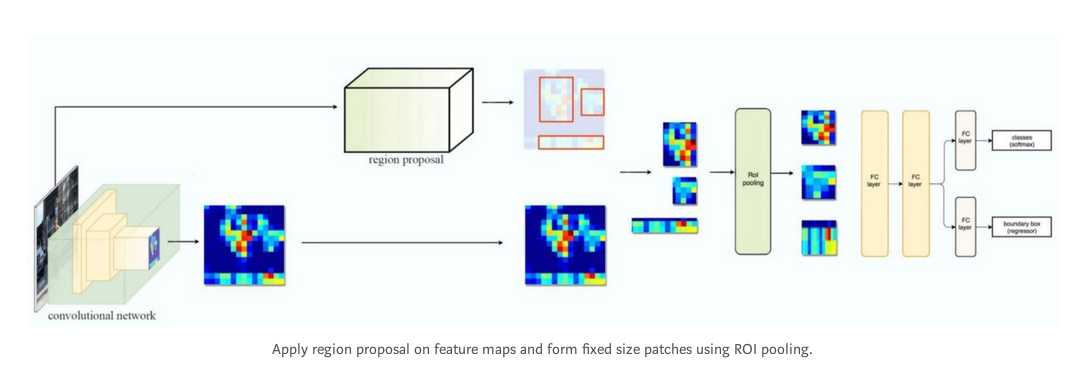
流程如下:
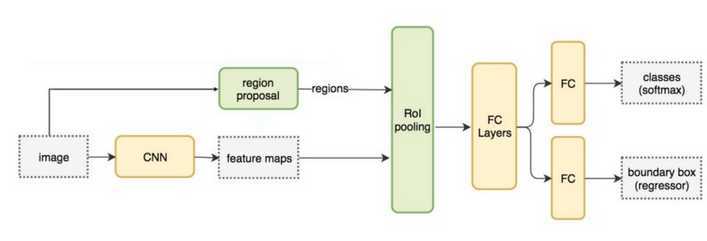
伪代码如下:
feature_maps = process(image)
ROIs = region_proposal(image)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)由于把特征提取这一步抽到了for循环外部,性能大幅提升.相比R-CNN,Fast R-CNN在训练上快了10倍,推理上快了150倍.
Fast R-CNN的一个要点是整个网络(包括特征提取,分类,边界框回归)是端到端的训练,并且采用了multi-task losses(分类loss + 边界框定位loss),提高了准确率.
由于Fast R-CNN使用全连接层,我们采用ROI池化,把不同size的ROI转换成固定size.
以8*8的特征图转换为2*2为例
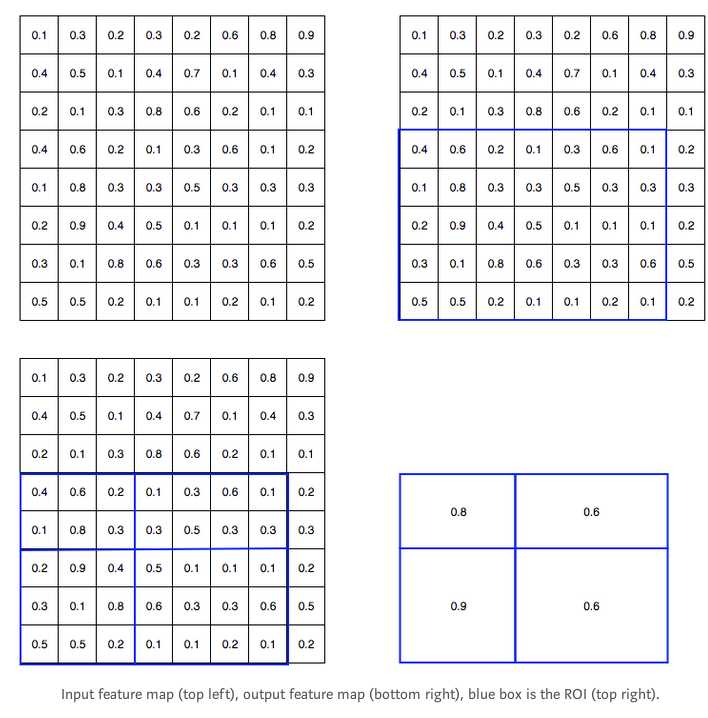
然后就可以把这些2*2的特征图送给分类器和线性回归器去做分类和边界框预测了.
