标签:dashboard 复数 操作方法 描述 lin 扩展 mon 响应 resolve
监控是整个产品周期中最重要的一环,及时预警减少故障影响免扩大,而且能根据历史数据追溯问题。
对系统不间断实时监控
实时反馈系统当前状态
保证业务持续性运行
|
监控方案 |
告警 |
特点 |
适用 |
|
Zabbix |
Y |
大量定制工作 |
大部分的互联网公司 |
|
open-falcon |
Y |
功能模块分解比较细,显得更复杂 |
系统和应用监控 |
|
Prometheus+Grafana |
Y |
扩展性好 |
容器,应用,主机全方面监控 |
市场上主流的开源监控系统基本都是这个流程:
l 数据采集:对监控数据采集
l 数据存储:将监控数据持久化存储,用于历时查询
l 数据分析:数据按需处理,例如阈值对比、聚合
l 数据展示:Web页面展示
l 监控告警:电话,邮件,微信,短信

要监控什么
|
硬件监控 |
1)通过远程控制卡:Dell的IDRAC 2)IPMI(硬件管理接口)监控物理设备。 3)网络设备:路由器、交换机 温度,硬件故障等。 |
|
系统监控 |
CPU,内存,硬盘利用率,硬件I/O,网卡流量,TCP状态,进程数 |
|
应用监控 |
Nginx、Tomcat、PHP、MySQL、Redis等,业务涉及的服务都要监控起来 |
|
日志监控 |
系统日志、服务日志、访问日志、错误日志,这个现成的开源的ELK解决方案,会在下一章讲解 |
|
安全监控 |
1)可以利用Nginx+Lua实现WAF功能,并存储到ES,通过Kibana可视化展示不同的攻击类型。 2)用户登录数,passwd文件变化,其他关键文件改动 |
|
API监控 |
收集API接口操作方法(GET、POST等)请求,分析负载、可用性、正确性、响应时间 |
|
业务监控 |
例如电商网站,每分钟产生多少订单、注册多少用户、多少活跃用户、推广活动效果(产生多少用户、多少利润) |
|
流量分析 |
根据流量获取用户相关信息,例如用户地理位置、某页面访问状况、页面停留时间等。监控各地区访问业务网络情况,优化用户体验和提升收益 |
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。
https://prometheus.io
https://github.com/prometheus
作为新一代的监控框架,Prometheus 具有以下特点:
Prometheus适用于以机器为中心的监控以及高度动态面向服务架构的监控。
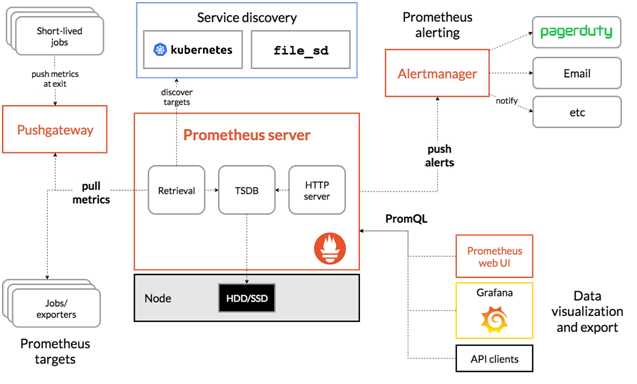
Prometheus将所有数据存储为时间序列;具有相同度量名称以及标签属于同一个指标。
每个时间序列都由度量标准名称和一组键值对(也成为标签)唯一标识。
时间序列格式:
<metric name>{<label name>=<label value>, ...}
示例:api_http_requests_total{method="POST", handler="/messages"}
指标类型
指标和实例
实例:可以抓取的目标称为实例(Instances)
作业:具有相同目标的实例集合称为作业(Job)
scrape_configs: - job_name: ‘prometheus‘ static_configs: - targets: [‘localhost:9090‘] - job_name: ‘node‘ static_configs: - targets: [‘192.168.1.10:9090‘]
下载最新版本的Prometheus,然后解压缩并运行它:
https://prometheus.io/download/
https://prometheus.io/docs/prometheus/latest/getting_started/
tar xvfz prometheus-*.tar.gz cd prometheus-* mv prometheus-* /usr/local/prometheus
系统服务
[Unit] Description=https://prometheus.io [Service] Restart=on-failure ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml [Install] WantedBy=multi-user.target
常用命令
启动prometheus ./prometheus --config.file=prometheus.yml 检测配置文件 ./promtool check config prometheus.yml 重新加载配置文件 kill -hup PID
https://prometheus.io/docs/prometheus/latest/installation/
prometheus.yml通过运行以下命令将您从主机绑定: docker run -p 9090:9090 -v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus 或者为配置使用额外的卷: docker run -p 9090:9090 -v /prometheus-data prom/prometheus --config.file=/prometheus-data/prometheus.yml
