标签:机器学习 向量 序列 随机 冗余 初始 inf lam 模型
无约束极小值的最优化条件:

关于多元函数极小值点的必要条件:
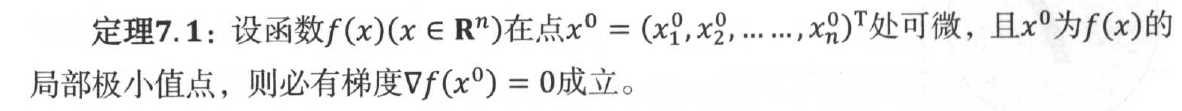
满足的点称之为f(x)的驻点或稳定点,但是反过来,满足梯度条件的点不一定是f(x)的局部极小值。因此,定理转化为求解下面的方程组问题:
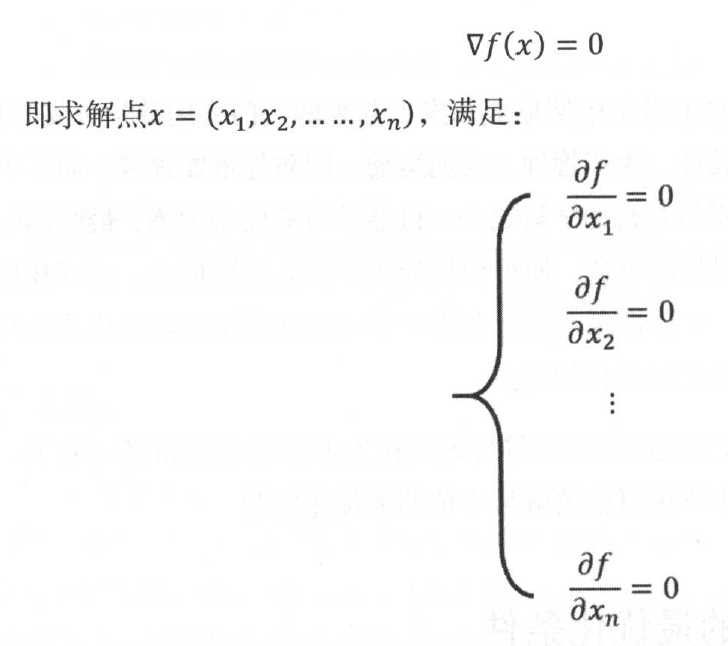
对于上面的线性方程组,利用解析法(如高斯消元法、矩阵三角分解法等)可以较方便求解,但是遗憾的是,f(x)一般是很复杂的非线性函数,求解非线性方程组并不比求解最优化问题简单,甚至比求解最优化问题更困难、更复杂。因此,在机器学习领域,求解最优化问题,一般不会通过解析法来求解上式,而是通过数值计算方法来直接求取函数极值。
迭代法是数值计算最常用的最优化方法,它的基本思想是:首先给定f(x)的一个极小值点得到初始估计x0,然后通过迭代的方式得到点序列{xt},如果这个点序列的极限x*逼近极小值点,那么成这个序列为极小化序列。这个极小化序列通过迭代公式可以写成:
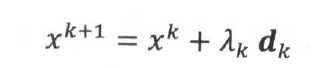
其中d是一个方向向量,λ称为步长(或学习率),当λ和d都被确定后,也就可以唯一确定点下一个点xk+1,并以此迭代,最后求得极小值点。
注意:各种迭代算法的区别就在于得到步长λ和方向d的方式不同。一个好的迭代算法应满足的两个条件:递减性和收敛性。
梯度下降:
梯度下降是神经网络最常用的优化方法之一。它的方向就是f在该点x0处函数值增长最快的方向。基于梯度的这个性质,如果把迭代的每一步沿着当前点的梯度方向的反方向进行迭代,那么就能得到一个逐步递减的极小化序列。
根据每一次迭代所使用的训练数据集范围不同,可以把梯度下降算法区分为:
1. 每一批的数据量较小,特别适合高效的矩阵运算,尤其是GPU的并行加速,因此虽然小批量梯度算法的训练数据要比随机梯度下降算法多,但效率上与随机梯度算法差别不大。
2. 与随机梯度下降算法相比,小批量梯度算法每一批考虑了更多的样本数据,每一批数据之间的整体差异更小、更平均,结果也更稳定。
3. 由于效率与随机梯度下降算法相当,因此小批量梯度策略同样适用于在线的模型更新。
一般来说,当前的梯度下降算法普遍采用第三个---小批量梯度算法策略。
梯度下降中用于确定步长和方向向量的几个不同算法的策略:
1. 传统更新策略:vanilla策略,最简单的参数更新策略,参数沿着其梯度反方向变化。lr是学习率,预先设置的固定值超参数。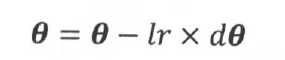
2. 动量更新策略:

3. 改进的动量更新策略:

4. 自适应梯度策略:以上方法都是对迭代方法的优化,而步长是固定的,该策略考虑学习率对着迭代次数变化而变化的自适应梯度策略。

标签:机器学习 向量 序列 随机 冗余 初始 inf lam 模型
原文地址:https://www.cnblogs.com/CynthiaWendy/p/11024396.html