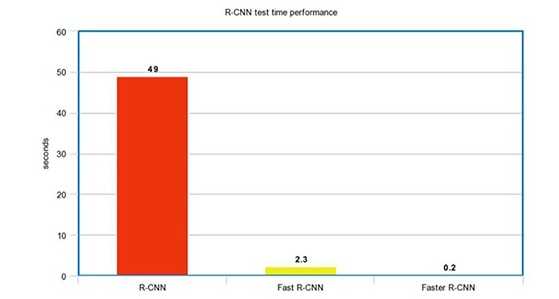
Fast R-CNN依赖于区域建议方法,比如selective search.但是,这些算法只能跑在cpu上,速度很慢.在测试中,Fast R-CNN做出一次预测要2.3秒,其中2秒都花在了生成2000个ROI.
feature_maps = process(image)
ROIs = region_proposal(image) # Expensive!
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)在流程上,Faster R-CNN与Fast R-CNN是一致的,只是将得到ROI的方式改为由一个region proposal network(RPN)得到.RPN效率要高的多,每张图生成ROI的时间仅在10ms.
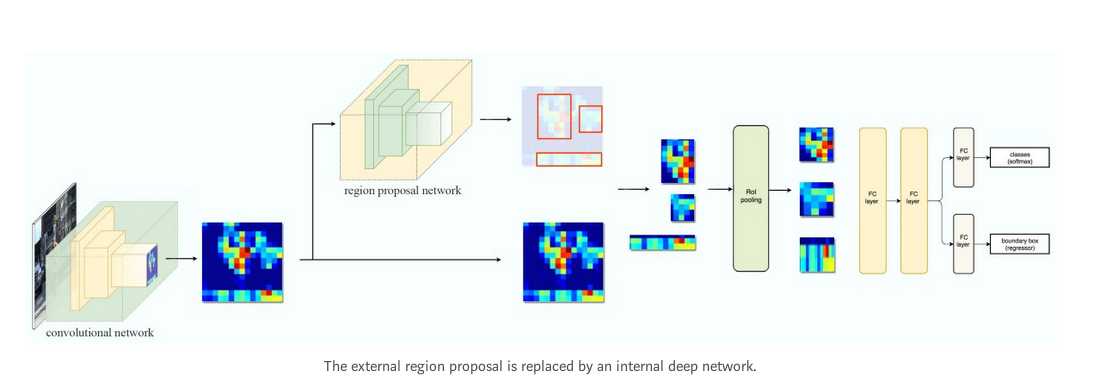
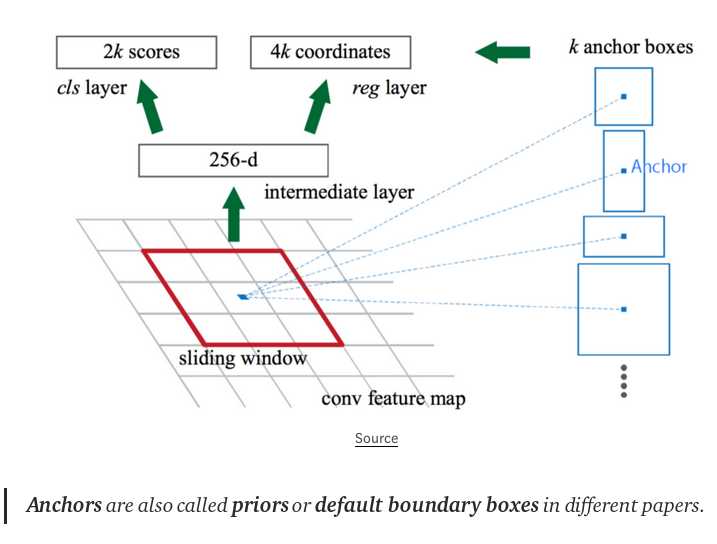
RPN接受卷积网络输出的特征图作为输入,用如下的ZF网络做区域建议.也可以用其他的网络比如VGG或者ResNet去做更全面的特征提取,代价是速度的下降.ZF网络输出256个值,送到两个全连接层,一个用于预测边界框(boudary box),一个用于预测2个objectness scores.objectness衡量bounding box是否包含一个object.我们可以用一个回归器去计算出一个single objectness score.但是为简单起见,Fast R-CNN使用一个分类器,分类器分出的类别有2种:即包含目标和不包含.
