标签:调用 编译 target store 必须 line 扩展 位置 called
参考文献:
https://en.wikipedia.org/wiki/Buffer_overflow_protection
https://www.zhihu.com/question/20871464/answer/18743160
http://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/
《黑客攻防技术宝典-系统实战》
.....................................................................................
首先我们直接看一段栈空间溢出的代码:
1 |
void bob(){ |
在gcc version 5.4.0 x86_64 Ubuntu 16.04.1 LTS环境下进行编译:
编译选项:g++ test.cpp -fno-stack-protector
下面是bob()函数的反汇编代码
1 |
00000000004004d6 <_Z3bobv>: |
编译选项:g++ test.cpp (默认含有-fstack-protector-strong选项)
下面是bob()函数的反汇编代码
1 |
0000000000400546 <_Z3bobv>: |
在有stack-protector-strong选项的情况下,bob()函数多出来部分,是gcc为了进行栈空间溢出检测而插入的代码。在解析堆栈保护之前,先解析一下上述汇编代码中,关于堆栈对齐的部分。
我们看看在含有-fstack-protector-strong编译选项下,bob()函数的反汇编代码的前三行:
1 |
0000000000400546 <_Z3bobv>: |
为什么这里申请了32bytes的栈空间呢,代码段中,只需要16bytes的数组空间呀。
因为增加了stack-protector,gcc为了进行栈空间溢出检测而插入了一个guard word字段,也就是canary word,该字段为8bytes。该字段在栈空间溢出后会被破坏(这里不是一定的,后面会详解),在函数结束时会校验该字段来判断是否发生栈溢出。
局部变量16bytes + canary word 8bytes = 24bytes < 32 bytes.
why? 为什么会多出来8个字节呢,这里就是GCC默认16bytes栈对齐的原因。
为什么默认是16bytes对齐呢,这和CPU相关,
Intel在Pentium III推出了SSE指令集,SSE 加入新的 8 个128Bit(16bytes)寄存器(XMM0~XMM7)。最初的时候,这些寄存器智能用来做单精度浮点数计算,自从SSE2开始,这些寄存器可以被用来计算任何基本数据类型的数据了。往XMM0~XMM7里存放数据,是以16字节为单位,所以呢 内存变量首地址必须要对齐16字节,否则会引起CPU异常,导致指令执行失败。所以这就是gcc默认采用16bytes进行栈对齐的原因。
感谢miloyip指出这里的问题:这里关于SSE指令, aligned/unaligned 的 load/store 指令,unaligned 是不会有问题的,具体16bytes对齐的原因有待商榷。。。
gcc中关于栈对齐的选项是-mpreferred-stack-boundary=num,栈空间的边界对齐为2的num次幂。该选项默认值是4,即16bytes
gcc 5.4 manual中关于该选项说明如下:
Warning: When generating code for the x86-64 architecture with SSE extensions disabled, ‘-mpreferred-stack-boundary=3’ can be used to keep the stack boundary aligned to 8 byte boundary. Since x86-64 ABI require 16 byte stack alignment, this is ABI incompatible and intended to be used in controlled environment where stack space is important limitation. This option leads to wrong code when functions compiled with 16 byte stack alignment (such as functions from a standard library) are called with misaligned stack. In this case, SSE instructions may lead to misaligned memory access traps. In addition, variable arguments are handled incorrectly for 16 byte aligned objects (including x87 long double and int128), leading to wrong results. You must build all modules with ‘-mpreferred-stack-boundary=3’, including any libraries. This includes the system libraries and startup modules.
