标签:表头 数据线 enc www 常用 正则 logs str ade
支持文件存取操作,支持数据库
支持增删改查,切片,高阶函数,分组聚合等单标操作,和dict,list的互相转换
支持多表拼接合并操作
支持简单的统计分析操作
import numpy as np
import pandas as pd
?
series
# 排成列
?
DataFrame
#pd.dataframe(内部,列,行)
?
行 行 行 行
列 内部 内部 内部 内部
列 内部 内部 内部 内部
?
Dataframe属性
dtype 查看数据类型
index 查看行序列或者索引
columns 查看各列的标签
values 查看数据框内的数据,不包含表头索引的数据
describe 查看数据每一列的级值,平均值,中位数,只可用于数据线数据
transpose 转职 也可用T来操作
sort_index排序,可按行或者列index排序输出
sort_values按数据值来排序
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
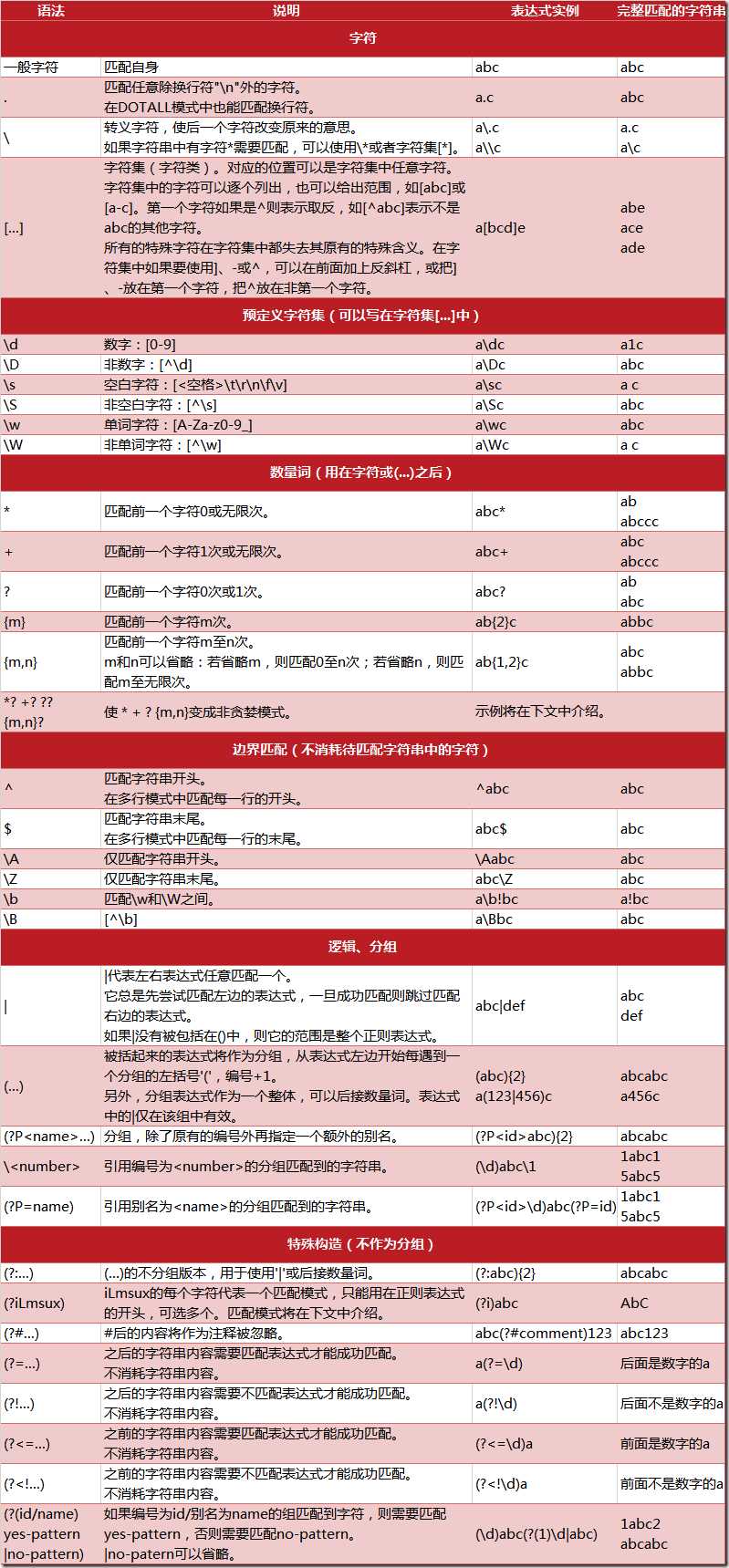
正则表达式:大致匹配过程,一次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功,一旦有匹配不成功的字符则匹配失败

震泽表达式通常用于在文本中查找匹配的字符串,python中数量词默认是贪婪地。总是匹配竟可能多的字符,非贪婪的相反,总是尝试匹配竟可能少的字符,如果正则表达式ab用于查找abbbbc,则会得到abbbb,而使用非贪婪ab?。则会找到a
字符串开始位置与匹配规则符合就匹配,否则不匹配
匹配字符串开头。在多行模式中匹配每一行的开头(Python3+已经失效,配合compile使用)
^元字符如果写到[]字符集里就是反取
[^a-z]反取
匹配出除字母外的字符,^元字符如果写到字符集里就是反取
字符串结束位置与匹配规则符合就匹配,否则不匹配
匹配字符串末尾,在多行模式中匹配每一行的末尾
需要字符串里完全符合,匹配规则,就匹配,(规则里的*元字符)前面的一个字符可以是0个或多个原本字符
匹配前一个字符0或多次,贪婪匹配前导字符有多少个就匹配多少个很贪婪
如果规则里只有一个分组,尽量避免用*否则会有可能匹配出空字符串
需要字符串里完全符合,匹配规则,就匹配,(规则里的+元字符)前面的一个字符可以是1个或多个原本字符
匹配前一个字符1次或无限次,贪婪匹配前导字符有多少个就匹配多少个很贪婪
需要字符串里完全符合,匹配规则,就匹配,(规则里的?元字符)前面的一个字符可以是0个或1个原本字符
匹配一个字符0次或1次
还有一个功能是可以防止贪婪匹配,详情见防贪婪匹配
需要字符串里完全符合,匹配规则,就匹配,(规则里的 {} 元字符)前面的一个字符,是自定义字符数,位数的原本字符
{m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次
{0,}匹配前一个字符0或多次,等同于*元字符 {+,}匹配前一个字符1次或无限次,等同于+元字符 {0,1}匹配前一个字符0次或1次,等同于?元字符