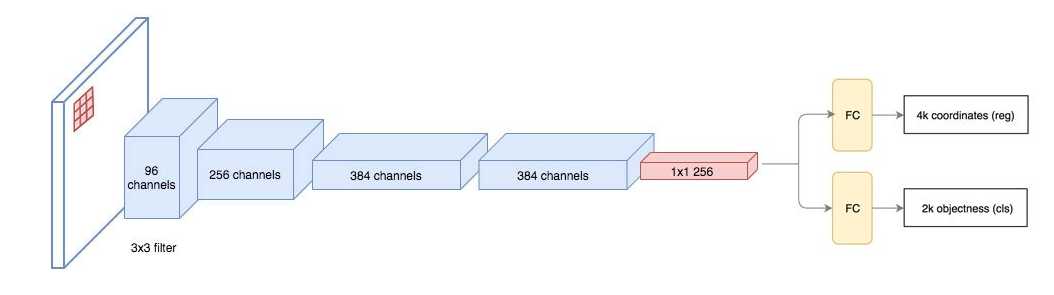
对特征图中的每一个位置,RPN做出k个猜测.所以RPN输出4*k个坐标,2*k个score.如下表示对一个8*8的特征图,用3*3的filter,最终得到8*8*3个ROI.
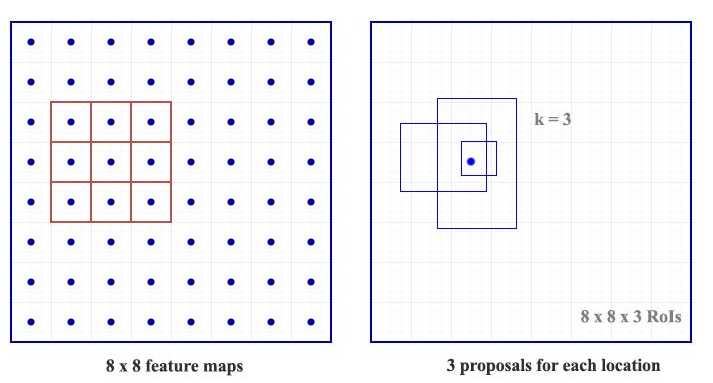
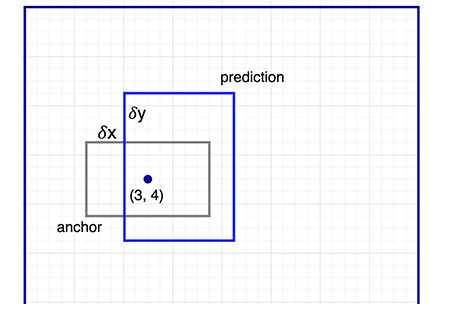
后面我们将继续微调我们的猜测.由于我们需要有一个正确的猜测,我们初始化的猜测最好有不同的shape,不同的size.所以,Faster R-CNN不是随机乱猜的边界框,它预测相对于我们称之为anchors的参考框(reference box)左上角的偏移.我们限定偏移的大小,这样我们最终预测出的bounding box依然是与anchors类似的.
为了每个位置能够得到k个预测,每个位置需要k个anchor.每一个预测都与一个特定的anchor有关.不同的位置共享同样的anchor shape.
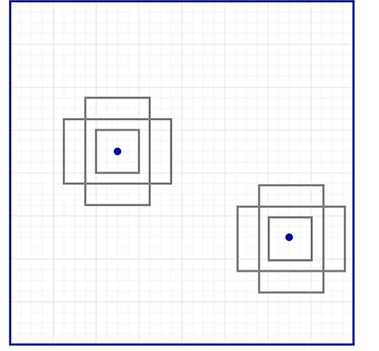
这些anchors不是瞎选的,要尽可能地覆盖到real-life objects,并且要尽量有合理的尺度和宽高比.这样可以使得每次的prediction更准确.这个策略使得训练的早期可以更容易更稳定.
Faster R-CNN uses far more anchors. It deploys 9 anchor boxes: 3 different scales at 3 different aspect ratio. Using 9 anchors per location, it generates 2 × 9 objectness scores and 4 × 9 coordinates per location.
假设一下我们只有一个检测脸部中右眼的feature map,我们可以用它来定位整张脸吗?答案是肯定的,因为右眼位于面部的左上角,所以我们可以用来定位整张脸.

如果我们有其他专门用于检测左眼、鼻子或嘴巴的特征图,我们可以将这些结果结合起来,更好地定位人脸.
在Faster R-CNN中,我们最终会将整幅图片的feature map切成相应的roi对应的feature map,再送给多个全连接层去做预测.有2000个ROI的时候,这一步的代价是很高昂的.
