标签:第一个 enc 影响 遇到 data NPU test net bat
一、问题:如何利用神经网络处理序列问题(语音、文本)?
在MNIST手写数字识别中,输入一张图片,得到一个结果,输入另一张图片,得到另一个结果,输入的样本是相互独立的,输出的结果之间也不会相互影响。也就是说,这时处理的数据是IID(独立同分布)数据,但序列类的数据却不满足IID特征,所以RNN出场了。
二、RNN的结构
看到hello,wor__!你肯定会轻而易举地预测出后两个字符为ld。
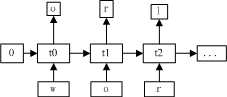
RNN结构如下:
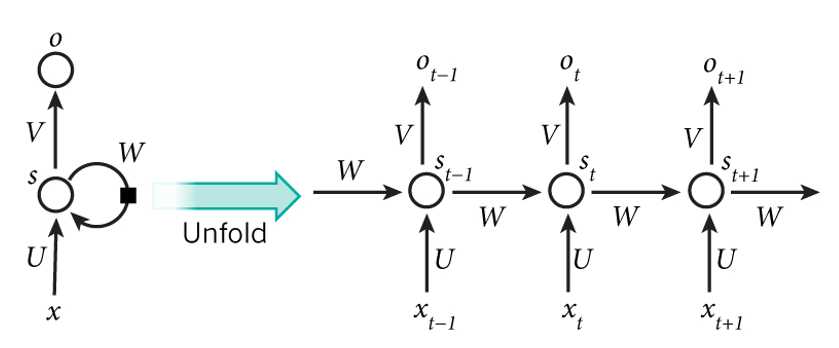
左侧:x是输入,s相当于隐藏层,o是输出。U、V、W都是权值矩阵。为什么称之为循环那?因为隐藏层的输出不光传给了下一个节点,也传给了它本身。展开如右:t代表时刻,st是时刻t时的记忆,st不仅与t时刻的输入有关,还与上一个时刻的记忆st-1有关,故st=f(Uxt+Wst-1),ot是t时刻的输出,比如是预测下个词的时候,可能是softmax输出的每个候选词的概率。不仅与当前的输入有关,还与之前的记忆有关。图中也可以发现:W、U、V没有变过,所以RNN的权值矩阵是共享的,这样就大大减少了训练的参数。
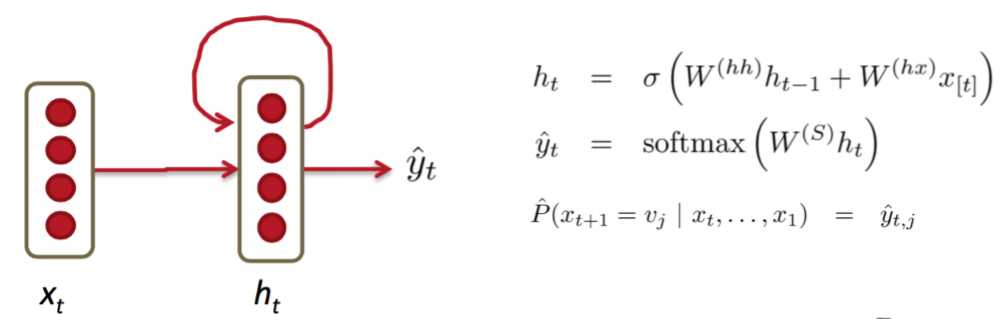
这两个图都是一个意思:不仅与当前输入有关系,还有上一时刻的记忆有关系,就和电容这种记忆性元件是一个道理。但是,RNN的记忆是有限的,它不可能把所有的都记住。所以,LSTM又出来解决这个问题了。
三、LSTM(Long Short Term Memory)网络
在看电影的时候,情节发展往往要根据之前的细节来推断,因为作者往往藏了伏笔。但RNN网络的记忆细胞随着时间的推移,有些内容它就会忘掉,记不住之前的伏笔。但是LSTM的记忆细胞会把该记住的记住,把该忽略的忽略。
上图是简单的RNN网络结构。
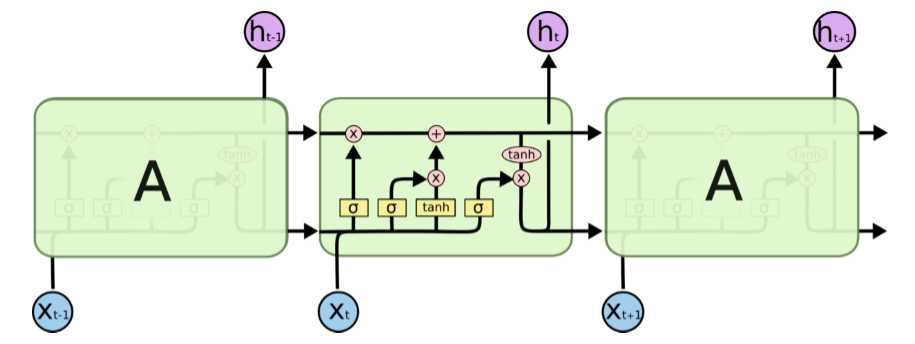
这是LSTM结构。它对状态是否参与输入以及状态的更新做了灵活的选择,也就是它可以过滤掉不想再记住的东西,还可以再往里加一些新的东西。
这种结构的核心思想是引入了一个叫“细胞状态(cell state)”的连接,这个细胞状态用来存放想要记忆的东西,同时在里面加了3个门。
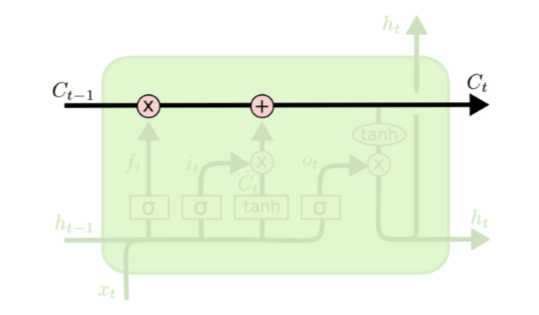
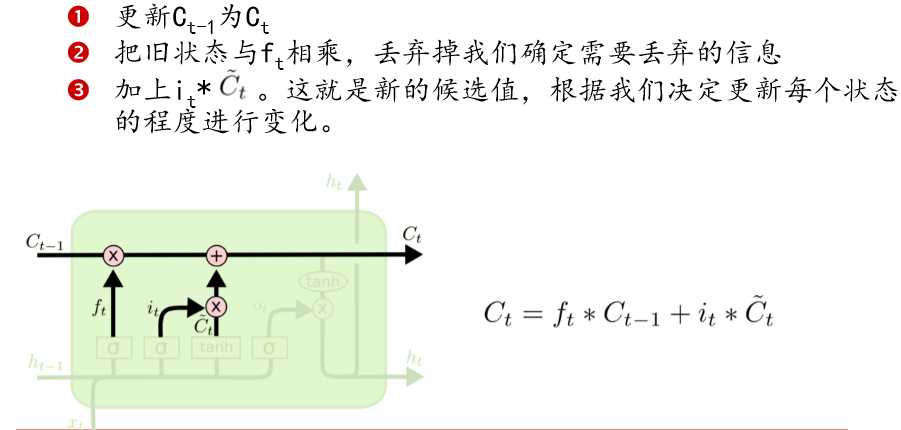
细胞状态Ct在行走的过程中,总会遇到各种操作。也许乘,也许加。这些都是它走过了一扇又一扇门实现的。
第一个要过的忘记门:把以前的状态忘记,即决定丢弃什么信息。
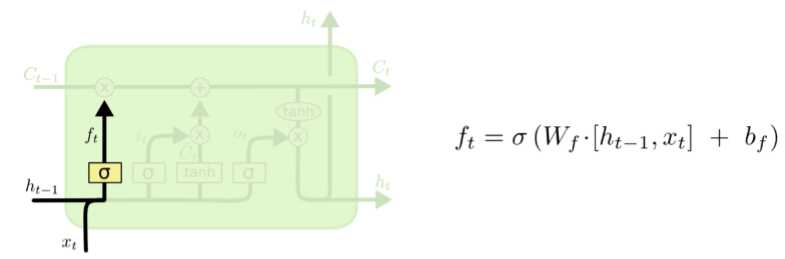
经过这一步,就选出来了那些不想要的东西,ft的值在0—1之间,0表示完全舍弃,1表示完全保留。
下一个要过输入门:决定加入什么新的状态,即更新细胞状态。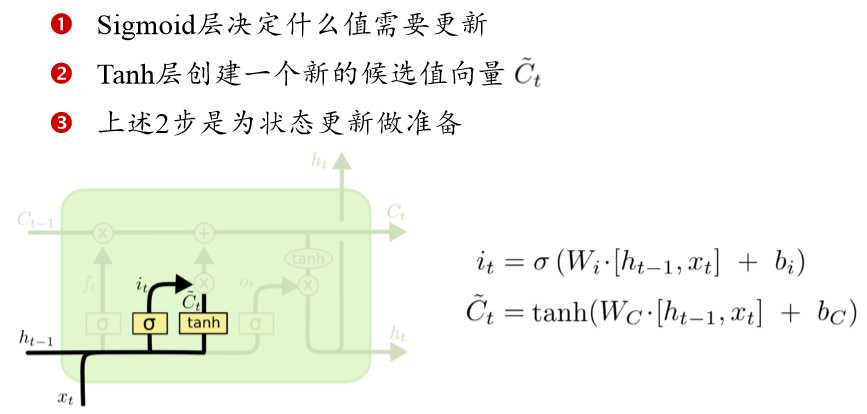
然后就是细胞状态的更新。
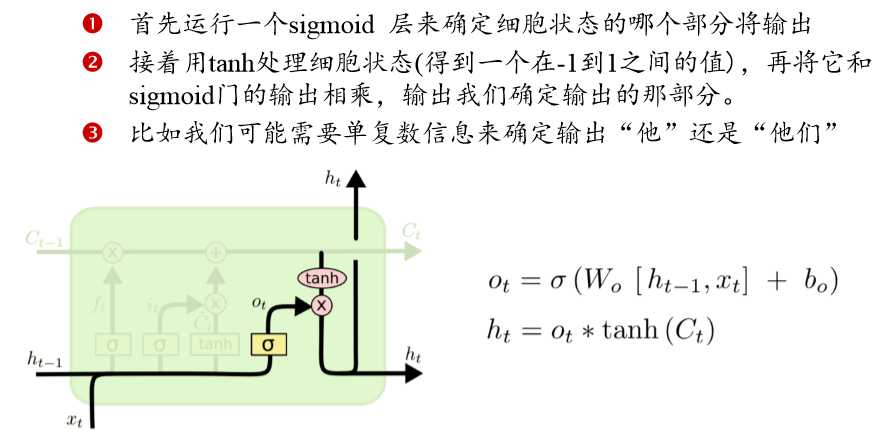
最后过输出门:把更新后的状态和输入一起输出。
