标签:XML get chrome 地址 page enc src temp list
分析:
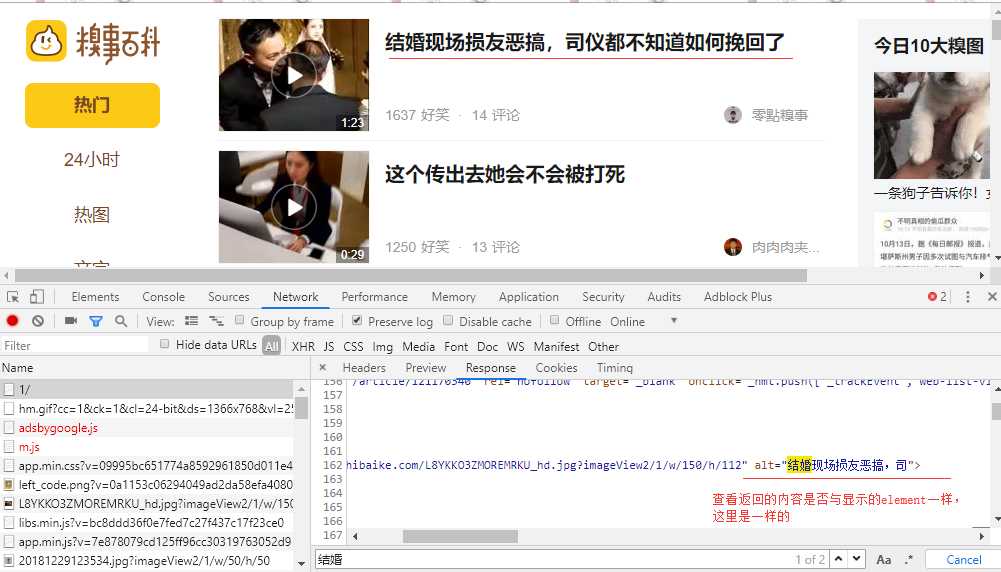
1、先查看返回的内容是否与显示的内容一样
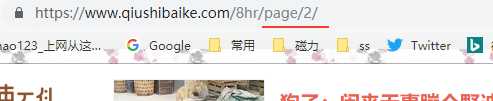
2、再看页数的变化,每次会加一,总共13页,因此可以一次性构造地址列表

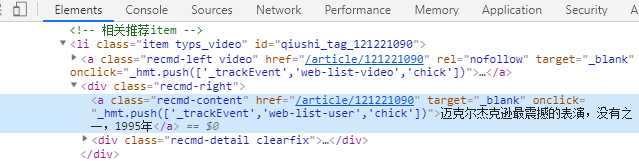
3、因此可直接结合 chrome插件 xpath helper 与 elemetns显示的内容进行定位要爬取的内容
用到的模块 requests+json+lxml+xpath
下面是代码:
import requests import json from lxml import etree class QiubaiSpider: def __init__(self): self.url_temp = "https://www.qiushibaike.com/8hr/page/{}/" self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"} def get_url_list(self): # 生成url_list return [self.url_temp.format(i) for i in range(1, 14)] def parse_url(self, url): # 发送请求 print(url) response = requests.get(url, headers=self.headers) return response.content def get_content_list(self,html_str): # 提取数据 html = etree.HTML(html_str) li_list = html.xpath("//div[@class=‘recommend-article‘]/ul/li") # 分组 content_list = [] for li in li_list: item={} item["content"] = li.xpath("./div/a/text()") # 获取内容 item[‘name‘] = li.xpath("./div/div/a/span/text()") # 获取姓名 item[‘name‘] = item[‘name‘][0] if len(item[‘name‘])>0 else None item[‘content_img‘] = li.xpath("./a/img/@src") # 获取图片 item[‘content_img‘] = ‘https:‘+item[‘content_img‘][0] if len(item[‘content_img‘])>0 else None item[‘auth_img‘] = li.xpath(".//a[@class=‘recmd-user‘]/img/@src") # 获取用户头像 item[‘auth_img‘] = ‘https:‘+item[‘auth_img‘][0] if len(item[‘auth_img‘])>0 else None item[‘recmd-num‘] = li.xpath(".//div[@class=‘recmd-num‘]/span/text()") # 获取点赞数和评论数 content_list.append(item) return content_list def save_content_list(self,content_list): # 保存数据 with open(‘qiubai‘,‘a‘,encoding=‘utf-8‘)as f: for i in content_list: f.write(json.dumps(i,ensure_ascii=False,indent=4)) f.write(‘\n‘) def run(self): # 实现主要逻辑 # 1 url_list url_list = self.get_url_list() # 2 遍历,发送请求,获取响应 for url in url_list: html_str = self.parse_url(url) # 3 提取数据 content_list = self.get_content_list(html_str) # 4 保存 self.save_content_list(content_list) if __name__ == ‘__main__‘: qiubai = QiubaiSpider() qiubai.run()
标签:XML get chrome 地址 page enc src temp list
原文地址:https://www.cnblogs.com/zq8421/p/11044366.html