标签:form override 随机 技术 rdd 创建 vat 一个 foreach
在spark中,框架默认使用的事hashPartitioner分区器进行对rdd分区,但是实际生产中,往往使用spark自带的分区器会产生数据倾斜等原因,这个时候就需要我们自定义分区,按照我们指定的字段进行分区。具体的流程步骤如下:
1、创建一个自定义的分区类,并继承Partitioner,注意这个partitioner是spark的partitioner
2、重写partitioner中的方法
override def numPartitions: Int = ???
override def getPartition(key: Any): Int = ???
代码实现:
测试数据集:
cookieid,createtime,pv cookie1,2015-04-10,1 cookie1,2015-04-11,5 cookie1,2015-04-12,7 cookie1,2015-04-13,3 cookie1,2015-04-14,2 cookie1,2015-04-15,4 cookie1,2015-04-16,4 cookie2,2015-04-10,2 cookie2,2015-04-11,3 cookie2,2015-04-12,5 cookie2,2015-04-13,6 cookie2,2015-04-14,3 cookie2,2015-04-15,9 cookie2,2015-04-16,7
指定按照第一个字段进行分区
步骤1:
package _core.sourceCodeLearning.partitioner
import org.apache.spark.Partitioner
import scala.collection.mutable.HashMap
/**
* Author Mr. Guo
* Create 2019/6/23 - 12:19
*/
class UDFPartitioner(args: Array[String]) extends Partitioner {
private val partitionMap: HashMap[String, Int] = new HashMap[String, Int]()
var parId = 0
for (arg <- args) {
if (!partitionMap.contains(arg)) {
partitionMap(arg) = parId
parId += 1
}
}
override def numPartitions: Int = partitionMap.valuesIterator.length
override def getPartition(key: Any): Int = {
val keys: String = key.asInstanceOf[String]
val sub = keys
partitionMap(sub)
}
}
步骤2:
主类测试:
package _core.sourceCodeLearning.partitioner
import org.apache.spark.{SparkConf, TaskContext}
import org.apache.spark.sql.SparkSession
/**
* Author Mr. Guo
* Create 2019/6/23 - 12:21
*/
object UDFPartitionerMain {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName)
val ssc = SparkSession
.builder()
.config(conf)
.getOrCreate()
val sc = ssc.sparkContext
sc.setLogLevel("WARN")
val rdd = ssc.sparkContext.textFile("file:///E:\\TestFile\\analyfuncdata.txt")
val transform = rdd.filter(_.split(",").length == 3).map(x => {
val arr = x.split(",")
(arr(0), (arr(1), arr(2)))
})
val keys: Array[String] = transform.map(_._1).collect()
val partiion = transform.partitionBy(new UDFPartitioner(keys))
partiion.foreachPartition(iter => {
println(s"**********分区号:${TaskContext.getPartitionId()}***************")
iter.foreach(r => {
println(s"分区:${TaskContext.getPartitionId()}###" + r._1 + "\t" + r._2 + "::" + r._2._1)
})
})
ssc.stop()
}
}
运行结果:
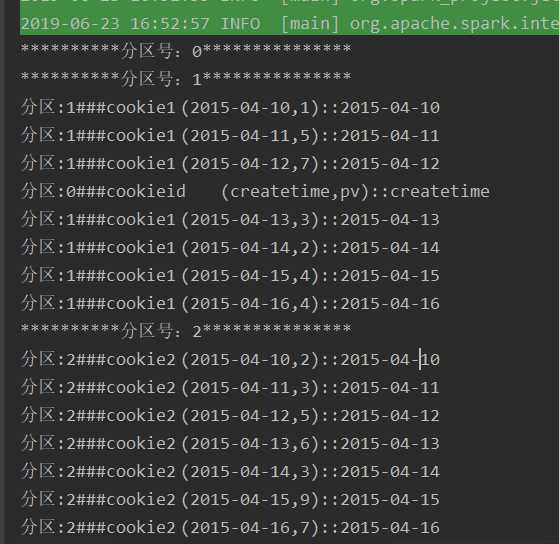
这样就是按照第一个字段进行了分区,当然在分区器的中,对于key是可以根据自己的需求随意的处理,比如添加随机数等等
标签:form override 随机 技术 rdd 创建 vat 一个 foreach
原文地址:https://www.cnblogs.com/Gxiaobai/p/11073381.html