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
class_scores, box = detector(patch) # Expensive!
class_probabilities = softmax(class_scores)R-FCN通过减少每一个roi的处理时间提速.下面是伪代码
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
score_maps = compute_score_map(feature_maps)
for ROI in ROIs
V = region_roi_pool(score_maps, ROI)
class_scores, box = average(V) # Much simpler!
class_probabilities = softmax(class_scores)
考虑一个5*5的feature map,其中蓝色部分的feature构成了我们想要检测的object.我们将蓝色部分划分为3*3的区域.现在我们可以创建一个新的feature map,仅仅用来检测object的top left corner(TL).如下:
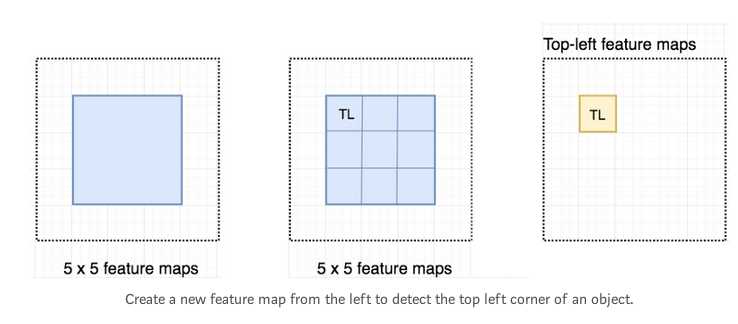
由于我们将object分成了9个部分,我们从整幅图的feature map中得到9个feature map,每一个feature map负责检测object的相应区域.这些feature map我们称之为position-sensitive score maps,因为每个map都只detect(scores)一个object的子区域.
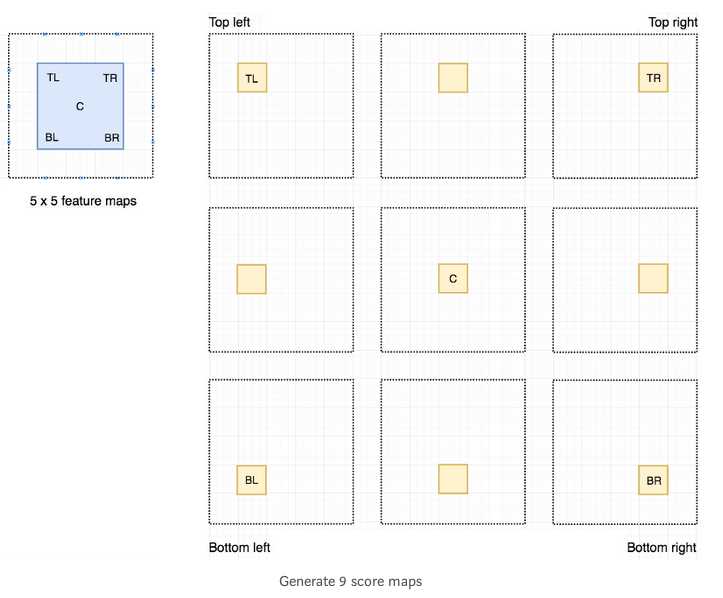
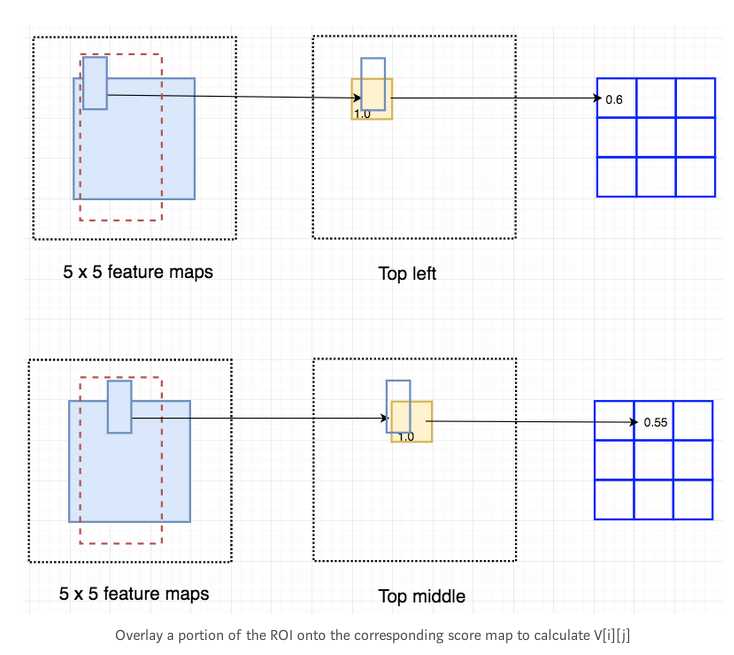
假设下图的红色虚线框是ROI.我们将其划分成3*3的区域,然后考虑每个区域包含目标的对应位置的可能性.例如,top-left ROI区域包含左眼的可能.我们把结果存储在一个3*3的vote array里.比如,vote_array[0][0]存储了一个score,表示我们是否发现了目标的top-left region.