简述就是:在SSE扩展被关闭时,-mpreferred-stack-boundary参数值是可以修改的。但是,但是,但是,当该选项值被修改后,编译链接16bytes栈对齐的库时,会导致错误。
下面修改栈对齐参数为8bytes后bob()函数的反汇编代码:
g++ test.cpp -mpreferred-stack-boundary=3 -mno-sse
1 |
0000000000400546 <_Z3bobv>: |
和默认16bytes栈对齐的反汇编代码区别:8bytes对齐的栈空间预留了0x18=24bytes的空间。
这里抛一个问题:8bytes栈对齐的这段代码运行的时候会core掉,而16bytes栈对齐的不会,为什么?(后面出讲到,也是本文的核心)
上面bob()函数的栈空间布局如下: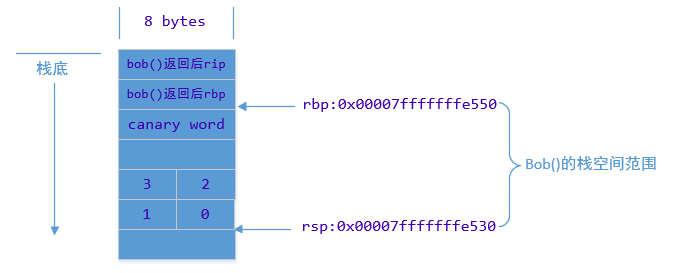
关于函数栈16bytes对齐还有一点想要阐述的:每当通过call指令进行函数调用时,都会发生两个操作:
上面两步操作是进程运行的关键,也是我认为最最基础的,这两步是理解程序运行过程的关键。写了这么多年代码,终于感觉入门了。。。
上面两步在x84_64下,会发现始终让栈空间保持16bytes的对齐,是不是很神奇。。。
下面我们回归正题,gcc是如何进行栈空间溢出检测的。
<GCC 中的编译器堆栈保护技术>这篇文章介绍了gcc采用的堆栈保护技术,堆栈保护基本都是通过canaries探测来实现的,Canaries探测要检测对函数栈的破坏,需要修改函数栈的组织, 要在缓冲区和控制信息(压在栈中的函数返回后的RBP和RIP)中间插一个canary word,这样当缓冲区被破坏的时候,canary word会在函数栈控制信息被破坏之前被破坏,这样通过检测canary word的值是否被修改,就可以判断出是否发生溢出攻击。
这里对于一次接触Canaries这个词的人,可能会很困惑,维基中关于缓冲区溢出中有相关介绍:
“The terminology is a reference to the historic practice of using canaries in coal mines, since they would be affected by toxic gases earlier than the miners, thus providing a biological warning system”
本人译:Canary,原意是金丝雀,该术语来源于挖矿行业,用金丝雀来检查煤矿中的空气是否有毒。
GCC 4.1 堆栈保护才被加入,所采用的堆栈保护实现Stack-smashing Protection(SSP,又称 ProPolice)。到目前GCC6.2中与堆栈保护有关的编译选项,有如下几个:
开启stack-protector后,会在函数栈的数据和控制信息直接预留多余的缓冲区,然后会在缓冲区的最后一个word(8bytes),其实gcc本意该缓冲区的大小就是8 bytes,即够写入一个canary word的,但实际你会发现缓冲区比8个字节要大。这里的原因就是上面一节讲述的栈空间对齐的结果:
实际缓冲区大小 = 栈空间对齐后的栈大小 – 局部变量占用的栈大小
而且gcc会把canary word写入到栈缓冲区最高的位置,即紧挨着上一个调用函数的rbp栈底指针存放的位置。
所以回到最开始的栈溢出的代码,下面是bob()函数在-fstack-protector-strong选项或者-fstack-protector-all选项下的反汇编代码
1 |
0000000000400546 <_Z3bobv>: |
bob()函数栈空间的大小对32字节,栈上局部数组使用了16bytes,多出来的16bytes缓冲区其中8bytes用于canaries溢出检测。另外多出来的8bytes,只是栈对齐的原因预留下来的。所以在这种情况下,溢出写入8bytes的数据都不会对代码有任何影响。下图是bob()函数执行完时,栈的情况: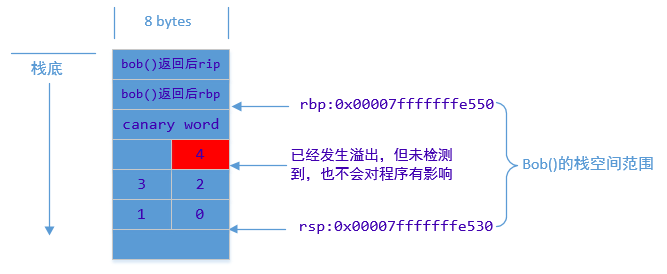
如果溢出写入超过8bytes,覆盖到canary word,就是触发gcc的Stack-smashing Protection,出现如下异常:
1 |
void bob(){ |
