标签:sam 应用 获得 函数 降维算法 排列 输入 合并 png
一、 高维数据降维
高维数据降维是指采取某种映射方法,降低随机变量的数量。例如将数据点从高维空间映射到低维空间中,从而实现维度减少。降维分为特征选择和特征提取两类,前者是从含有冗余信息以及噪声信息的数据中找出主要变量,后者是去掉原来数据,生成新的变量,可以寻找数据内部的本质结构特征。
简要来说,就是通过对输入的原始数据的特征学习,得到一个映射函数,实现将输入样本映射后到低维空间中,其原始数据的特征并没有明显损失。通常新空间的维度要小于原空间的维度。目前大部分降维算法是处理向量形式的数据。
二、 主成分分析过程
主成分分析(Principal Component Analysis,PCA)是一种最常用的线性降维方法,目标是通过某种线性投影,将高维数据映射到低维空间中,并期望在所投影的维度上数据的方差最大。PCA的降维是指经过正交变换后,形成新的特征集合,然后从中选择比较重要的一部分子特征集合,从而实现降维。这种方式并非是在原始特征中选择,所以PCA极大程度保留了原有的样本特征。
关于PCA降维原理,请参考http://blog.codinglabs.org/articles/pca-tutorial.html
PCA降维的一般过程:
设有 m 条 n 维的数据。
① 将原始数据按列组成n行m列矩阵X;
② 计算矩阵 X 中每个特征属性(n 维)的平均向量M(平均值);
③ 将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值M;
④ 求出协方差矩阵![]() ;
;
⑤ 求出协方差矩阵的特征值及对应的特征向量;
⑥ 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k(k<n)行组成基向量P;
⑦ Y=PX即为降维到k维后的数据;
PCA目标是求出样本数据的协方差矩阵的特征值和特征向量,而协方差矩阵的特征向量的方向就是PCA需要投影的方向。使用样本数据向低维投影后,能尽可能的表征原始的数据。协方差矩阵可以用散布矩阵代替,即协方差矩阵*(n-1),其中n为样本的数量。
三、 案例演示
mu_vec1 = np.array([0,0,0]) cov_mat1 = np.array([[1,0,0],[0,1,0],[0,0,1]]) class1_sample = np.random.multivariate_normal(mu_vec1, cov_mat1, 20).T mu_vec2 = np.array([1,1,1]) cov_mat2 = np.array([[1,0,0],[0,1,0],[0,0,1]]) class2_sample = np.random.multivariate_normal(mu_vec2, cov_mat2, 20).T
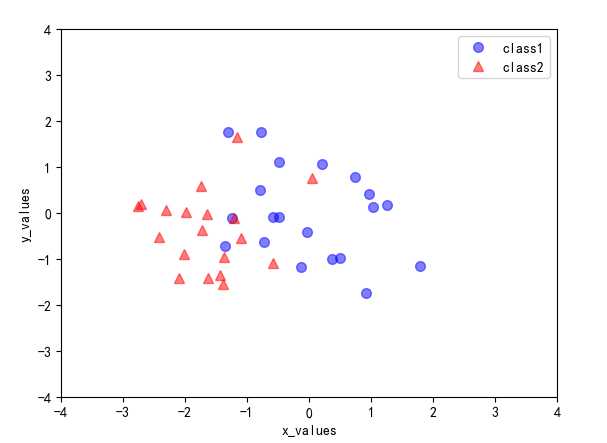
其中,multivariate_normal()生成多元正态样本分布,参数分别为设定的样本均值向量,协方差矩阵,每个类别数量为20个。生成的两个类别class1_sample和class2_sample为三维样本数据,即样本数据的特征数量为3个。可视化结果如下:
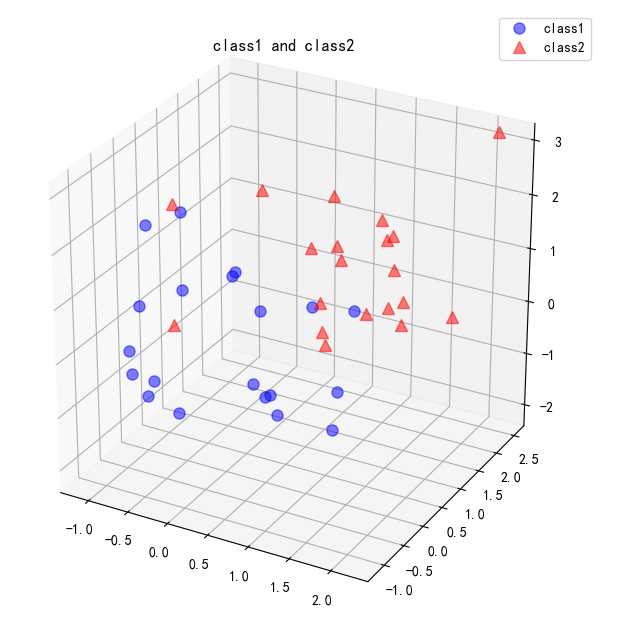