四、手写数字识别参考小程序:
1 import tensorflow as tf
2 from tensorflow.examples.tutorials.mnist import input_data
3
4 #载入数据集
5 mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
6
7 # 输入图片是28*28
8 n_inputs = 28 #输入一行,一行有28个数据,输入神经元,每次输入一行
9 max_time = 28 #一共28行,每次输入一行,一共需要输入28次
10 lstm_size = 100 #隐层单元
11 n_classes = 10 # 10个分类
12 batch_size = 50 #每批次50个样本
13 n_batch = mnist.train.num_examples // batch_size #计算一共有多少个批次
14
15 #这里的none表示第一个维度可以是任意的长度
16 x = tf.placeholder(tf.float32,[None,784])
17 #正确的标签
18 y = tf.placeholder(tf.float32,[None,10])
19
20 #初始化权值
21 weights = tf.Variable(tf.truncated_normal([lstm_size, n_classes], stddev=0.1))
22 #初始化偏置值
23 biases = tf.Variable(tf.constant(0.1, shape=[n_classes]))
24
25
26 #定义RNN网络
27 def RNN(X,weights,biases):
28 # inputs=[batch_size, max_time, n_inputs]
29 inputs = tf.reshape(X,[-1,max_time,n_inputs]) #X由50*784转化成50*28*28
30 #定义LSTM基本CELL
31 lstm_cell = tf.contrib.rnn.core_rnn_cell.BasicLSTMCell(lstm_size)
32 # final_state[0]是cell state
33 # final_state[1]是hidden_state
34 outputs,final_state = tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32)
35 results = tf.nn.softmax(tf.matmul(final_state[1],weights) + biases)
36 return results
37
38
39 #计算RNN的返回结果
40 prediction= RNN(x, weights, biases)
41 #损失函数
42 cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y))
43 #使用AdamOptimizer进行优化
44 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
45 #结果存放在一个布尔型列表中