其实本文的核心就是这一点,gcc通过cannary word来进行栈溢出检测,这也是上一节提出的问题的答案,在栈空间8字节对齐情况下,代码coredump的原因也是cannary word被覆盖了。
下面上面已经说到gcc关于栈溢出检测的几个参数,可能比较乱,这里汇总一下: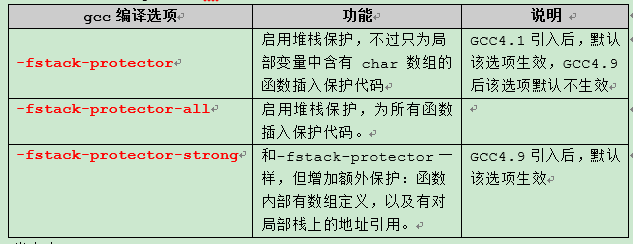
本文的实例代码bob()函数之所以被插入栈保护代码,就是因为在默认-fstack-protector-strong,bob()函数有数组定义。如果该代码在gcc4.9之前的版本编译,且不加-fstack-protector-all选项,是不会生成保护代码的。
如下是在gcc version 4.8.4 ubuntu1~14.04.3 x86_64下编译的bob()函数的反汇编代码,等同于 -fno-stack-protector
1 |
00000000004004ed <_Z3bob>: |
这里由于没有插入溢出检测代码,所以bob()函数栈空间没有进行16bytes倍数的栈对齐预留。因为该函数调用完毕就会返回,因为没有进行预留,所以你就会发现数组溢出写入的字段,已经覆盖了返回函数栈的rbp栈底指针,如下图: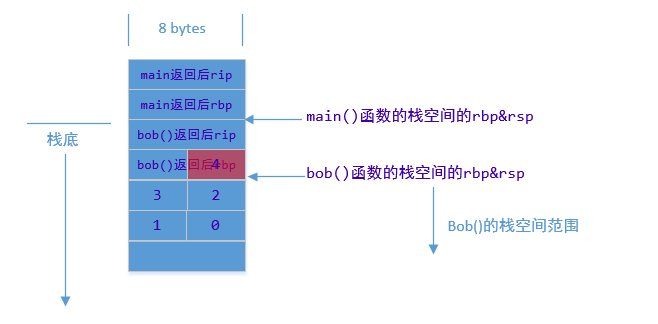
哎呦,完了,程序要跪了,我们执行一下,结果你会发现,并没有挂掉:我们看看上一个函数main函数的汇编代码:
1 |
0000000000400516 <main>: |
你会发现,bob()结束时,pop出来被覆盖了的rbp寄存器的值,在main函数中并没有被使用,main中结尾直接pop出了上一层函数的rbp寄存器的值,所已这个溢出问题并没有导致代码coredump。当修改main()中的代码,填加一个变量后:
1 |
void bob(){ |
在上面gcc4.8.4环境下同样编译,你就会发现,该代码会coredump。
main()汇编代码如下:
1 |
0000000000400516 <main>: |
leaveq等同于:
1 |
mov %rbp %rsp |
我们知道rbp寄存器的值已经是被覆盖了的错误地址。所以,把他赋值给rsp后,栈顶指针就是一个错误的指向,再去执行pop指令,就会导致异常。
讲了这么多,其实一开始就只是想研究一个GCC的栈溢出检测机制,结果发现自己知之甚少,就从编译选项,研究到栈空间对齐,最终对程序的运行过程从汇编的角度又是深入了几分。
所以本文彻底解除了我多年的困惑:数组越界,为什么有时候会coredump,有时候不会coredump,这个gcc编译器的环境,以及os都有着莫大的关系。
首先我们直接看一段栈空间溢出的代码:
1 |
void bob(){ |
在gcc version 5.4.0 x86_64 Ubuntu 16.04.1 LTS环境下进行编译:
编译选项:g++ test.cpp -fno-stack-protector
下面是bob()函数的反汇编代码
1 |
00000000004004d6 <_Z3bobv>: |
编译选项:g++ test.cpp (默认含有-fstack-protector-strong选项)
下面是bob()函数的反汇编代码
1 |
0000000000400546 <_Z3bobv>: |
在有stack-protector-strong选项的情况下,bob()函数多出来部分,是gcc为了进行栈空间溢出检测而插入的代码。在解析堆栈保护之前,先解析一下上述汇编代码中,关于堆栈对齐的部分。
我们看看在含有-fstack-protector-strong编译选项下,bob()函数的反汇编代码的前三行:
1 |
0000000000400546 <_Z3bobv>: |
为什么这里申请了32bytes的栈空间呢,代码段中,只需要16bytes的数组空间呀。
因为增加了stack-protector,gcc为了进行栈空间溢出检测而插入了一个guard word字段,也就是canary word,该字段为8bytes。该字段在栈空间溢出后会被破坏(这里不是一定的,后面会详解),在函数结束时会校验该字段来判断是否发生栈溢出。
局部变量16bytes + canary word 8bytes = 24bytes < 32 bytes.
