1 做了哪些项目
2 使用什么技术
3 哪个是你主导的项目,一共开发多少个接口,项目多长时间,数据库有多少个表
1 用自己擅长的语言实现非递归单链表反转 现场手写
2 Hadoop和spark的主要区别
3 Hadoop中一个大文件进行排序,如何保证整体有序?sort只会保证单个节点的数据有序
4 Hive中有哪些udf
5 Hadoop中文件put get的过程详细描述
6 Java中有哪些GC算法
7 Java中的弱引用 强引用和软引用分别在哪些场景中使用
1 用java实现非递归单链表反转
思路:
因为在对链表进行反转的时候,需要更新每一个node的“next”值,但是,在更新 next 的值前,我们需要保存 next 的值,否则我们无法继续。所以,我们需要两个指针分别指向前一个节点和后一个节点,每次做完当前节点“next”值更新后,把两个节点往下移,直到到达最后节点。
实现代码如下:
class Node { char value; Node next; } public Node reverse(Node current) { //initialization Node previousNode = null; Node nextNode = null; while (current != null) { //save the next node nextNode = current.next; //update the value of "next" current.next = previousNode; //shift the pointers previousNode = current; current = nextNode; } return previousNode; }
2 Hadoop和spark的主要区别-这个问题基本都会问到
记住3点最重要的不同之处:
3 Hadoop中一个大文件进行排序,如何保证整体有序
4 Hive中有哪些UDF
Hive中有3种UDF:
你写过哪些UDF?在哪种情况下会使用该UDF?--自己可以扩展这个问题
5 Hadoop中数据读写流程分析,即文件在put get过程中具体发生了什么
i) hadoop fs -put 操作为例:
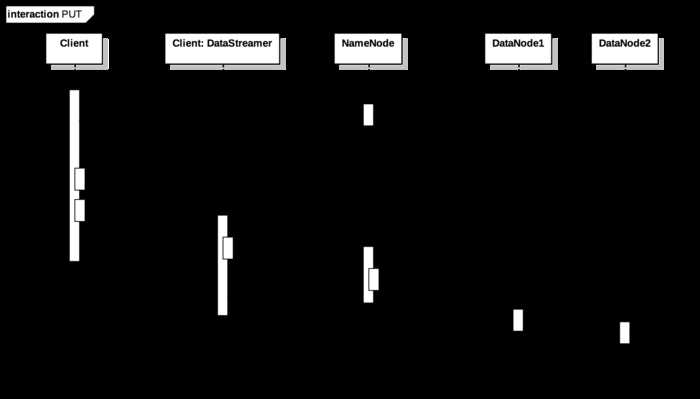
当接收到 PUT 请求时,尝试在 NameNode 中 create 一个新的 INode 节点,这个节点是根据 create 中发送过去的 src 路径构建出的目标节点,如果发现节点已存在或是节点的 parent 存在且不为 INodeDirectory 则异常中断,否则则返回包含 INode 信息的 HdfsFileStatus 对象。
使用 HdfsFileStatus 构造一个实现了 OutputStream 接口的 DFSOutputStream 类,通过 nio 接口将需要传输的数据写入 DFSOutputStream。
在 DFSOutputStream 中写入的数据被以一定的 size(一般是 64 k)封装成一个 DFSPacket,压入 DataStreamer 的传输队列中。
DataStreamer 是 Client 中负责数据传输的独立线程,当发现队列中有 DFSPacket 时,先通过 namenode.addBlock 从 NameNode 中获取可供传输的 DataNode 信息,然后同指定的 DataNode 进行数据传输。
DataNode 中有一个专门的 DataXceiverServer 负责接收数据,当有数据到来时,就进行对应的 writeBlock 写入操作,同时如果发现还有下游的 DataNode 同样需要接收数据,就通过管道再次将发来的数据转发给下游 DataNode,实现数据的备份,避免通过 Client 一次进行数据发送。