访问Web
http://localhost:9090访问自己的状态页面
可以通过访问localhost:9090验证Prometheus自身的指标:localhost:9090/metrics
Prometheus从目标机上通过http方式拉取采样点数据, 它也可以拉取自身服务数据并监控自身的健康状况
当然Prometheus服务拉取自身服务采样数据,并没有多大的用处,但是它是一个好的DEMO。保存下面的Prometheus配置,并命名为:prometheus.yml:
global: scrape_interval: 15s # 默认情况下,每15s拉取一次目标采样点数据。 # 我们可以附加一些指定标签到采样点度量标签列表中, 用于和第三方系统进行通信, 包括:federation, remote storage, Alertmanager external_labels: monitor: ‘codelab-monitor‘ # 下面就是拉取自身服务采样点数据配置 scrape_configs: # job名称会增加到拉取到的所有采样点上,同时还有一个instance目标服务的host:port标签也会增加到采样点上 - job_name: ‘prometheus‘ # 覆盖global的采样点,拉取时间间隔5s scrape_interval: 5s static_configs: - targets: [‘localhost:9090‘]
global:全局配置
alerting:告警配置
rule_files:告警规则
scrape_configs:配置数据源,称为target,每个target用job_name命名。又分为静态配置和服务发现
global: # 默认抓取周期,可用单位ms、smhdwy #设置每15s采集数据一次,默认1分钟 [ scrape_interval: <duration> | default = 1m ] # 默认抓取超时 [ scrape_timeout: <duration> | default = 10s ] # 估算规则的默认周期# 每15秒计算一次规则。默认1分钟 [ evaluation_interval: <duration> | default = 1m ] # 和外部系统(例如AlertManager)通信时为时间序列或者警情(Alert)强制添加的标签列表 external_labels: [ <labelname>: <labelvalue> ... ] # 规则文件列表 rule_files: [ - <filepath_glob> ... ] # 抓取配置列表 scrape_configs: [ - <scrape_config> ... ] # Alertmanager相关配置 alerting: alert_relabel_configs: [ - <relabel_config> ... ] alertmanagers: [ - <alertmanager_config> ... ] # 远程读写特性相关的配置 remote_write: [ - <remote_write> ... ] remote_read: [ - <remote_read> ... ]
根据配置的任务(job)以http/s周期性的收刮(scrape/pull)
指定目标(target)上的指标(metric)。目标(target)
可以以静态方式或者自动发现方式指定。Prometheus将收刮(scrape)的指标(metric)保存在本地或者远程存储上。
使用scrape_configs定义采集目标
配置一系列的目标,以及如何抓取它们的参数。一般情况下,每个scrape_config对应单个Job。
目标可以在scrape_config中静态的配置,也可以使用某种服务发现机制动态发现。
# 任务名称,自动作为抓取到的指标的一个标签 job_name: <job_name> # 抓取周期 [ scrape_interval: <duration> | default = <global_config.scrape_interval> ] # 每次抓取的超时 [ scrape_timeout: <duration> | default = <global_config.scrape_timeout> ] # 从目标抓取指标的URL路径 [ metrics_path: <path> | default = /metrics ] # 当添加标签发现指标已经有同名标签时,是否保留原有标签不覆盖 [ honor_labels: <boolean> | default = false ] # 抓取协议 [ scheme: <scheme> | default = http ] # HTTP请求参数 params: [ <string>: [<string>, ...] ] # 身份验证信息 basic_auth: [ username: <string> ] [ password: <secret> ] [ password_file: <string> ] # Authorization请求头取值 [ bearer_token: <secret> ] # 从文件读取Authorization请求头 [ bearer_token_file: /path/to/bearer/token/file ] # TLS配置 tls_config: [ <tls_config> ] # 代理配置 [ proxy_url: <string> ] # DNS服务发现配置 dns_sd_configs: [ - <dns_sd_config> ... ] # 文件服务发现配置 file_sd_configs: [ - <file_sd_config> ... ] # K8S服务发现配置 kubernetes_sd_configs: [ - <kubernetes_sd_config> ... ] # 此Job的静态配置的目标列表 static_configs: [ - <static_config> ... ] # 目标重打标签配置 relabel_configs: [ - <relabel_config> ... ] # 指标重打标签配置 metric_relabel_configs: [ - <relabel_config> ... ] # 每次抓取允许的最大样本数量,如果在指标重打标签后,样本数量仍然超过限制,则整个抓取认为失败 # 0表示不限制 [ sample_limit: <int> | default = 0
relabel_configsrelabel_configs :允许在采集之前对任何目标及其标签进行修改
重新标签的意义?
action:重新标签动作
支持服务发现的来源:
Prometheus也提供了服务发现功能,可以从consul,dns,kubernetes,file等等多种来源发现新的目标。其中最简单的是从文件发现服务。
https://github.com/prometheus/prometheus/tree/master/discovery
服务发现支持: endpoints,ingress,kubernetes,node,pod,service
node_exporter:用于*NIX系统监控,使用Go语言编写的收集器。
使用文档:https://prometheus.io/docs/guides/node-exporter/
GitHub:https://github.com/prometheus/node_exporter
exporter列表:https://prometheus.io/docs/instrumenting/exporters/
收集到 node_exporter 的数据后,我们可以使用 PromQL 进行一些业务查询和监控,下面是一些比较常见的查询。
注意:以下查询均以单个节点作为例子,如果大家想查看所有节点,将 instance="xxx" 去掉即可。
CPU使用率: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) 内存使用率: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 磁盘使用率: 100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"} * 100)
使用systemd收集器:
--collector.systemd.unit-whitelist=".+" 从systemd中循环正则匹配单元
--collector.systemd.unit-whitelist="(docker|sshd|nginx).service"白名单,收集目标
/usr/bin/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|sshd|nginx).service
node_systemd_unit_state{name=“docker.service”} 只查询docker服务
node_systemd_unit_state{name=“docker.service”,state=“active”} 返回活动状态,值是1
node_systemd_unit_state{name=“docker.service”} == 1当前服务状态
Grafana是一个开源的度量分析和可视化系统。
https://grafana.com/grafana/download
Grafana支持查询普罗米修斯。自Grafana 2.5.0(2015-10-28)以来,包含了Prometheus的Grafana数据源。
cAdvisor(Container Advisor)用于收集正在运行的容器资源使用和性能信息。
https://github.com/google/cadvisor
https://grafana.com/dashboards/193
运行单个cAdvisor来监控整个Docker主机
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:ro --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor google/cadvisor:latest