why? 为什么会多出来8个字节呢,这里就是GCC默认16bytes栈对齐的原因。
为什么默认是16bytes对齐呢,这和CPU相关,
Intel在Pentium III推出了SSE指令集,SSE 加入新的 8 个128Bit(16bytes)寄存器(XMM0~XMM7)。最初的时候,这些寄存器智能用来做单精度浮点数计算,自从SSE2开始,这些寄存器可以被用来计算任何基本数据类型的数据了。往XMM0~XMM7里存放数据,是以16字节为单位,所以呢 内存变量首地址必须要对齐16字节,否则会引起CPU异常,导致指令执行失败。所以这就是gcc默认采用16bytes进行栈对齐的原因。
感谢miloyip指出这里的问题:这里关于SSE指令, aligned/unaligned 的 load/store 指令,unaligned 是不会有问题的,具体16bytes对齐的原因有待商榷。。。
gcc中关于栈对齐的选项是-mpreferred-stack-boundary=num,栈空间的边界对齐为2的num次幂。该选项默认值是4,即16bytes
gcc 5.4 manual中关于该选项说明如下:
Warning: When generating code for the x86-64 architecture with SSE extensions disabled, ‘-mpreferred-stack-boundary=3’ can be used to keep the stack boundary aligned to 8 byte boundary. Since x86-64 ABI require 16 byte stack alignment, this is ABI incompatible and intended to be used in controlled environment where stack space is important limitation. This option leads to wrong code when functions compiled with 16 byte stack alignment (such as functions from a standard library) are called with misaligned stack. In this case, SSE instructions may lead to misaligned memory access traps. In addition, variable arguments are handled incorrectly for 16 byte aligned objects (including x87 long double and int128), leading to wrong results. You must build all modules with ‘-mpreferred-stack-boundary=3’, including any libraries. This includes the system libraries and startup modules.
简述就是:在SSE扩展被关闭时,-mpreferred-stack-boundary参数值是可以修改的。但是,但是,但是,当该选项值被修改后,编译链接16bytes栈对齐的库时,会导致错误。
下面修改栈对齐参数为8bytes后bob()函数的反汇编代码:
g++ test.cpp -mpreferred-stack-boundary=3 -mno-sse
1 |
0000000000400546 <_Z3bobv>: |
和默认16bytes栈对齐的反汇编代码区别:8bytes对齐的栈空间预留了0x18=24bytes的空间。
这里抛一个问题:8bytes栈对齐的这段代码运行的时候会core掉,而16bytes栈对齐的不会,为什么?(后面出讲到,也是本文的核心)
上面bob()函数的栈空间布局如下:
关于函数栈16bytes对齐还有一点想要阐述的:每当通过call指令进行函数调用时,都会发生两个操作:
上面两步操作是进程运行的关键,也是我认为最最基础的,这两步是理解程序运行过程的关键。写了这么多年代码,终于感觉入门了。。。
上面两步在x84_64下,会发现始终让栈空间保持16bytes的对齐,是不是很神奇。。。
下面我们回归正题,gcc是如何进行栈空间溢出检测的。
<GCC 中的编译器堆栈保护技术>这篇文章介绍了gcc采用的堆栈保护技术,堆栈保护基本都是通过canaries探测来实现的,Canaries探测要检测对函数栈的破坏,需要修改函数栈的组织, 要在缓冲区和控制信息(压在栈中的函数返回后的RBP和RIP)中间插一个canary word,这样当缓冲区被破坏的时候,canary word会在函数栈控制信息被破坏之前被破坏,这样通过检测canary word的值是否被修改,就可以判断出是否发生溢出攻击。