整个操作步骤中的关键步骤有 NameNode::addBlock 以及 DataNode::writeBlock, 接下来会对这两步进行详细分析。
ii) hadoop fs -get操作:
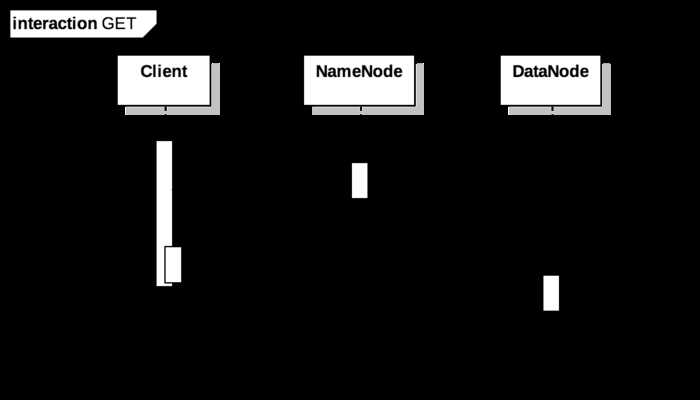
GET 操作的流程,相对于 PUT 会比较简单,先通过参数中的来源路径从 NameNode 对应 INode 中获取对应的 Block 位置,然后基于返回的 LocatedBlocks 构造出一个 DFSInputStream 对象。在 DFSInputStream 的 read 方法中,根据 LocatedBlocks 找到拥有 Block 的 DataNode 地址,通过 readBlock 从 DataNode 获取字节流。
6 Java中有哪些GC算法
现代虚拟机中的垃圾搜集算法:
分代收集(新生代采用复制算法,老年代采用标记-压缩算法)
标记 -清除算法
“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。
它的主要缺点有两个:一个是效率问题,标记和清除过程的效率都不高;另外一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
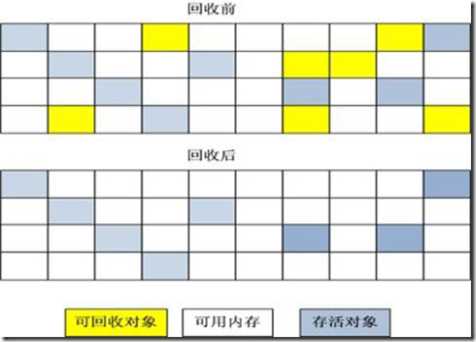
复制算法
“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这样使得每次都是对其中的一块进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,持续复制长生存期的对象则导致效率降低。
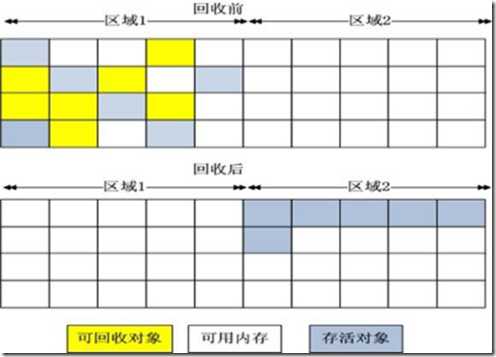
标记-压缩算法
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
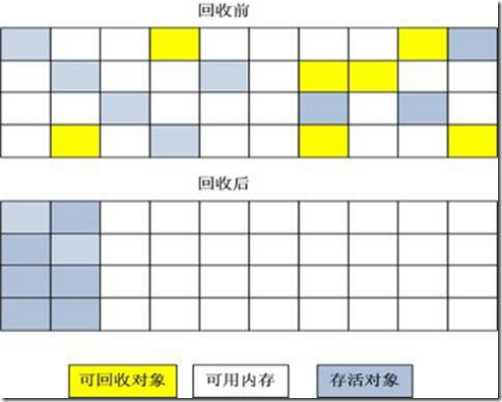
分代收集算法
GC分代的基本假设:绝大部分对象的生命周期都非常短暂,存活时间短。
“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收。
7 Java中的弱引用、强引用、软引用和虚引用是什么,他们分别在哪些场景中使用
通过表格来说明一下,如下:
|
引用类型 |
被垃圾回收时间 |
用途 |
生存时间 |
|
强引用 |
从来不会 |
对象的一般状态 |
JVM停止运行时终止 |
|
软引用 |
在内存不足时 |
对象缓存 |
内存不足时终止 |
|
弱引用 |
在垃圾回收时 |
对象缓存 |
gc运行后终止 |
|
虚引用 |
任何时候 |
跟踪对象被垃圾回收器回收的活动 |
Unknown
|
=================================================================================
原创文章,转载请务必将下面这段话置于文章开头处(保留超链接)。
本文转发自程序媛说事儿,原文链接https://www.cnblogs.com/abc8023/p/10910741.html
=================================================================================
原文地址:https://www.cnblogs.com/abc8023/p/11041921.html