标签:无限循环 生产 log 压力 service 公司 city 做了 云主机
记录一个项目的技术实现,主要谈这个项目的大请求的高并发处理这一块。这个项目最终通过多种技术组合,达到削峰填谷地秒级分布式计算大请求的能力,且各服务/接口间的熔断和自动恢复避免了某1个挂起的服务使得其他服务挂起的单点故障。这个项目申请了多份专利
其实项目整体的技术选型本身是一次很有意思的经历,里面有太多的故事(技术访谈、技术调研、多套方案的POC、小组讨论、确认技术选型、异地出差做项目调研、跨部门确认技术选型、向各技术部门领导通报技术可行性研究、协助兄弟部门技术提升等),最有意思的是兄弟部门架构师(已离职)的一席话:这个项目已经好多波人找我调研了,其实有方案一直不能落地,希望你们能搞定!当时,我的头顶有几只乌鸦飞过……。几百人IT团队的架构师都推不动,我们能量有那么大吗。最后生产实践证明:相比之下,我们的方案更加轻快、更加流程化、更加既见既所得、且一处配置处处一致
为了控制文章的篇幅,此文只说明大请求高并发的技术实现方案
服务 = 请求持久化 + 分布式计算 + MQ异步通知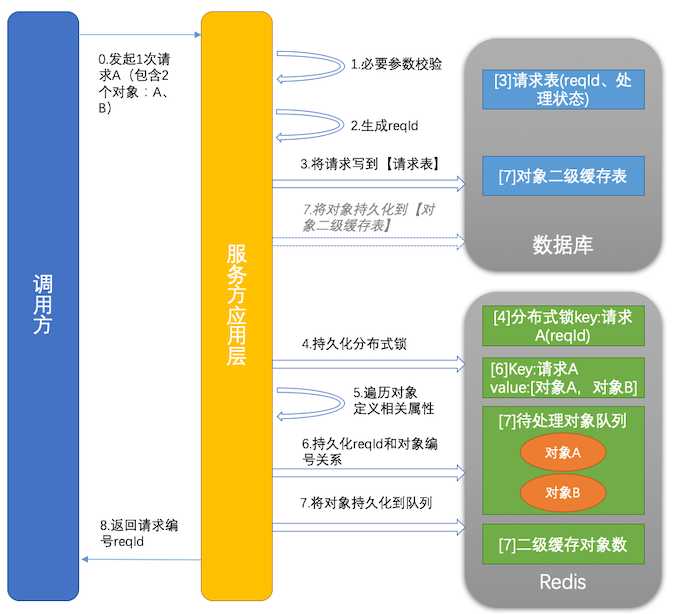
其他说明:
Redis读的速度是11万次/s,写的速度是8.1万次/s。每1次写的速度小于0.0125毫秒,如果把应用层和Redis之间的网络消耗算在内,最大应该是1个毫秒级。如果1次请求有10个对象的持久化,最大也就是10个毫秒左右。加上Oracle的1次请求(不是请求里的对象)的持久化时间,整个持久化时间大概20~50ms左右,调用方可以快速得到reqId
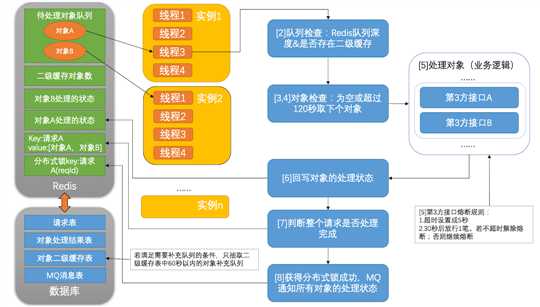
汇总一下之前小伙伴的疑问:
分别对1次业务请求的n个对象,发起n次请求?
不行。1次请求拆成n次Http请求调用,每次调用又带着300~700K的图片的话,在高并发下,千兆网卡可能吃不消(何况很多实例都是虚拟化的,多台实例共用同1台物理机器,多台实例共用同1张网卡,更会加重这种影响)。我的猜想没有错:有一次UIOC事件(其他兄弟的另1个项目)就是因为并发过高,网卡挂起,网卡间断性的发网络请求
用MQ的方式通知集群处理业务请求?
不行。 集团的1条MQ消息,容量最大是128K,而请求中的图片就有300~600K
同步接口来处理业务请求?