这里对于一次接触Canaries这个词的人,可能会很困惑,维基中关于缓冲区溢出中有相关介绍:
“The terminology is a reference to the historic practice of using canaries in coal mines, since they would be affected by toxic gases earlier than the miners, thus providing a biological warning system”
本人译:Canary,原意是金丝雀,该术语来源于挖矿行业,用金丝雀来检查煤矿中的空气是否有毒。
GCC 4.1 堆栈保护才被加入,所采用的堆栈保护实现Stack-smashing Protection(SSP,又称 ProPolice)。到目前GCC6.2中与堆栈保护有关的编译选项,有如下几个:
开启stack-protector后,会在函数栈的数据和控制信息直接预留多余的缓冲区,然后会在缓冲区的最后一个word(8bytes),其实gcc本意该缓冲区的大小就是8 bytes,即够写入一个canary word的,但实际你会发现缓冲区比8个字节要大。这里的原因就是上面一节讲述的栈空间对齐的结果:
实际缓冲区大小 = 栈空间对齐后的栈大小 – 局部变量占用的栈大小
而且gcc会把canary word写入到栈缓冲区最高的位置,即紧挨着上一个调用函数的rbp栈底指针存放的位置。
所以回到最开始的栈溢出的代码,下面是bob()函数在-fstack-protector-strong选项或者-fstack-protector-all选项下的反汇编代码
1 |
0000000000400546 <_Z3bobv>: |
bob()函数栈空间的大小对32字节,栈上局部数组使用了16bytes,多出来的16bytes缓冲区其中8bytes用于canaries溢出检测。另外多出来的8bytes,只是栈对齐的原因预留下来的。所以在这种情况下,溢出写入8bytes的数据都不会对代码有任何影响。下图是bob()函数执行完时,栈的情况:
如果溢出写入超过8bytes,覆盖到canary word,就是触发gcc的Stack-smashing Protection,出现如下异常:
1 |
void bob(){ |
其实本文的核心就是这一点,gcc通过cannary word来进行栈溢出检测,这也是上一节提出的问题的答案,在栈空间8字节对齐情况下,代码coredump的原因也是cannary word被覆盖了。
下面上面已经说到gcc关于栈溢出检测的几个参数,可能比较乱,这里汇总一下:
本文的实例代码bob()函数之所以被插入栈保护代码,就是因为在默认-fstack-protector-strong,bob()函数有数组定义。如果该代码在gcc4.9之前的版本编译,且不加-fstack-protector-all选项,是不会生成保护代码的。
如下是在gcc version 4.8.4 ubuntu1~14.04.3 x86_64下编译的bob()函数的反汇编代码,等同于 -fno-stack-protector
1 |
00000000004004ed <_Z3bob>: |
这里由于没有插入溢出检测代码,所以bob()函数栈空间没有进行16bytes倍数的栈对齐预留。因为该函数调用完毕就会返回,因为没有进行预留,所以你就会发现数组溢出写入的字段,已经覆盖了返回函数栈的rbp栈底指针,如下图:
哎呦,完了,程序要跪了,我们执行一下,结果你会发现,并没有挂掉:我们看看上一个函数main函数的汇编代码:
1 |
0000000000400516 <main>: |
你会发现,bob()结束时,pop出来被覆盖了的rbp寄存器的值,在main函数中并没有被使用,main中结尾直接pop出了上一层函数的rbp寄存器的值,所已这个溢出问题并没有导致代码coredump。当修改main()中的代码,填加一个变量后:
1 |
void bob(){ |
在上面gcc4.8.4环境下同样编译,你就会发现,该代码会coredump。
main()汇编代码如下:
1 |
0000000000400516 <main>: |
leaveq等同于:
1 |
mov %rbp %rsp |
我们知道rbp寄存器的值已经是被覆盖了的错误地址。所以,把他赋值给rsp后,栈顶指针就是一个错误的指向,再去执行pop指令,就会导致异常。
讲了这么多,其实一开始就只是想研究一个GCC的栈溢出检测机制,结果发现自己知之甚少,就从编译选项,研究到栈空间对齐,最终对程序的运行过程从汇编的角度又是深入了几分。
所以本文彻底解除了我多年的困惑:数组越界,为什么有时候会coredump,有时候不会coredump,这个gcc编译器的环境,以及os都有着莫大的关系。
标签:调用 编译 target store 必须 line 扩展 位置 called
原文地址:https://www.cnblogs.com/mysky007/p/11105307.html