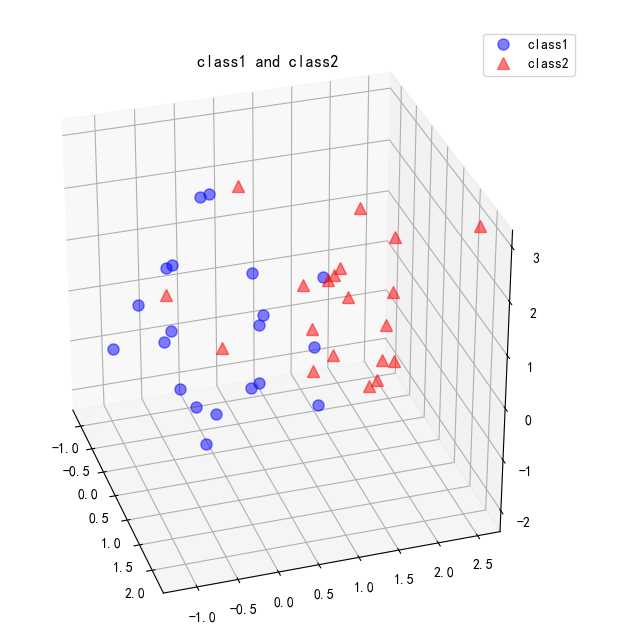
2. 下面利用PCA将其投射到二维空间,查看其分布情况。计算40个点在3个维度上的平均向量,首先将两个类别的数据合并到all_samples中,然后计算平均向量:
all_samples = np.concatenate((class1_sample, class2_sample), axis=1) mean_x = np.mean(all_samples[0,:]) mean_y = np.mean(all_samples[1,:]) mean_z = np.mean(all_samples[2,:])
计算平均向量mean_x,mean_y,mean_z,然后基于平均向量计算散布矩阵,方法如下: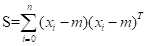 ,其中m为计算的平均向量;所有向量与m的差值经过点积并求和后即可获得散布矩阵的值:
,其中m为计算的平均向量;所有向量与m的差值经过点积并求和后即可获得散布矩阵的值:
scatter_matrix = np.zeros((3,3)) for i in range(all_samples.shape[1]): scatter_matrix += (all_samples[:,i].reshape(3,1) - mean_vector).dot((all_samples[:,i].reshape(3,1) - mean_vector).T)
应用numpy库内置的np.linalg.eig(scatter_matrix)方法计算特征向量和特征值。此外,也可以利用numpy.cov()方法计算协方差矩阵求解:
# 由散布矩阵得到特征向量和特征值 eig_val_sc, eig_vec_sc = np.linalg.eig(scatter_matrix) # 由协方差矩阵得到特征向量和特征值 eig_val_cov, eig_vec_cov = np.linalg.eig(cov_mat)
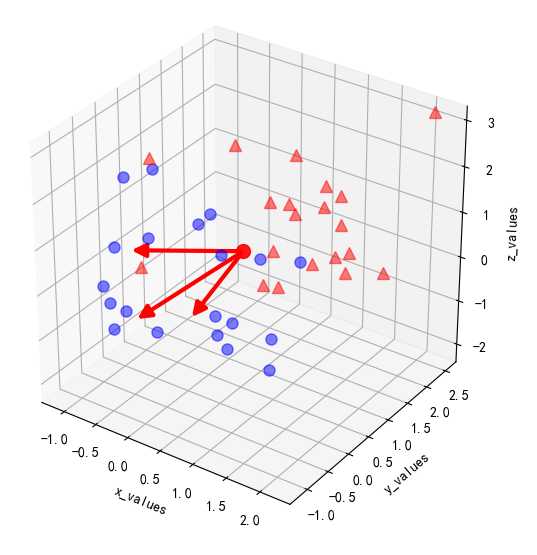
得到3个维度的特征值(eig_vec_sc)和3个维度的特征向量(eig_val_sc)。以平均向量为起点,绘出特征向量,可以看到特征向量的方向,这个方向确定了要进行转化的新特征空间的坐标系。结果如下:
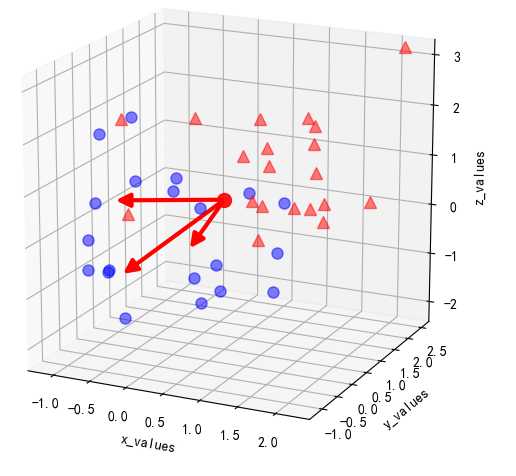
3. 按照特征值和特征向量进行配对,并按照特征值的大小从高到低进行排序,由于需要将三维空间投射到二维空间中,选择前两个特征值-特征向量作为坐标,并构建2*3的特征向量矩阵W 。原来空间的样本通过与此矩阵相乘,使用公式:的方法将所有样本转换到新的空间中。结果如下:
4.结论:
这种变换并没有改变各样本之间的关系,只是应用了新的坐标系。在本例中是将三维空间降维到二维空间,如果有一个n 维的数据,想要降到k维,则取前k个特征值对应的特征向量即可。
缺点:当数据量和数据维度非常大的时候,用协方差矩阵的方法解PCA会变得很低效。解决办法是使用奇异值分解(SVD)。
标签:sam 应用 获得 函数 降维算法 排列 输入 合并 png
原文地址:https://www.cnblogs.com/wyr-123-wky/p/11080408.html