标签:pool alt 简单 执行 顺序 没有 change 个数 直接
业务需求
假设你在维护一个市民系统,每个人都有一个唯一的身份证号,而且业务代码已经保证了不会写入两个重复的身份证号。如果市民系统需要按照身份证号查姓名,就会执行类似这样的SQL语句:
select name from CUser where id_card = 'xxxxxxxyyyyyyzzzzz';在不考虑身份证好字段大小的情况下,需要给id_card建立索引,是选择普通索引还是唯一索引呢?
查询过程
更新过程
change buffer 和 redo log的区别
业务需求
假设你在维护一个市民系统,每个人都有一个唯一的身份证号,而且业务代码已经保证了不会写入两个重复的身份证号。如果市民系统需要按照身份证号查姓名,就会执行类似这样的SQL语句:
select name from CUser where id_card = 'xxxxxxxyyyyyyzzzzz';在不考虑身份证好字段大小的情况下,需要给id_card建立索引,是选择普通索引还是唯一索引呢?
查询过程
更新过程
change buffer 和 redo log的区别
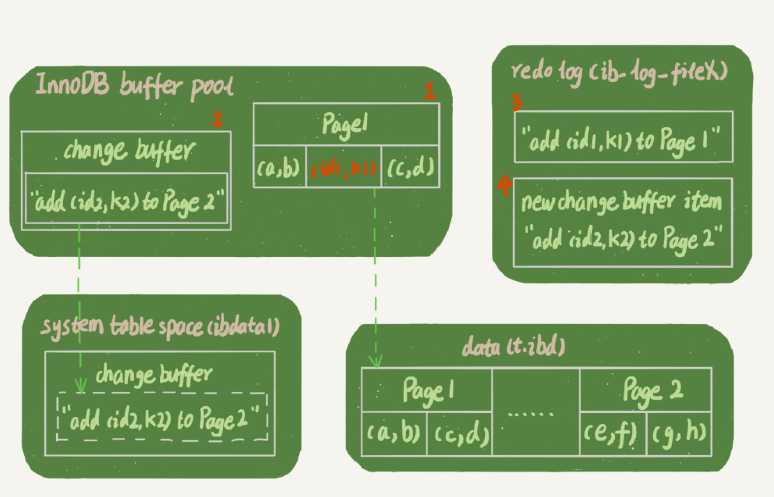
这条语句操作如下
所以,如果要简单地对比这两个机制在提升更新性能上的收益的话,redo log 主要节省的是随机写磁盘的IO消耗(转成顺序写),而change buffer主要节省的则是随机读磁盘的IO消耗。
标签:pool alt 简单 执行 顺序 没有 change 个数 直接
原文地址:https://www.cnblogs.com/jimmyhe/p/11027141.html