不行。1个对象的处理时间若是700ms,1个请求的10个对象的处理时间是7秒,超出了1个请求2秒得到结果的要求
同步接口 + ExecutorService线程池并行处理业务请求里的各个对象?
不行。主要是两个方面:
1)由于涉及PDF流的运算,会消耗大量内存,为了不影响其他的业务逻辑的运行,必须限定线程池的个数和队列深度。若不限定,那么大的图片存储在内存中很快会OOM
2)在高并发下,线程数和队列深度一旦限定,有些请求因达到线程池的限制会被直接拒绝。同时,同1个请求10+左右的对象,可能会分m批运行(m=10/线程数),若每批运行时间是700ms,会有超过整个请求的处理时间在2秒内的限制的可能
这个项目为什么一定要用异步接口呢?
作为服务方,尽量不成为公司整个业务流程的性能瓶颈节点。 调用方与服务方的网络连接越快结束越好,避免服务方运算速度变慢(比如YGC、OGC、FGC、系统中其他耗性能的功能running中等),而导致调用方HTTP连接的等待,如果此时调用方没有配置超时时间,会发生灾难性的贯穿性的雪崩效应。同时鉴于单个对象的处理链条长,PDF流运算较耗性能,如果几千个对象同时同步的在服务方处理,服务方必然会资源耗尽。所以这个项目需要通过异步队列的形式,削峰填谷
不考虑用MongoDB来替代Oracle的写操作?
有考虑过,不过这个项目所属的系统没有MongoDB,需要预算审批。如果替代过后的好处:
1)减轻Oracle的写压力
2)由于磁盘以bson存储,易于扩展监控类字段
3)通过MongoDB优秀的写性能,可以减少单个对象的处理时间
由于1次请求整体响应时间在1秒左右,已经达到5秒内的要求,性能过得去,所以没有申请这笔预算
为什么不直接将对象持久化到Redis中,而要用数据库做二级缓存呢?
主要是担心海量并发时,Redis的队列深度不控制,会将Redis撑爆。毕竟为了读写效率,每个对象都会存储300~700K的图片。如果1个请求有10个对象,则会存7M,48G的Redis总共存储7021个请求,若按照300tps且来不及消费Redis队列的话,最快23秒就会将Redis爆掉。因此,队列深度是2000的话,最大占用Redis容量是1.3G=2000*700/1024/1024
为什么每台实例只开启4个线程?
当时测试环境压测的主要的环境指标:申请和生产环境同样的CPU和内存,每次压测的处理对象一样。线程数从1配置到10,主要考核2个核心指标:每秒处理的对象数、每个对象处理的耗时。不难看出这2个指标是互为倒数关系,数学上分别是直线和双曲线,他们一定在第一象限有个交点,这个交点就是4。4个线程时,这两个指标是最好的。其实也不难理解,在内存足够的情况下,影响线程性能的就是CPU,而服务器的CPU是四核的,每个核处理1个用户线程是最佳的
为什么Redis队列里的对象超过120秒后丢弃?二级缓存只取60秒内的数据?
1)文中提到的各种阈值,它们之间是有联系的,是通过计算得到的。比如:这里的60、120:队列深度(2000)低于50%时,取1000个对象补充;而每个对象120秒就会被丢弃,所以只用取60秒内的数据;当然这也和集群中的实例数有关。因每家公司集群环境不一样,阈值配置的具体值不深入讨论
2) 对象之所以要有过期时间而被丢弃,主要是为了当数据积压发生时(队列生产者的生产的速度比消费者消费的速度快),避免新的请求迟迟得不到消费
3) 生产事件:截止到2019.06,这种情况生产环境一共出现3次,第1次出现这个情况时没有这个特性,运维同事又迟迟没有Redis的操作权限,也不敢flush数据导致加重了业务影响----集群一直消费很早之前(半小时、1个小时之前)的请求。其实这个超时丢弃的特性早已报备并计划上线,只不过计划赶不上变化。第2、3次出现这个情况时,因为有了这个特性,集群进行了自我修复,基本无感知。至于这3次情况产生的根源性原因各不相同,都不是因我们的服务自身而起,虽不是我们的锅,但毕竟我们可以做到更好,减轻别人黑锅对我们的影响,你说呢?
丢弃的对象后面会补偿处理吗?
不会,业务上不需要。调用我们服务的属于App交互类的请求,接口上保持幂等性即可
标签:无限循环 生产 log 压力 service 公司 city 做了 云主机
原文地址:https://www.cnblogs.com/jacobus/p/11087250.html