使用Prometheus监控cAdvisor
cAdvisor将容器统计信息公开为Prometheus指标。默认情况下,这些指标在/metrics HTTP端点下提供。可以通过设置-prometheus_endpoint命令行标志来自定义此端点。
要使用Prometheus监控cAdvisor,只需在Prometheus中配置一个或多个作业,这些作业会在该指标端点处刮取相关的cAdvisor流程。
mysql_exporter:用于收集MySQL性能信息。
https://github.com/prometheus/mysqld_exporter
https://grafana.com/dashboards/7362
登录mysql为exporter创建账号: mysql>CREATE USER ‘exporter‘@‘localhost‘ IDENTIFIED BY ‘XXXXXXXX‘ WITH MAX_USER_CONNECTIONS 3; mysql>GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO ‘exporter‘@‘localhost‘; # cat .my.cnf [client] user=exporter password=exporter123 # ./mysqld_exporter --config.my-cnf=.my.cnf - job_name: mysql static_configs: - targets: - 192.168.31.66:9104
使用prometheus进行告警分为两部分:Prometheus Server中的告警规则会向Alertmanager发送。然后,Alertmanager管理这些告警,包括进行重复数据删除,分组和路由,以及告警的静默和抑制。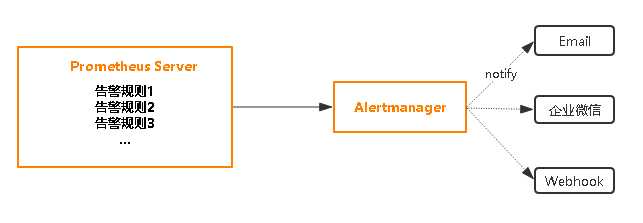
在Prometheus平台中,警报由独立的组件Alertmanager处理。通常情况下,我们首先告诉Prometheus Alertmanager所在的位置,然后在Prometheus配置中创建警报规则,最后配置Alertmanager来处理警报并发送给接收者(邮件,webhook、slack等)。
地址1:https://prometheus.io/download/
地址2:https://github.com/prometheus/alertmanager/releases
设置告警和通知的主要步骤如下:
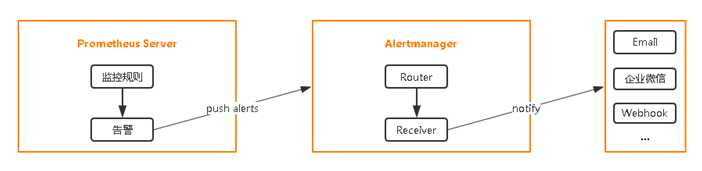
配置Prometheus与Alertmanager通信
# vi prometheus.yml alerting: alertmanagers: - static_configs: - targets: - 127.0.0.1:9093
https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
# vi prometheus.yml rule_files: - "rules/*.yml" # vi rules/node.yml groups: - name: example# 报警规则组名称 rules: # 任何实例5分钟内无法访问发出告警 - alert: InstanceDown expr: up == 0 for: 5m#持续时间 , 表示持续一分钟获取不到信息,则触发报警 labels: severity: page# 自定义标签 annotations: summary: "Instance {{ $labels.instance }} down"# 自定义摘要 description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."# 自定义具体描述
一旦这些警报存储在Alertmanager,它们可能处于以下任何状态:
这样目的是多次判断失败才发告警,减少邮件。
route属性用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
route: receiver: ‘default-receiver‘ group_wait: 30s group_interval: 5m repeat_interval: 4h group_by: [cluster, alertname] # 所有不匹配以下子路由的告警都将保留在根节点,并发送到“default-receiver” routes: # 所有service=mysql或者service=cassandra的告警分配到数据库接收端 - receiver: ‘database-pager‘ group_wait: 10s match_re: service: mysql|cassandra # 所有带有team=frontend标签的告警都与此子路由匹配 # 它们是按产品和环境分组的,而不是集群 - receiver: ‘frontend-pager‘ group_by: [product, environment] match: team: frontend