需要字符串里完全符合,匹配规则,就匹配,(规则里的 [] 元字符)对应位置是[]里的任意一个字符就匹配
字符集。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。abc表示取反,即非abc。 所有特殊字符在字符集中都失去其原有的特殊含义。用\反斜杠转义恢复特殊字符的特殊含义。
非,反取,匹配出除[^]里面的字符,^元字符如果写到字符集里就是反取
预定义字符是在字符集和组里都是有用的
也就是分组匹配,()里面的为一个组也可以理解成一个整体
如果()后面跟的是特殊元字符如 (adc)* 那么*控制的前导字符就是()里的整体内容,不再是前导一个字符
|或,或就是前后其中一个符合就匹配
一种是直接在函数里书写规则,推荐使用
import re
a = re.findall("匹配规则", "这个字符串是否有匹配规则的字符")
print(a)
[‘匹配规则‘]
另一种是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
import re
?
# 将正则表达式编译成Pattern对象
pattern = re.compile(r‘hello‘)
?
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match(‘hello world!‘)
?
if match:
# 使用Match获得分组信息
print(match.group())
hello
5|2**re.compile(strPattern[, flag])函数(了解)**
r原生字符:让在python里有特殊意义的字符如\b,转换成原生字符(就是去除它在python的特殊意义),不然会给正则表达式有冲突,为了避免这种冲突可以在规则前加原始字符r
正则表达式,返回类型为表达式对象的,如:<_sre.SRE_Match object; span=(6, 7), match=‘a‘>,返回对象时,需要用正则方法取字符串,方法有:
group() # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来,有参取匹配到的第几个如2
groups() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
groupdict() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
匹配到的字符串里出现空字符:注意:正则匹配到空字符的情况,如果规则里只有一个组,而组后面是就表示组里的内容可以是0个或者多过,这样组里就有了两个意思,一个意思是匹配组里的内容,二个意思是匹配组里0内容(即是空白)所以尽量避免用否则会有可能匹配出空字符串
()分组:注意:分组的意义,就是在匹配成功的字符串中,再提取()里的内容,也就是组里面的字符串
标签:表头 数据线 enc www 常用 正则 logs str ade
原文地址:https://www.cnblogs.com/zrx19960128/p/11060947.html