46 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一维张量中最大的值所在的位置
47 #求准确率
48 accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#把correct_prediction变为float32类型
49 #初始化
50 init = tf.global_variables_initializer()
51
52 with tf.Session() as sess:
53 sess.run(init)
54 for epoch in range(6):
55 for batch in range(n_batch):
56 batch_xs,batch_ys = mnist.train.next_batch(batch_size)
57 sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
58
59 acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
60 print ("Iter " + str(epoch) + ", Testing Accuracy= " + str(acc))
1 Extracting MNIST_data/train-images-idx3-ubyte.gz
2 Extracting MNIST_data/train-labels-idx1-ubyte.gz
3 Extracting MNIST_data/t10k-images-idx3-ubyte.gz
4 Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
5 Iter 0, Testing Accuracy= 0.7221
6 Iter 1, Testing Accuracy= 0.8016
7 Iter 2, Testing Accuracy= 0.8763
8 Iter 3, Testing Accuracy= 0.9103
9 Iter 4, Testing Accuracy= 0.9223
10 Iter 5, Testing Accuracy= 0.9311
关于dynamic_rnn定义中的参数:
返回值:一个是结果,一个是cell状态,结果是以[batch_size,max_time,...]形式的张量。
结论上来说,如果cell为LSTM,那 state是个tuple,分别代表ht和ct,其中ht与outputs中的对应的最后一个时刻的输出相等,假设state形状为[ 2,batch_size, cell.output_size ],outputs形状为 [ batch_size, max_time, cell.output_size ],那么state[ 1, batch_size, : ] == outputs[ batch_size, -1, : ]。【参考:https://blog.csdn.net/u010960155/article/details/81707498】
2019-06-18 21:12:44
标签:第一个 enc 影响 遇到 data NPU test net bat
原文地址:https://www.cnblogs.com/direwolf22/p/11008465.html