group_by:报警分组依据
group_wait:为一个组发送通知的初始等待时间,默认30s
group_interval:在发送新告警前的等待时间。通常5m或以上
repeat_interval:发送重复告警的周期。如果已经发送了通知,再次发送之前需要等待多长时间。通常3小时或以上
主要处理流程:
告警面临最大问题,是警报太多,相当于狼来了的形式。收件人很容易麻木,不再继续理会。关键的告警常常被淹没。在一问题中,alertmanger在一定程度上得到很好解决。
Prometheus成功的把一条告警发给了Altermanager,而Altermanager并不是简简单单的直接发送出去,这样就会导致告警信息过多,重要告警被淹没。所以需要对告警做合理的收敛。
告警收敛手段:
分组(group):将类似性质的警报分类为单个通知
抑制(Inhibition):当警报发出后,停止重复发送由此警报引发的其他警报
静默(Silences):是一种简单的特定时间静音提醒的机制
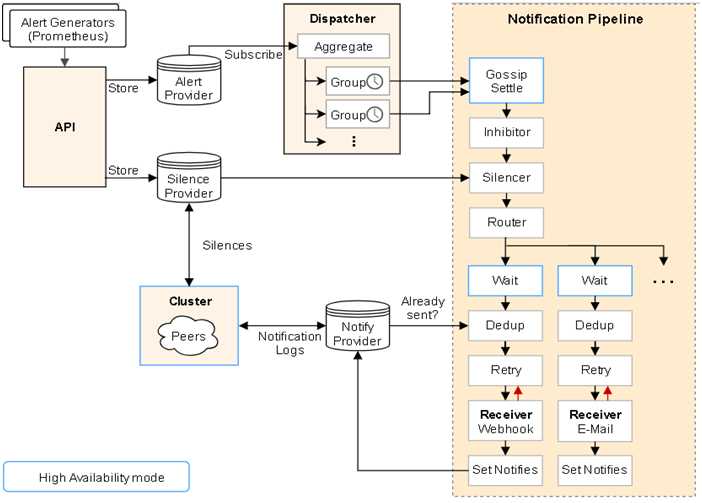
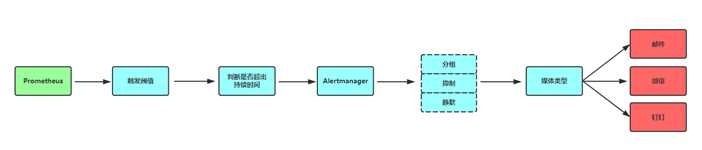
报警处理流程如下:
# cat rules/general.yml groups: - name: general.rules rules: - alert: InstanceDown expr: up == 0 for: 2m labels: severity: error annotations: summary: "Instance {{ $labels.instance }} 停止工作" description: "{{ $labels.instance }}: job {{ $labels.job }} 已经停止5分钟以上." # cat rules/node.yml groups: - name: node.rules rules: - alert: NodeFilesystemUsage expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80 for: 2m labels: severity: warning annotations: summary: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用过高" description: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用大于 80% (当前值: {{ $value }})" - alert: NodeMemoryUsage expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80 for: 2m labels: severity: warning annotations: summary: "{{$labels.instance}}: 内存使用过高" description: "{{$labels.instance}}: 内存使用大于 80% (当前值: {{ $value }})" - alert: NodeCPUUsage expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80 for: 2m labels: severity: warning annotations: summary: "{{$labels.instance}}: CPU使用过高" description: "{{$labels.instance}}: CPU使用大于 80% (当前值: {{ $value }})" # cat rules/reload.yml groups: - name: prometheus.rules rules: - alert: AlertmanagerReloadFailed expr: alertmanager_config_last_reload_successful == 0 for: 10m labels: severity: warning annotations: summary: "{{$labels.instance}}: Alertmanager配置重新加载失败" description: "{{$labels.instance}}: Alertmanager配置重新加载失败" - alert: PrometheusReloadFailed expr: prometheus_config_last_reload_successful == 0 for: 10m labels: severity: warning annotations: summary: "{{$labels.instance}}: Prometheus配置重新加载失败" description: "{{$labels.instance}}: Prometheus配置重新加载失败"
标签:dashboard 复数 操作方法 描述 lin 扩展 mon 响应 resolve
原文地址:https://www.cnblogs.com/yuezhimi/p/11056819.html