标签:Lucene style blog http io ar java sp 文件
前言
系统一大,就会拆分成多个独立的进程,比如web+wcf/web api等,也就成了分布式系统。
要看一个请求怎么从头到尾走的,就有些困难了,要是进行DEBUG、跟踪,就更加麻烦了,困难程度要视进程多少而定,越多越复杂。
分布式日志收集系统就登场了。
今天介绍一款
全开源日志收集、展示系统 - logstash(基于java)+kibana(基于JRuby, logstash已自带)+ElasticSearch+RabbitMQ
架构图如下
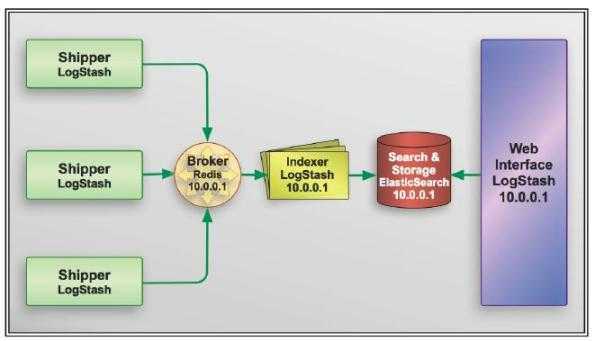
这张图是拷贝来的
安装方法
略,baidu一下一堆一堆的,注意的地方就一个:Kibana已经在logstash最新版中自带了,不用再去单独下载kibana代码,直接运行logstash web即可
正文
本文采用的logstash input类型为file的输入,既通过检测文本文件的方式进行日志采集(logstash支持很多input,文本文件只是其中一种,具体请看上面的文档url)
我们假设目前日志文件log.txt中存在一行日志记录,比如:
[192.168.1.1][2014-10-22 23:59:00][ERROR][Page1.Page_Load]Null Exception, bal...bal...
此时logstash shipper会根据它的配置文件找到这个log.txt, 然后检测到有一个新行出现了,内容是上面这些,然后它会:
RabbitMQ实际上是起到了缓冲消峰的作用
那么RabbitMQ的消息是要给到谁呢?它是logstash indexer,logstash indexer实际上很简单,只是接收MQ中的消息,然后发送到再后端的ES倒排序引擎
然后就到了最后一个Kibana Web查询控制台,开发人员最终是通过这个Kibana查询界面来查询logstash收集来的日志的,下面来说说Kibana
Kibana的数据来源:
ElasticSearch:支持分布式扩展的倒排序搜索引擎,内核基于Lucene
Kibana的查询界面自定义:
可以灵活变换显示的列
可以鼠标圈时间范围(根据时间段来查看日志列表)
可以自动刷新日志列表
可以自定义所监控日志的版本(如:生产系统、UAT系统、开发DEMO)
可以查看某段时间段内某字段的饼图等统计图
可以灵活排序
可以定义列的显示前后位置
可以定义列是否显示
上一张图看看样子吧
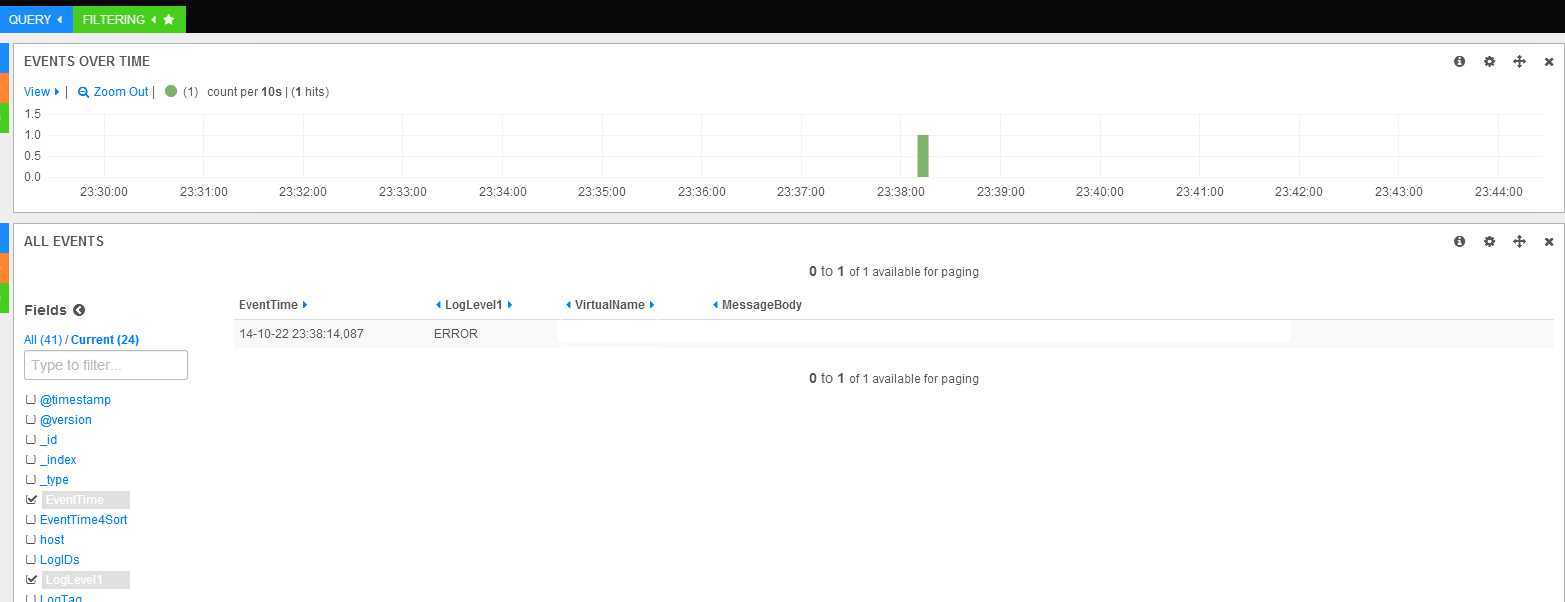
整个收集系统的搭建,除了logstash这一套组件的搭建外,还需要关注的地方是日志文件保存的格式,就是上面包含有中括号的那种一行一行的记录是以什么格式保存,因为这个格式会对应logstash参数的解析,而logstash参数的名称会映射到kibana的查询界面中。
在程序这边,需要关注的是用统一的日志记录函数来记录,这样文本文件内容的格式就保证了,整个闭环就形成了。
具体的配置方式,大家可以加入一些logstash的qq群,或者看本文开头提供的文档链接。
DONE.
标签:Lucene style blog http io ar java sp 文件
原文地址:http://www.cnblogs.com/aarond/p/logstash.html