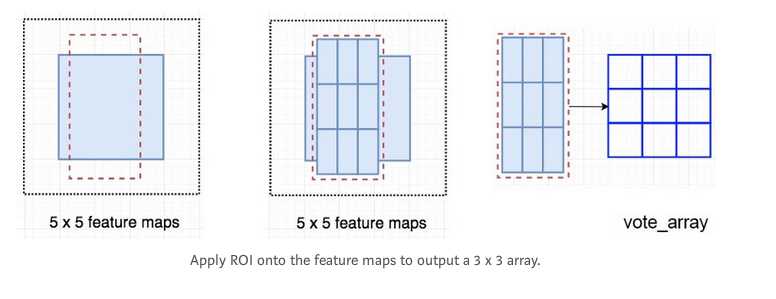
这个依据score map和ROI得到vote array的过程称之为position-sensitive ROI-pool.这个过程和前文提过的ROI pool很类似.
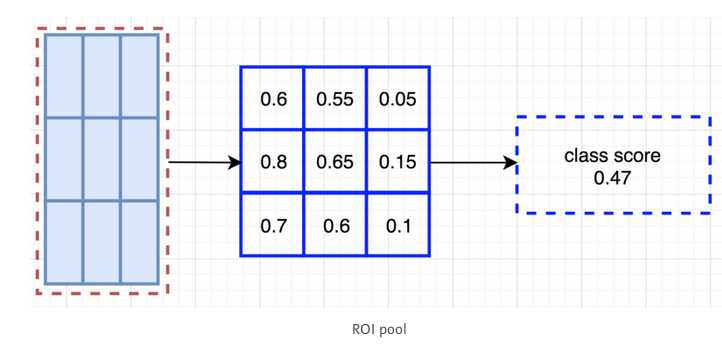
计算出所有的值以后,取平均,就得到了class score.
假设我们有C种目标待检测.我们扩展为C+1种,即包含一种class for the background(non-object).每一种目标都有自己的3*3个score map.所以一共有(C+1)*3*3个score maps.使用这些score maps我们可以为每一个类别都算出一个class score.然后用softmax可以计算出每一个类别的class probability.
整体流程如下,下图中k=3.
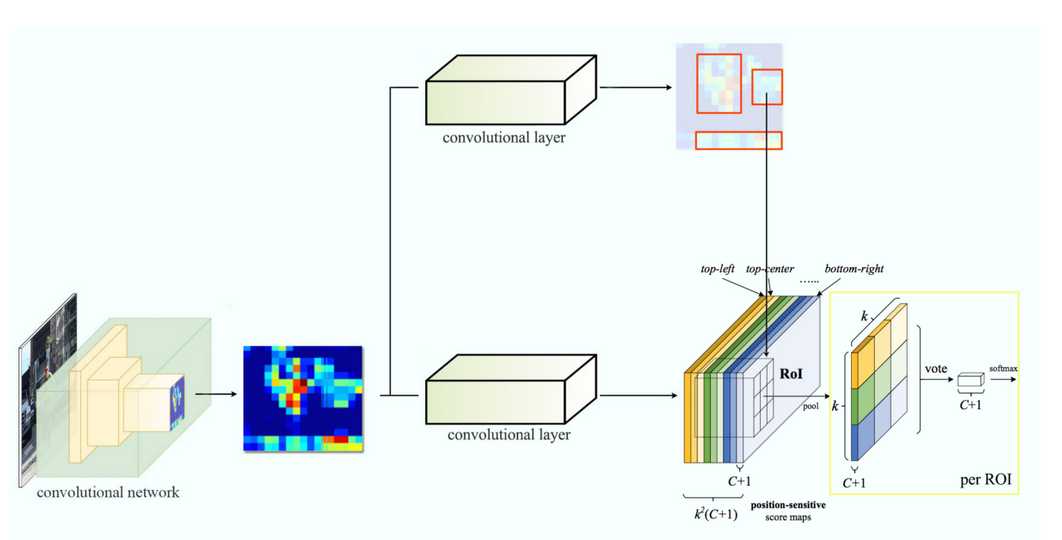
R-FCN的一个示例

原文link:https://medium.com/@jonathan_hui/what-do-we-learn-from-region-based-object-detectors-faster-r-cnn-r-fcn-fpn-7e354377a7c9
标签:查找 检测 map block -o round 推理 vgg 虚线
原文地址:https://www.cnblogs.com/sdu20112013/p/11022480.html