标签:ima 长度 方式 策略 ram cal 人人 最简 目的
关于特征聚合的方法:Aggregating Frame-level Features for Large-Scale Video Classification
这个任务的目的:aggregate frame level features for large-scale video classification.就是将视频中一帧一帧的特征做聚合来得到单个特征去做分类。比如最简单的方法可以将该类别(该人人脸)的所有帧的图像特征取平均作为该类(该人人脸)的特征。
大致有如下方法:
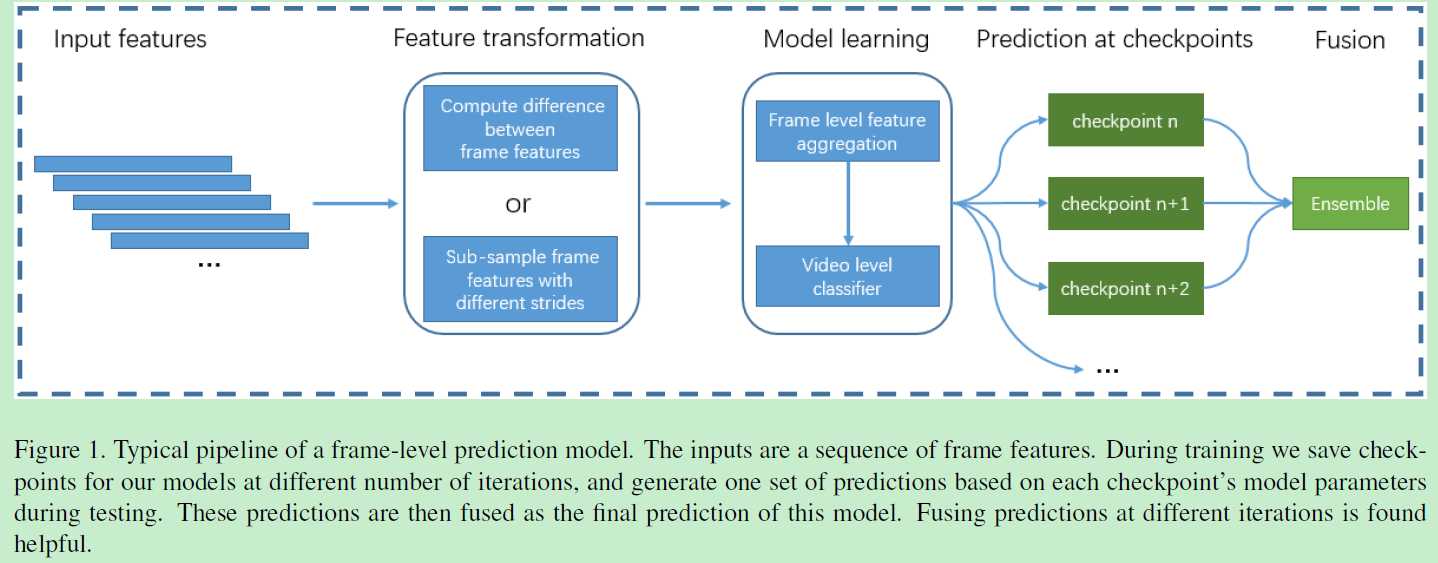
上图是general的聚合方式:在不同迭代周期分别预测特征,然后将所有这些特征聚合。
这篇是做人脸聚合的:Neural Aggregation Network for Video Face Recognition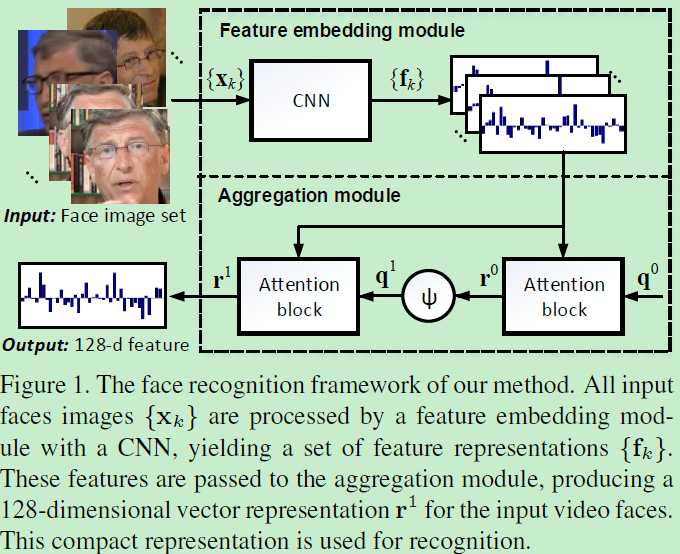
就是说不论该视频的长度有多少,我们都将每一帧的人脸特征做聚合得到代表该人脸特征的唯一128维向量。
标签:ima 长度 方式 策略 ram cal 人人 最简 目的
原文地址:https://www.cnblogs.com/king-lps/p/11039473.html